728x90
728x90
밸류 (v) 평가하기 - Prediction
정책 찾기 - Control


k는 에피소드 단위 시간!
P =1이라는 것은 내가 원하면 무조건 거길로 가는 것!
V : MDP를 알 때 - 정보가 많은 상황
ㄴ 알지만 모른다고 치고 Q를 써도 되지 않을까?
ㄴㄴ 써도 된다 BUT 왜 V를 쓸까?
-> 굳이 Q를 안써도 되기 때문
V는 state의 가치 Q는 action을 취했을 때 state의 가치
-> V의 복잡도가 더 낮기 때문에 V를 사용한다.
내가 어떤 상태에서 어떤 행동을 취했을 때 어떤 상태로 갈 확률을 안다!
==> V를 사용한다.
Q를 일부로 사용하는 경우도 있다. On Policy, off Policy
Q : MDP를 모를 때


최신값 사용 - 학습 속도는 빨라질 수 있으나 진동이 커진다.

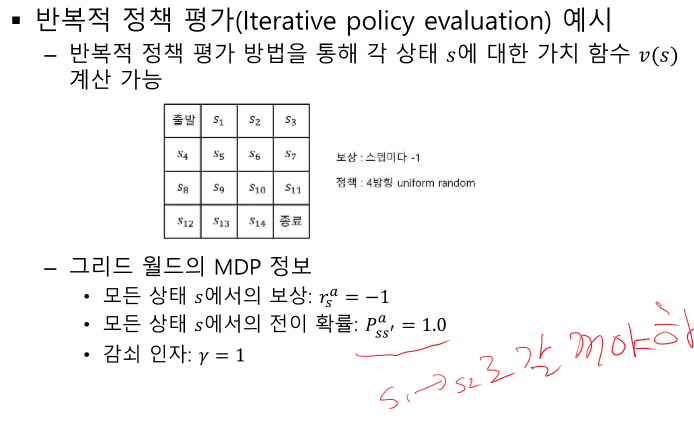
반복적 정책 평가 - 랜덤 or 특정 정책에 대해 계속 반복

여기선 특정 정책에 대해 계속 평가한다. 모든 V를 계산하면 특정 정책을 취했을 때 알 수 있다.
Control - 가치를 보며 움직인다.








수렴값이 아니기 때문에 초창기 정책에 문제가 생길 수 있지만 반복하다보면 셋을 줄이며 경우의 수를 줄여 잘 찾는다.


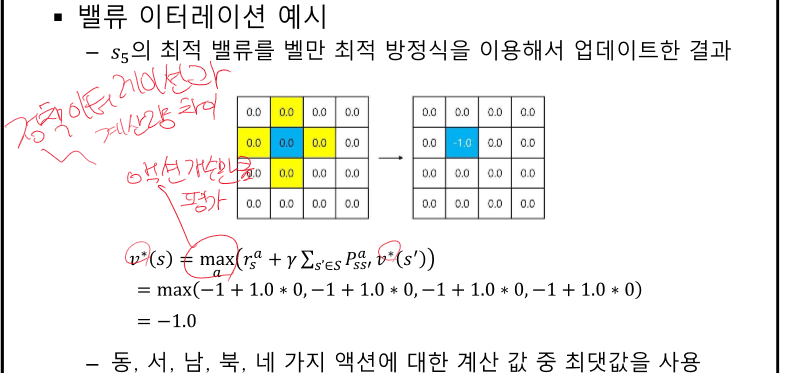
최선이 아닐 수 있다. -> 쉬운 문제에서 사용한다.



728x90
'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 정리 - 6장 MDP를 모를 때 최고의 정책 찾기 (0) | 2024.04.20 |
|---|---|
| 강화 학습 정리 5강 - MDP를 모를 때 밸류 평가하기 (34) | 2024.04.20 |
| 강화 학습 정리 - 3강 벨만 방정식 (1) | 2024.04.20 |
| 강화학습 정리 - 1강 강화학습이란? (0) | 2024.04.20 |
| 강화학습 정리 - 2강 마르코프 프로세스 (1) | 2024.04.20 |