728x90
728x90
모델을 굽기 위해 데이터를 수집하면서 토큰 수 확인은 필수기에 한번 가지고 왔습니다.
from datasets import list_datasets, load_dataset
# 데이터셋 불러오기
dataset = load_dataset("nvidia/ChatQA-Training-Data","synthetic_convqa")
# 데이터셋 분할 정보 확인
print(dataset)일단 데이터 불러오기!
import pandas as pd
import tiktoken
df = pd.DataFrame(dataset["train"])
df이제 DataFrame으로 변경하고 데이터 형식 확인하기

여기선 다른 이름이 많은데 저는 특정 column만 골라서 사용할 겁니다.
import math
def tokenize_in_batches(df, text_column="text", batch_size=10000):
"""
df의 text_column을 batch_size 단위로 끊어서 토큰 길이를 계산하고,
num_tokens 컬럼에 저장해 반환합니다.
"""
enc = tiktoken.get_encoding("cl100k_base")
# 결과를 담을 리스트
token_lengths = [None] * len(df)
num_batches = math.ceil(len(df) / batch_size)
for i in range(num_batches):
start = i * batch_size
end = start + batch_size
batch_texts = df[text_column].iloc[start:end].tolist()
# 이 부분에서 각 텍스트를 토크나이즈하여 길이를 구한다
batch_token_lengths = [len(enc.encode(str(text), allowed_special={"<|endoftext|>"})) for text in batch_texts]
# 결과를 token_lengths에 저장
token_lengths[start:end] = batch_token_lengths
print(f"Batch {i+1}/{num_batches} 처리 완료")
df["num_tokens"] = token_lengths
return df
# 사용 예시
# 컬럼 이름 변경(예: content -> text)
# df.rename(columns={'content': 'text'}, inplace=True)
df1 = tokenize_in_batches(df, text_column="messages", batch_size=10000)
print("총 토큰 수:", df1["num_tokens"].sum())
print("평균 토큰 수:", df1["num_tokens"].mean())
df1sum = df1["num_tokens"].sum()이제 토큰 수 확인하면 됩니다.
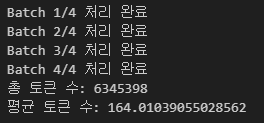
이렇게 나오는 것을 확인할 수 있습니다.
column이름만 바꿔서 아래와 같이 사용 가능합니다.
df2 = tokenize_in_batches(df, text_column="answers", batch_size=10000)
print("총 토큰 수:", df2["num_tokens"].sum())
print("평균 토큰 수:", df2["num_tokens"].mean())
df2sum = df2["num_tokens"].sum()
df3 = tokenize_in_batches(df, text_column="document", batch_size=10000)
print("총 토큰 수:", df3["num_tokens"].sum())
print("평균 토큰 수:", df3["num_tokens"].mean())
df3sum = df3["num_tokens"].sum()
print (df1sum + df2sum +df3sum )총 토큰 수는 이렇게 구할 수 있습니다.
이제 document가 겹칠 때 구하는 방법입니다.
def compute_tokens_dedup_text(df, text_column="document"):
"""
동일한 텍스트가 여러 번 나오면,
- 처음 1회는 실제 토큰 길이를 계산
- 이후 중복으로 등장하는 텍스트는 0으로 처리
"""
enc = tiktoken.get_encoding("cl100k_base")
# 이미 계산한 텍스트를 저장할 딕셔너리
# key: 텍스트 내용 (string), value: 해당 텍스트의 토큰 길이
token_cache = {}
token_counts = []
for _, row in df.iterrows():
txt = str(row[text_column]) # 혹시 NaN이 있을 수 있으니 str() 변환 권장
if txt in token_cache:
# 이미 계산했던 텍스트 -> 중복 처리 (토큰 수 0으로)
token_counts.append(0)
else:
# 새 텍스트라면 토큰 길이를 계산하고, 캐시에 저장
tokens = len(enc.encode(txt))
token_cache[txt] = tokens
token_counts.append(tokens)
# 새로운 컬럼에 저장
df["num_tokens_dedup"] = token_counts
return df
df = compute_tokens_dedup_text(df)
count_non_zero = (df['num_tokens_dedup'] != 0).sum()
print(df)
print("실제 계산된 토큰 수 합:", df["num_tokens_dedup"].sum())
print("문서 수:", count_non_zero)
print("평균 문서 토큰 수:", df["num_tokens_dedup"].sum()/count_non_zero)
깔끔하게 확인할 수 있었습니다.
이제 중복도 확인하려고 합니다.
document와 messages가 동일하게 같은 경우 입니다.
def check_document_in_messages(df):
"""
Checks if the document content appears in any message content.
Returns the indices of rows with overlaps.
"""
overlap_indices = []
for index, row in df.iterrows():
document = row.get('document', None)
messages = row.get('messages', None)
# Validate structure of document and messages
if not isinstance(document, str) or not isinstance(messages, list):
continue # Skip rows with invalid structure
# Check if document appears in any message content
if any(
isinstance(message, dict) and 'content' in message and document in message['content']
for message in messages
):
overlap_indices.append(index)
return overlap_indices
# Apply the function
overlap_indices = check_document_in_messages(df)
# Display overlapping rows if any
if overlap_indices:
overlapping_rows = df.loc[overlap_indices]
else:
print("No overlapping rows found between 'document' and 'messages'.")
그런데 여기선 같은 경우가 없어서 안나오긴 했습니다!
728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| Late Chunking 사용해보기 및 Chunking 코드 익숙해지기 (1) | 2025.01.22 |
|---|---|
| Semantic, Dynamic Chunking 자료 정리 (0) | 2025.01.21 |
| Chat QA1, Chat QA2 정리하면서 발전 가능성, 개선 점 생각해보기 (0) | 2025.01.03 |
| Chat QA1, Chat QA2 (0) | 2024.12.29 |
| DEPS와 GITM 비교 (0) | 2024.11.27 |