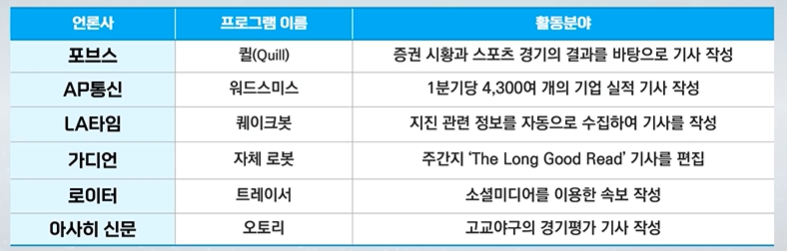
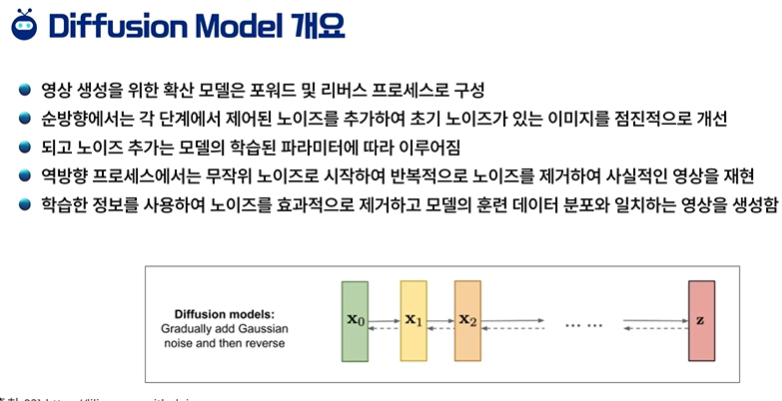
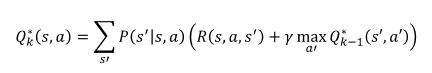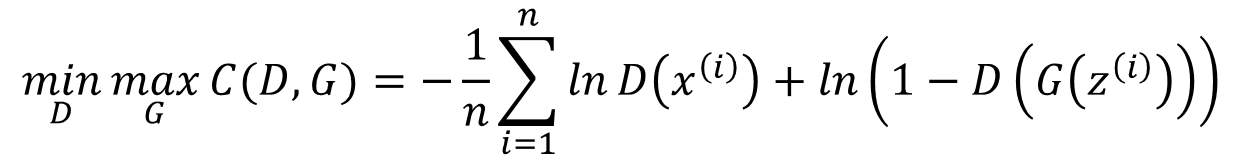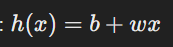강화학습은 시스템은 복잡하지만 결과는 간단할 때 사용할 수 있다.관찰되는 정보만으로 action을 정하고, 리워드가 큰 행동이 바람직하다.미래의 평균 누적 보상을 최대화 하는 행동을 선택즉각 보상과 장기 보상의 균형이 필요하다.높은 보상을 얻기 위해 전략이 필요하다.히스토리 - 과거 관찰, 행동, 보상의 시퀸스 - (a1,o1,r1,...,at,ot,rt)에이전트는 히스토리에 기반해 행동 선택 state는 다음 시점에 무슨 일이 일어나는지에 대한 정보 st = f(ht)세계 상태 - 에이전트와 무관한 정보를 포함하는 실제 세계 상태다음 관찰과 보상을 어떻게 생성할지에 대한 실제 상태일부 숨겨지거나 에이전트에게 알려지지 않을 수 있다. - MDP가 아닐 때에이전트에게 알려진 경우에도 불필요한 정보가 포함될..