일단 RAG에 좋은 사이트를 발견해서 기록
Open RAG | Notion
An open-source and open-access RAG platform
openrag.notion.site
https://arxiv.org/abs/2410.13070
Is Semantic Chunking Worth the Computational Cost?
Recent advances in Retrieval-Augmented Generation (RAG) systems have popularized semantic chunking, which aims to improve retrieval performance by dividing documents into semantically coherent segments. Despite its growing adoption, the actual benefits ove
arxiv.org
라마 인덱스나 랭체인 기반 청킹은 앞 뒤 문장 임베딩의 경계 값을 가지고 나눕니다.
이러면 지칭이 대명사로 바뀌었을 때 분명 문제가 생길 것 같은데...

Clustering-based Semantic Chunker에 대한 쉬운 설명
1. 개요
Clustering-based Semantic Chunker는 문장을 의미적으로 그룹화하여 청크를 만드는 방식입니다. 이 접근법은 문서 내 문장들 간의 전역적 관계(global relationships)를 포착할 수 있다는 장점이 있으며, 비연속적 문장(non-sequential sentences)도 같은 청크로 묶일 수 있습니다. 하지만, 문장 순서에 숨겨진 문맥적 정보(contextual information)를 잃을 위험이 있습니다.
이를 해결하기 위해, 이 논문에서는 위치 정보(positional distance)와 의미적 거리(semantic distance)를 결합한 새로운 거리 측정 방법을 제안합니다.
2. 거리 계산 방법

3. 클러스터링 알고리즘
논문에서는 두 가지 주요 클러스터링 알고리즘을 사용하여 문장을 그룹화합니다.
(1) Single-linkage Agglomerative Clustering
- 방법:
- 모든 문장 쌍의 거리를 계산하여 거리 행렬(distance matrix)을 생성.
- 가장 가까운 두 문장을 합쳐 클러스터를 형성.
- 클러스터 간의 최소 거리를 기준으로 병합을 반복.
- 사전 정의된 최대 청크 크기를 넘지 않도록 조정.
- 한계점:
- 사전에 클러스터 개수를 설정해야 하며, 이를 정확히 결정하기 어렵습니다.
- 문장이 적절히 그룹화되지 않을 수 있습니다.
(2) DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- 방법:
- 문장 간 밀도(density)를 기준으로 클러스터링 수행.
- 밀도가 높은 영역에 있는 문장을 클러스터로 그룹화하고, 밀도가 낮은 문장은 제거 또는 독립적으로 처리.
- 클러스터의 크기를 자동으로 조정 가능.
- 장점:
- 클러스터 개수를 사전 정의할 필요가 없으며, 데이터 밀도에 따라 동적으로 클러스터를 형성.
4. 실험 중 발생한 문제와 해결 방법
문제 1: 클러스터 크기 제약
- 클러스터 크기에 제한이 없을 경우, 일부 클러스터는 너무 커지고, 나머지는 고립된 문장으로 남는 문제가 발생.
- 해결 방법: 클러스터 크기를 문서 길이에 비례하여 제한.
문제 2: 비의도적 문장 그룹화
- 서로 멀리 떨어진 문장이 강제로 클러스터에 포함될 수 있음.
- 해결 방법: 특정 거리 임계값(threshold)을 설정하여, 문장 간 거리가 기준을 초과하면 클러스터링을 중단.
문제 3: 사전 클러스터 개수 결정의 어려움
- Single-linkage 방식은 사전 클러스터 개수 설정이 필요.
- 해결 방법: DBSCAN을 사용하여 클러스터 개수를 동적으로 조정.
