R- 보상, 리워드
G - 리턴
v - 상태 가치 방정식
q - 액션 가치 방정식
E - 평균 취하기
* - 최적 값
t - 상태 시간 단위 (k 보다 작은 시간인데 이전에서 나왔던 시간의 개념과 똑같다.)
k - 에피소드 시간 단위


평균은 어디? - 어차피 마지막에 평균있어서 ㄱㅊ


항상 성립하는 것은 아니다 v(s) != v(s')이기 때문


v : s에 대한 리턴의 기댓값
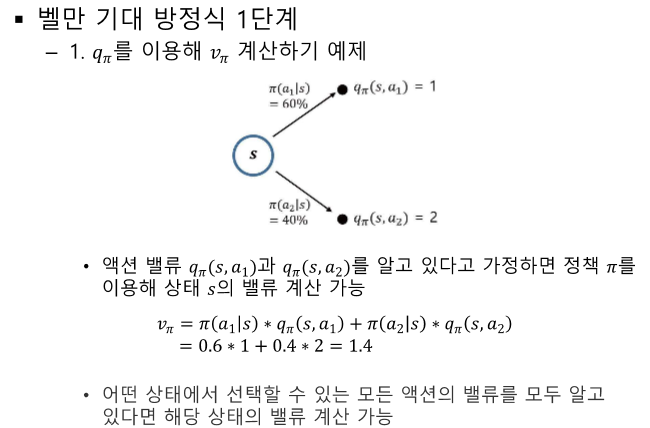
액션이 추가되었다.
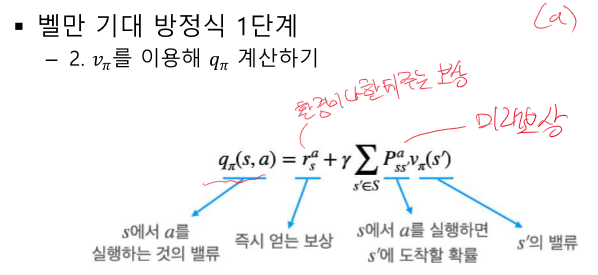
v(특정 s의 가치)와 q(특정 s에서 a를 취했을 때 가치)의 관계
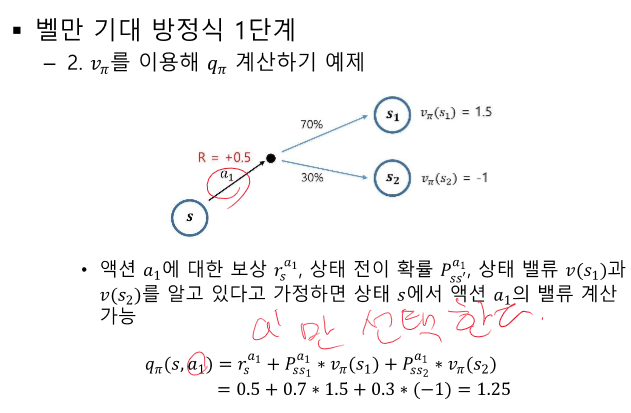


모델 프리 : 결과는 얻어지나 어떤 값으로 계산되는지 모르는 경우

v와 q의 선택은 목표에 따라 다르다.
어떤 위치에 도달해야 한다. S를 변화해야 한다.
S를 예측할 수 없다. -> q를 사용한다.
s'을 모를 때 q(s,a)를 대신해서 사용한다.

V와 Q의 차이는 ?
MDP를 알 때 우리는 왜 V를 이용해서 정책을 찾았는가 ? - v가 연산과정이 더 짧다.




강화학습에서 보상은 액션에서 줄 수도 있고, 액션으로 인한 변화한 상태에서 줄 수 있는거야?
네, 맞습니다. 강화학습에서 보상은 액션을 취함으로써 발생하는 결과에 따라 주어질 수 있으며, 이는 액션 자체 또는 액션으로 인해 변화한 상태 모두를 기반으로 할 수 있습니다. 구체적으로 설명하자면:
1. 액션에서 주는 보상: 어떤 특정 액션을 취했을 때 직접적으로 보상을 받는 경우입니다. 예를 들어, 비디오 게임에서 적을 처치하는 액션을 취했을 때 점수(보상)를 받는 경우가 여기에 해당합니다.
2. 액션으로 인한 변화한 상태에서 주는 보상: 액션의 결과로 상태가 변화했을 때 그 변화된 상태를 기반으로 보상을 받는 경우입니다. 예를 들어, 미로 찾기 게임에서 출구에 도달하는 것이 최종 목표일 때, 출구에 더 가까워진 상태로 이동하는 액션을 취했을 때 보상을 받는 것이 여기에 해당합니다.
강화학습의 목표는 에이전트가 환경과 상호작용하며 얻은 경험으로부터 학습하여, 최적의 정책(policy)을 통해 누적 보상을 최대화하는 것입니다. 따라서 보상을 어떻게 설정하느냐가 학습의 방향과 효율성에 큰 영향을 미칠 수 있습니다.
그럼 강화학습을 진행할 때 벨만 기대 방정식을 사용하거나 마르코프 결정 프로세스를 사용하려면 내가 에피소드를 끝까지 다 경험해서 모든 액션, 모든 액션에 대한 상태의 확률, 상태와 보상을 알아야 하는거아니야.??
강화학습을 진행할 때 벨만 기대 방정식이나 마르코프 결정 프로세스(MDP)를 사용한다는 것은 환경의 동적인 특성을 수학적으로 모델링하여 문제를 해결하려는 시도입니다. 하지만 실제로 모든 액션, 모든 상태 전이 확률, 그리고 상태와 보상을 사전에 완벽히 알고 있어야 한다는 것은 매우 제한적인 상황에서만 가능합니다. 실제 강화학습 환경, 특히 복잡하고 예측 불가능한 환경에서는 이 모든 정보를 미리 알기 어렵습니다.
대신, 강화학습은 에이전트가 환경과 상호작용하면서 경험을 통해 학습하는 방식을 사용합니다. 에이전트는 주어진 상태에서 가능한 액션을 취하고, 그 결과로 받는 보상과 새로운 상태를 관찰하여 이 데이터를 기반으로 학습을 진행합니다. 이 과정에서 벨만 기대 방정식은 현재 상태의 가치를 추정하는 데 도움을 주며, 이는 에이전트가 결정을 내리는 데 사용되는 중요한 지표가 됩니다.
벨만 기대 방정식이나 MDP를 활용하는 것은 에이전트가 더 나은 결정을 내릴 수 있도록 하는 이론적인 틀을 제공합니다. 에피소드를 끝까지 경험하지 않아도, 샘플링을 통해 얻은 경험으로부터 추정값을 업데이트하며 학습을 진행할 수 있습니다. 강화학습의 목표는 이러한 추정 과정을 통해 최적의 정책을 찾는 것입니다.
실제로 강화학습 알고리즘, 예를 들어 Q-learning이나 Deep Q-Networks(DQN) 등은 이런 원리를 바탕으로 하여, 전체 환경을 사전에 알지 못해도 경험을 통해 학습하고 최적의 정책을 찾아갑니다.
'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 정리 5강 - MDP를 모를 때 밸류 평가하기 (34) | 2024.04.20 |
|---|---|
| 강화 학습 정리 - 4강 MDP를 알 때의 플래닝 (1) | 2024.04.20 |
| 강화학습 정리 - 1강 강화학습이란? (0) | 2024.04.20 |
| 강화학습 정리 - 2강 마르코프 프로세스 (1) | 2024.04.20 |
| 생성형 인공지능 특강 (0) | 2024.04.17 |