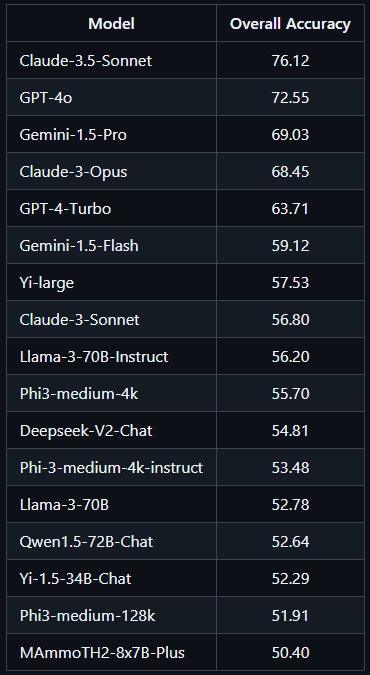
class로 된 python이라 self나 다른 것 들이 붙어있긴 한데 적당히 보면 될 것 같습니다.기록 용이라....from datasets import load_from_disk, DatasetDictimport argparse, os, json, torch, itertools, math, refrom typing import List, Dict, Tuplefrom scipy.special import digammafrom vllm import LLM, SamplingParamsfrom collections import defaultdict, Counterfrom transformers import AutoTokenizerfrom setproctitle import setproctitle 일단 전부 ..