5. 요약 및 특징
| 항목 | 설명 |
| 장점 | - 문서의 전역적 의미 관계를 포착. - 비연속적 문장을 그룹화 가능. |
| 단점 | - 계산 비용이 높음. - 문맥 정보(문장 간의 순서나 위치)가 손실될 가능성 있음. |
| 거리 계산의 핵심 | 위치적 거리와 의미적 거리의 조합 (λ로 가중치 조절). |
| 적용된 클러스터링 알고리즘 | - Single-linkage Agglomerative Clustering. - DBSCAN (동적 클러스터링 가능). |
| 실험적 해결 방안 | - 클러스터 크기 제한. - 거리 임계값 설정. - DBSCAN으로 동적 클러스터링 수행. |
6. 이해하기 쉬운 비유
이 방법을 문서 속 문장들을 그룹화하는 작업에 비유하면:
- Single-linkage는 거리 기준으로 가까운 사람들부터 그룹을 만드는 방식.
- DBSCAN은 밀도가 높은 지역(비슷한 주제의 문장)을 중심으로 그룹을 형성하고, 외딴 지역은 배제하는 방식입니다.
- 위치와 의미를 결합한 거리 계산은 사람들의 물리적 거리(위치)와 관심사(의미)를 모두 고려해 친구를 묶는 방식과 유사합니다.
여기서 Document Retrieval과 Evidence Retrieval이 나옵니다.
그 차이점은 여기에
이 논문에서 언급된 Document와 Evidence의 차이를 이해하려면 각각이 어떤 문맥에서 사용되는지 살펴보아야 합니다. 아래에서 두 개념을 비교해 설명하겠습니다.
1. Document
- 정의:
- 문서(Document)는 데이터베이스에서 검색해야 하는 전체 텍스트 또는 정보 단위를 의미합니다.
- 일반적으로 하나의 독립적인 정보 단위로 취급되며, 이는 원래 데이터의 일부(예: 논문, 보고서, 문단 등)입니다.
- 목적:
- 문서를 검색하는 목적은 특정 질문이나 쿼리에 가장 관련성이 높은 전체 텍스트 단위를 찾는 것입니다.
- 예: "이 질문과 가장 관련 있는 문서 전체를 찾아라."
- 특징:
- 문서에는 여러 주제가 포함될 수 있습니다(특히 "stitched documents"처럼 다양한 주제를 결합한 경우).
- 문서 내에서 관련성이 낮은 부분도 포함될 수 있어 "토픽 간 혼합" 문제가 발생할 수 있습니다.
- 문맥에서의 역할:
- Document Retrieval (문서 검색) 단계에서는, 특정 질문에 대해 가장 관련성 높은 문서를 찾는 것이 목표입니다.
- 이 과정에서는 문서가 여러 문장이나 단락으로 구성되어 있고, 주제가 다양하게 섞여 있을 수 있습니다.
2. Evidence
- 정의:
- 증거(Evidence)는 특정 질문을 뒷받침하는 핵심 정보(주로 하나 또는 여러 문장)를 의미합니다.
- 문서 안에서 질문에 대한 답변에 필요한 가장 관련 있는 세부 정보를 나타냅니다.
- 목적:
- 증거를 검색하는 목적은 특정 질문에 대한 답변을 구성할 수 있는 핵심 문장이나 텍스트 조각을 찾는 것입니다.
- 예: "이 질문에 답하기 위해 문서 안에서 가장 관련 있는 문장 몇 개를 찾아라."
- 특징:
- 증거는 전체 문서의 작은 부분이며, 일반적으로 질문과 명확히 연결된 정보를 포함합니다.
- 문서에서 다른 문장은 필요하지 않을 수도 있습니다.
- 문맥에서의 역할:
- Evidence Retrieval (증거 검색) 단계에서는, 문서 내에서 질문과 가장 관련된 핵심 문장을 찾는 것이 목표입니다.
- 여기서 강조하는 것은 "문서 전체"가 아니라, 그 안에서 특정 쿼리에 답을 제공할 수 있는 "증거"의 정확성과 위치입니다.
