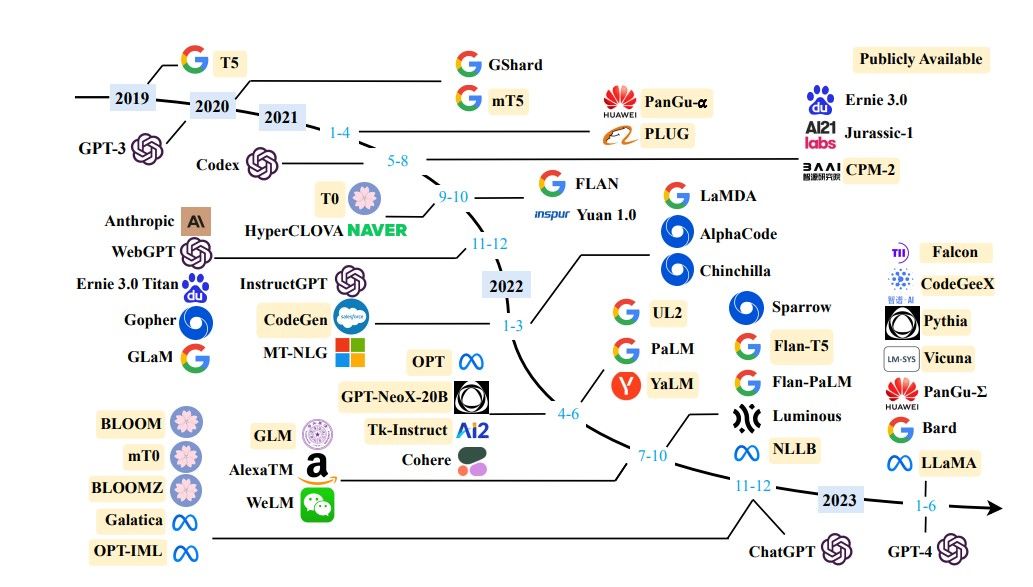
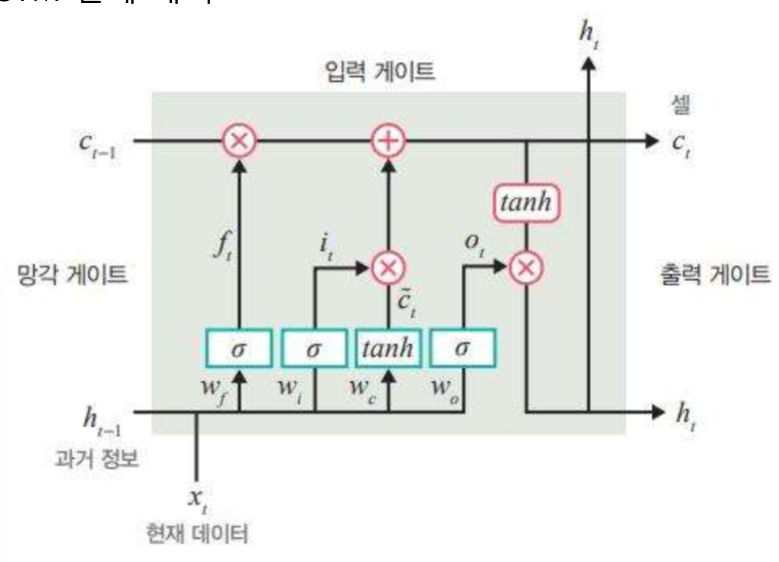
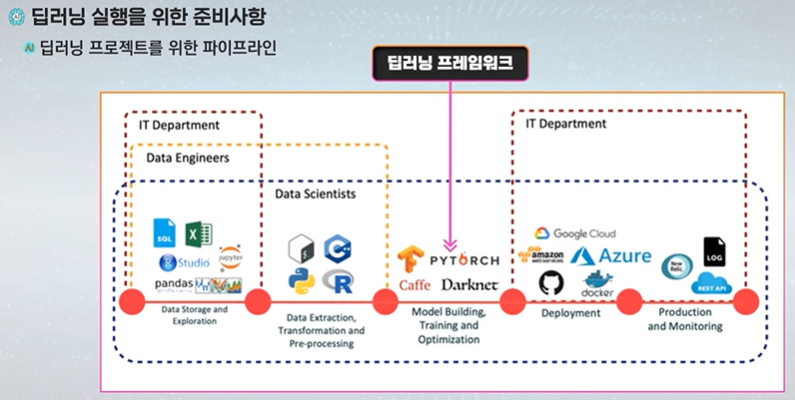
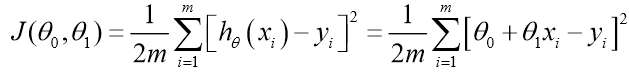Video LLM은 짧은 비디오에 대한 캡셔닝, 질문응답, 장면 요약 등의 작업에서는 준수한 성능을 보이지만, 여전히 긴 비디오 처리, 시계열 추론, 객체 단위 정밀 인식, 실시간 대응 측면에서는 한계를 드러낸다. Seq2Time은 절대 시간 표현의 일반화 실패 문제를 해결하기 위해 상대 위치 토큰을 도입하여 시계열 데이터를 효과적으로 정렬하고, 다양한 길이의 영상에서도 시간 표현의 일반화를 가능하게 했다. DynFocus는 질문과 정합성이 높은 프레임을 선택하고 나머지는 희소 인코딩으로 처리함으로써, 효율성과 정밀도의 균형을 맞춘다. VideoTree는 시각 정보를 계층화하여 질문과 연관된 프레임만을 추출하고, reasoning 연쇄 구조에 따라 재정렬된 캡션을 문서화하여 LLM 입력으로 활용함으로써 ..