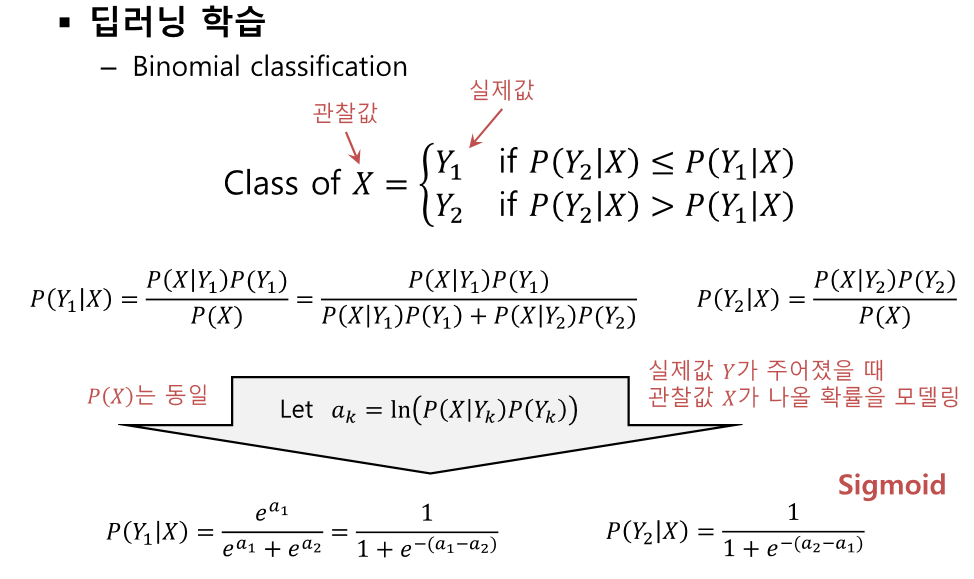
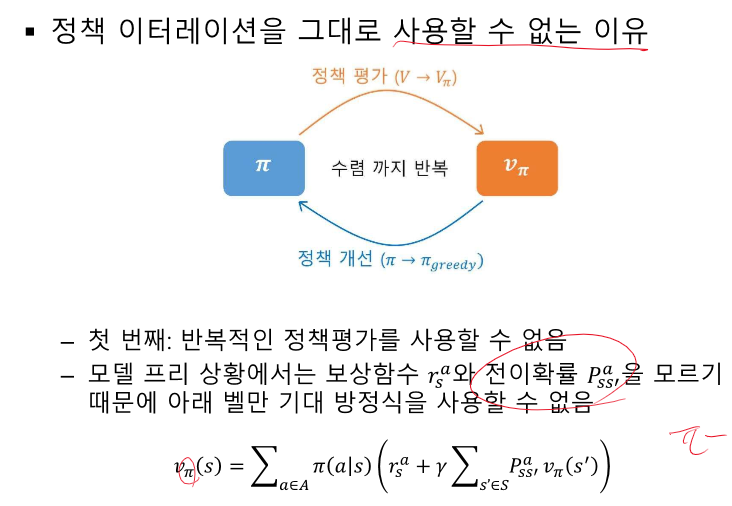
공간 데이터(이미지)를 FCN하기 위해 1차원으로 변환하는 순간 형상정보가 분산 되기 때문에 패턴 인식이 어렵다. 또한 파라미터의 개수, 연산량의 기하급수적으로 증가하기 때문에 이미지 데이터 처리에 FCN은 별로다 시신경 시스템을 모방하였다. -> 계층적으로 합성곱을 진행한다. 입력 데이터 - Width * Height * Depth(채널) 수용영역 - filter의 크기에 따라 달라진다. activation map = convolution연산의 결과로 만들어지는 이미지 feature map = 합성곱 연산 결과만 한것 (activation function x) 서브 샘플링 - 데이터를 낮은 빈도로 샘플링 했을 때 샘플을 근사하는 연산 데이터가 이미지면 이미지 크기를 줄이는 연산이 되어 다운 샘플링이라고..