문맥에 따른 차이
| 특성 | Document | Evidence |
| 단위 | 전체 문서 (여러 문장과 단락 포함) | 특정 문장이나 텍스트 조각 |
| 목적 | 질문에 가장 관련 있는 전체 문서를 찾음 | 문서 내에서 질문에 답이 되는 정보를 찾음 |
| 크기 | 크기가 클 수 있음 | 크기가 작고 간결함 |
| 사용 방식 | 문서의 주제 다양성 또는 응집력이 중요함 | 질문과 관련된 세부 정보가 중요함 |
| 문맥에서 역할 | "관련성 있는 문서 전체"를 찾는 초기 단계 | "구체적인 답변"을 위한 세부 정보 추출 단계 |
문장에서 차이
- Document Retrieval (문서 검색):
- "Stitched documents"와 같은 복잡한 데이터에서 특정 주제를 유지하며 의미 있는 문서를 검색하는 방법을 다룹니다.
- Semantic Chunker가 이런 데이터를 처리하기 유리하며, Fixed-size Chunker는 주제가 적은 경우 유리합니다.
- Evidence Retrieval (증거 검색):
- 문서 내부에서 특정 질문과 관련된 핵심 문장을 검색하는 과정입니다.
- 여기서는 Chunking 방법(예: Semantic vs Fixed-size)의 차이가 미미하다고 언급됩니다. 이는 질문에 답변하는 데 필요한 핵심 증거가 대부분 Chunking 방식에 상관없이 검색되기 때문입니다.
요약
- Document Retrieval: 문서 전체를 검색하는 단계로, 주제 다양성과 Chunking 방식이 중요합니다.
- Evidence Retrieval: 문서 내부에서 특정 질문에 답이 되는 문장을 찾는 단계로, Chunking보다는 문장 단위의 의미를 정확히 파악하는 것이 중요합니다.

결국 이렇게 Semantic하게 Chunking을 나눠도 결과에큰 차이가 없다는 것이 문제였습니다.
흠....
https://arxiv.org/abs/2409.04701
Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models
