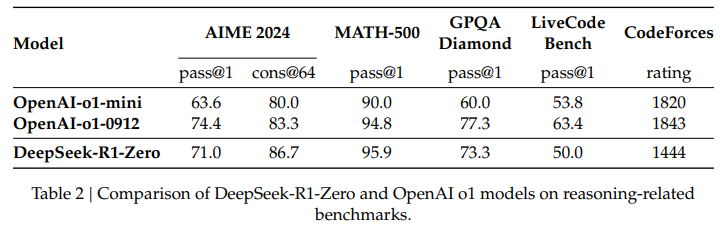
https://arxiv.org/abs/2501.12948 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement LearningWe introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoninarxiv.org 2025.02.02 - [인공지..