Many use cases require retrieving smaller portions of text, and dense vector-based retrieval systems often perform better with shorter text segments, as the semantics are less likely to be over-compressed in the embeddings. Consequently, practitioners ofte
arxiv.org

Late Chunking의 장점을 뚜렷하게 보여주는 Table입니다.
Its나 The city에서 Berlin의 정보가 없기에 Naive한 방식에선 유사도가 낮게 나오지만 Late 방식에선 높은 유사도를 가지는 것을 볼 수 있습니다.
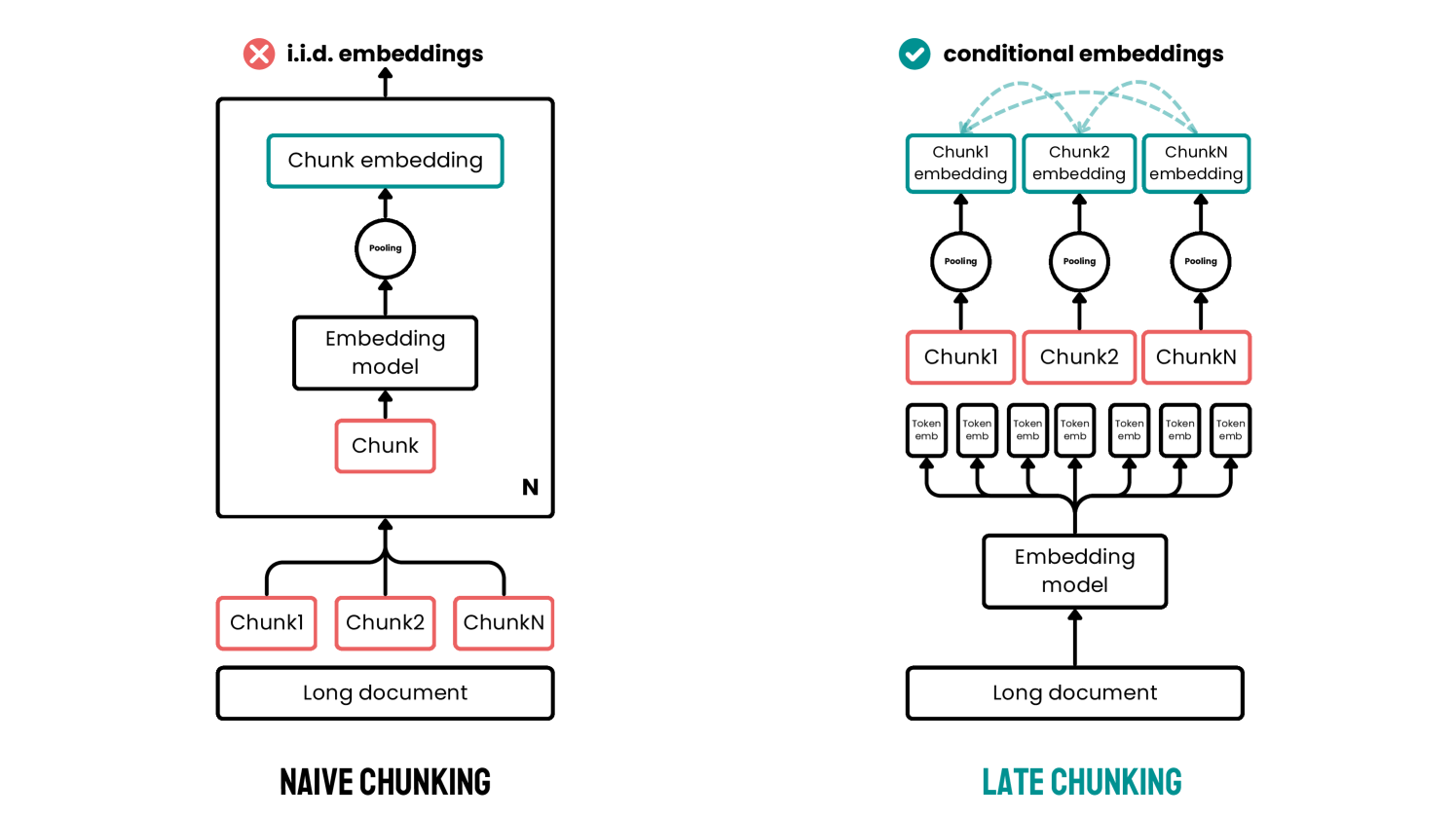

알고리즘 1: Late Chunking에 대한 설명
이 알고리즘은 긴 텍스트 문서를 전체 문맥을 반영한 토큰 임베딩을 생성한 뒤, 이를 청크 단위로 나누어 각 청크의 임베딩 벡터를 생성하는 과정을 설명합니다. 주요 단계를 하나씩 분석하겠습니다.
알고리즘 단계 설명
입력 및 출력
- 입력(Input):
- T: 긴 텍스트.
- S: 청크 분할 전략 (예: 고정 길이, 문장 단위 등).
- 출력(Output):
- e1, e2, ..., en: 청크별 임베딩 벡터.
1단계: 텍스트 청크화
1: (c1, . . . , cn) ← Chunker(T, S)
- 텍스트 T를 주어진 전략 S에 따라 청크 단위(c1, ..., cn)로 나눕니다.
- 예를 들어:
- 고정된 토큰 크기 기준(예: 256 토큰씩 나누기).
- 문장 단위로 나누기.
2단계: 텍스트 토큰화
2: (τ1, . . . , τm), (o1, . . . , om) ← Tokenizer(T)
- 텍스트 T를 토큰화하여 토큰 ID(τ)와 토큰 길이(o) 정보를 생성합니다.
- τi: 각 토큰의 ID.
- oi: 각 토큰의 문자 길이.
- 예: "Berlin is the capital" → τ = [1, 2, 3, 4], o = [6, 2, 3, 7].
3단계: 토큰 임베딩 계산
3: (ϑ1, . . . , ϑm) ← Model(τ1, . . . , τm)
- Transformer 모델에 토큰 ID(τ1, ..., τm)를 입력하여 각 토큰의 임베딩(ϑ1, ..., ϑm)을 계산합니다.
- 각 토큰 임베딩은 문서 전체 문맥을 반영한 벡터입니다.
4~13단계: 청크 경계 설정
4: ochunk ← 0, j ← 1, cuestart ← 1, cues ← [ ]
5: for i ∈ {1, . . . , m} do
6: ochunk ← ochunk + oi
7: if ochunk ≥ |cj| then
8: cueend ← i
9: cues ← cues ⊕ (cuestart, cueend)
10: j ← (j + 1), cuestart ← (i + 1)
11: ochunk ← 0
12: end if
13: end for
- 청크의 시작(cuestart)와 끝(cueend) 위치를 설정하는 과정입니다.
- 세부 과정:
- ochunk는 현재 청크에 포함된 토큰의 총 길이를 누적합니다.
- ochunk가 현재 청크 크기(|cj|)를 초과하면:
- 현재 토큰 위치를 청크의 끝 위치(cueend)로 저장.
- cuestart와 cueend를 cues 리스트에 추가.
- 새로운 청크를 시작하기 위해 cuestart와 ochunk를 초기화.
- 모든 토큰(i ∈ {1, ..., m})에 대해 이 작업을 반복.
14~16단계: 청크별 임베딩 생성
14: for (cuestart, cueend)i ∈ cues do
15: ei ← ∑cueend
j=cuestart
ϑj / ((cueend + 1) − cuestart)
16: end for
- 각 청크에 대해 최종 임베딩 벡터(ei)를 생성:
- cuestart와 cueend에 해당하는 토큰 임베딩(ϑj)을 평균화(mean pooling).
- 각 청크의 임베딩(ei)은 그 청크에 포함된 모든 토큰 임베딩의 평균값입니다.
핵심 작동 원리
- 문맥 반영: 문서 전체를 Transformer 모델로 처리해 모든 토큰에 문맥 정보를 포함.
- 후처리 방식: 청크 단위를 모델 처리 이후 결정해 문맥 손실 방지.
- 효율성: 청크 단위로 평균화(mean pooling)하여 단일 벡터(ei)로 변환.
장점
- 문맥 유지: 청크 경계에서 문맥 정보가 손실되지 않음.
- 유연성: 다양한 청크 전략(S)에 적용 가능.
- 추가 학습 불필요: 기존 임베딩 모델에 바로 적용 가능.
한계
- 리소스 사용량 증가: 문서 전체를 Transformer로 처리해야 하므로 메모리와 계산량이 증가.
- 청크 크기에 따른 민감도: 너무 작은 청크는 문맥 정보를 완전히 활용하지 못할 수 있음.
결론
이 알고리즘은 문서 전체 문맥을 반영한 임베딩을 생성하여 기존 Naive Chunking 방식의 단점을 해결합니다. 검색 및 질의응답 같은 작업에서 문맥 손실 없이 높은 성능을 제공할 수 있는 실용적인 방법입니다.

Algorithm 2: Long Late Chunking
이 알고리즘은 문서가 모델의 최대 토큰 길이(l_max)를 초과할 경우, 오버랩 토큰(ω)을 활용하여 긴 문서를 처리하는 방법입니다. 기존 Late Chunking 방식을 확장하여 긴 문맥을 유지하면서 효율적으로 청크를 처리하는 프로세스를 제공합니다.
1. 입력 및 출력
- Inputs:
- T: 긴 텍스트 문서.
- S: 청크 분할 전략 (문장, 고정 길이 등).
- l_max: 모델이 한 번에 처리할 수 있는 최대 토큰 길이.
- ω: 매크로 청크 간 오버랩 토큰 길이 (문맥 연결성을 위해 추가되는 토큰 길이).
- Outputs:
- E = (e1, e2, ..., en): 최종 청크 임베딩 벡터.
2. 알고리즘의 주요 단계
(1) 기본 Late Chunking으로 처리 가능한지 확인
3: if m < lmax then ▷ If the number of tokens is already small, do regular late chunking
4: return LateChunking(T, S)
5: end if
- 문서의 총 토큰 수(m)가 모델의 최대 입력 길이(l_max)보다 작을 경우, 기존 Late Chunking 알고리즘(Algorithm 1)을 수행합니다.
- 이 경우 오버랩 토큰(ω) 처리가 필요 없으므로 바로 처리 가능.
(2) 매크로 청크 초기화
6: iend ← lmax , istart ← 1, embeddings ← [ ]
- i_start: 매크로 청크의 시작 토큰 인덱스.
- i_end: 매크로 청크의 끝 토큰 인덱스 (최대 토큰 길이로 초기화).
- embeddings: 계산된 토큰 임베딩을 저장할 리스트.
(3) 매크로 청크 단위 처리
7: while iend < lmax do
8: (ϑistart , . . . , ϑiend ) ← Model(τistart , . . . , τiend ) ▷ Calculate token embeddings
- 매크로 청크 범위(i_start ~ i_end) 내의 토큰 ID를 Transformer 모델에 입력하여 해당 범위의 토큰 임베딩을 계산합니다.
- 각 토큰 임베딩(ϑ_{i_start}, ..., ϑ_{i_end})은 문맥 정보를 반영한 벡터입니다.
(4) 오버랩 토큰 추가
9: if istart = 1 then
10: embeddings ← embeddings ⊕ (ϑistart , . . . , ϑiend )
11: else
12: embeddings ← embeddings ⊕ (ϑistart+ω, . . . , ϑiend )
13: end if
- 오버랩 토큰(ω)을 추가하여 청크 간 문맥 연결성을 유지합니다.
- 첫 번째 청크:
- 오버랩 없이, 전체 청크를 그대로 저장.
- 이후 청크:
- 이전 청크와 중복되는 오버랩 토큰(ϑ_{i_start+ω})을 포함하여 저장.
- 첫 번째 청크:
- 오버랩 토큰은 청크 간 문맥 단절 문제를 해결하고, 긴 문서에서 중요한 정보를 유지하도록 돕습니다.
(5) 청크 범위 업데이트
14: istart ← iend + 1 ▷ Update token positions with overlap
15: iend ← min(iend + lmax − ω, lmax )
- 다음 매크로 청크로 이동:
- 시작 인덱스(i_start): 이전 청크의 끝 인덱스 이후로 설정.
- 끝 인덱스(i_end): 최대 길이를 초과하지 않도록 l_max - ω만큼 증가.
(6) 기존 Late Chunking 적용
17: Carry out steps 4 to 16 of Algorithm 1 with augmented token embeddings ϑ1, . . . , ϑm.
- 최종적으로, 오버랩 토큰이 추가된 임베딩을 기반으로 기존 Late Chunking 알고리즘(Algorithm 1)을 수행하여 청크 임베딩 벡터(e1, ..., en)를 생성합니다.
3. 알고리즘의 주요 특징
문맥 연결성을 유지
- 오버랩 토큰(ω)을 추가하여 긴 문서에서도 청크 간의 문맥을 연결합니다.
- 예:
- 첫 번째 청크: 1 ~ 8192 토큰.
- 두 번째 청크: 7681 ~ 16384 (512 토큰의 오버랩 추가).
- 이렇게 문맥 연결성을 보장하여 검색, 요약, 질의응답(QA) 등 작업에서 중요한 정보를 유지할 수 있습니다.
효율적인 긴 문서 처리
- 문서 전체를 한 번에 처리하지 않고, 매크로 청크 단위로 나누어 모델의 입력 제한(l_max)을 초과하지 않도록 처리.
- 이 방식은 계산량과 메모리 사용량을 효과적으로 관리하면서 긴 문서를 처리할 수 있게 합니다.
Late Chunking의 확장
- 기존 Late Chunking(Algorithm 1)을 기반으로 긴 문서를 처리할 수 있는 기능을 추가한 확장된 방식.
4. 장점
- 긴 문서 처리 가능:
- 문서가 l_max를 초과해도 처리 가능.
- 문맥 손실 최소화:
- 오버랩 토큰(ω)을 추가하여 청크 간 연결성을 유지.
- 유연성:
- 다양한 청크 분할 전략(S)과 결합 가능.
5. 단점
- 추가 계산 비용:
- 오버랩 토큰이 추가되므로 처리해야 할 토큰 수가 증가.
- 설정 민감도:
- l_max와 ω의 설정에 따라 성능이 달라질 수 있음.
6. 적용 사례
- 긴 문서 검색:
- 법률 문서, 의학 논문 등에서 특정 문맥을 검색할 때 유용.
- 질의응답(QA):
- 긴 텍스트 내 여러 청크에 걸친 정보를 연결하여 답변 생성.
- 문서 요약:
- 문맥을 유지하면서 청크 단위로 요약 정보 생성.
결론
Algorithm 2는 기존 Late Chunking 방식에 긴 문서를 효율적으로 처리할 수 있는 확장 기능을 추가한 방식입니다. 오버랩 토큰을 활용하여 문맥 손실을 방지하며, 검색, 요약, 질의응답 등 다양한 NLP 작업에서 활용될 수 있습니다.
Long Late Chunking은 Late Chunking과 비슷하지만 최대 Contexrt-Length인 8192를 넘었을 때 앞에 문맥을 추가로 주어줘 문맥이 이어지도록 만든 방식입니다.
그런데 이 것을 청킹으로 봐야 할지,,, 임베딩이라 봐야 할지 애매하네요...

Table 2: Retrieval Task에서 다양한 청크 방식의 평가 결과
이 표는 정보 검색(Retrieval) 작업에서 다양한 청크 방식과 모델의 성능을 비교한 결과를 나타냅니다. 주요 성능 지표로 nDCG@10(Normalized Discounted Cumulative Gain at rank 10)을 사용했으며, 숫자가 높을수록 검색 성능이 우수함을 의미합니다.
1. 주요 내용
평가 대상
- 청크 방식:
- Fixed-Size Boundaries: 고정된 크기(256 토큰)로 청크를 분할.
- Sentence Boundaries: 5개의 문장 단위로 청크를 분할.
- Semantic Sentence Boundaries: 의미적으로 연결된 문장 단위로 청크를 분할.
- 모델:
- Jina-Embeddings-v2-Small (J2s): Jina의 작은 크기 임베딩 모델.
- Jina-Embeddings-v3 (J3): Jina의 최신 버전 모델.
- Nomic-Embed-Text-v1 (Nom): Nomic의 텍스트 임베딩 모델.
- 데이터셋:
- SciFact: 과학적 주장 검색.
- NFCorpus: 정보 검색 코퍼스.
- FiQA: 금융 및 질문 응답 데이터셋.
- TREC-COVID: COVID-19 관련 문서 검색.
2. 결과 분석
(1) 청크 방식에 따른 성능
- Fixed-Size Boundaries (고정된 크기, 256 토큰):
- Naive와 Late의 성능 차이가 두드러지며, Late Chunking이 Naive Chunking 대비 평균적으로 더 높은 성능을 보임.
- 예: NFCorpus에서 Naive는 35.5%이지만 Late는 36.7%로 개선.
- Sentence Boundaries (5문장 단위):
- 5개의 문장 단위로 청크를 나눴을 때, Naive와 Late 모두 더 높은 성능을 보임.
- 특히, TREC-COVID 데이터셋에서 Late Chunking이 76.8%로 Naive(74.2%)보다 우수.
- Semantic Sentence Boundaries (의미 기반 분할):
- 의미적으로 연관된 문장 단위로 청크를 나눴을 때, Late Chunking이 전반적으로 가장 높은 성능을 보임.
- 예: SciFact에서 Naive는 64.3%지만 Late는 65.0%.
(2) 모델에 따른 성능
- J2s (Jina-Embeddings-v2-Small):
- J2s는 J3나 Nom 모델보다 전반적으로 성능이 낮음.
- 그러나 Late Chunking 방식이 J2s 모델에서도 성능을 꾸준히 개선.
- J3 (Jina-Embeddings-v3):
- 최신 J3 모델이 전반적으로 가장 높은 성능을 보임.
- Semantic Sentence Boundaries에서 TREC-COVID 데이터셋에서 Late Chunking으로 76.6%를 기록.
- Nom (Nomic-Embed-Text-v1):
- 고정 크기 청크 방식(Fixed-Size)에서 Late Chunking의 성능이 특히 우수.
- 예: FiQA에서 Naive는 38.3%, Late는 47.6%.
(3) Late vs Naive Chunking
- 전반적으로 Late Chunking은 Naive Chunking보다 높은 성능을 기록.
- 특히, Fixed-Size Boundaries에서 Naive 대비 큰 성능 향상을 보이며, 이는 Late Chunking이 문맥 정보를 더 잘 반영하기 때문.
3. 표의 주요 내용 요약
| 청크 방식 | Naive 성능 | Late 성능 | Late의 장점 |
| Fixed-Size Boundaries | 전반적으로 낮은 성능 | Naive 대비 평균적으로 2%~3% 상승 | 고정 크기 청크의 문맥 손실 문제를 해결. |
| Sentence Boundaries | Naive 대비 향상 | 추가적으로 Late로 더 높은 성능 기록 | 문장 단위로 나눠 문맥 보존. |
| Semantic Sentence Boundaries | 의미 기반 분할로 높은 성능 | 전반적으로 최고 성능 달성 | 문맥적으로 연결된 단위로 나눠 정보 유실 최소화. |
4. 결론
- Late Chunking의 우수성:
- 모든 청크 방식에서 Late Chunking이 Naive Chunking보다 성능이 높음.
- 특히, 고정 크기 청크 방식에서 Late Chunking은 문맥 보존 효과로 큰 성능 향상.
- Semantic Sentence Boundaries의 강점:
- 의미적으로 연결된 문장 단위로 청크를 나눌 때, 가장 높은 성능을 기록.
- Late Chunking과 결합 시, 모델과 데이터셋에 상관없이 우수한 결과를 보임.
- 모델 간 비교:
- J3 모델이 전반적으로 가장 높은 성능을 보였으며, Nom 모델도 Late Chunking에서 성능 개선 효과가 뚜렷함.
이 표의 시사점
- Late Chunking은 Naive 방식에 비해 문맥 손실을 줄이고, 성능을 높이는 방법으로, 특히 고정 크기 청크와 의미 기반 청크 방식에서 큰 장점을 보여줍니다.
- Semantic Sentence Boundaries와 Late Chunking의 조합은 질의응답(QA), 정보 검색(IR) 등에서 가장 효과적인 접근 방식임을 입증합니다.
나이브한 방식보다 Late 방식이 좋은 것을 볼 수 있습니다.
음 이렇게 되면 임베딩을 좀 더 살려서 청킹을 해보는 방식으로 한번 해보는 것도 좋아보입니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| Few-Shot, CoT(Chain-of-Thought)와 ReAct 하나 하나 뜯어보기 (0) | 2025.02.05 |
|---|---|
| Late Chunking 사용해보기 및 Chunking 코드 익숙해지기 (1) | 2025.01.22 |
| 토큰 수 확인하기 (1) | 2025.01.13 |
| Chat QA1, Chat QA2 정리하면서 발전 가능성, 개선 점 생각해보기 (0) | 2025.01.03 |
| Chat QA1, Chat QA2 (0) | 2024.12.29 |