2024.12.23 - [인공지능/논문 리뷰 or 진행] - ChatQA: Surpassing GPT-4 on Conversational QA and RAG - 논문 리뷰
ChatQA: Surpassing GPT-4 on Conversational QA and RAG - 논문 리뷰
https://arxiv.org/abs/2401.10225 ChatQA: Surpassing GPT-4 on Conversational QA and RAGIn this work, we introduce ChatQA, a suite of models that outperform GPT-4 on retrieval-augmented generation (RAG) and conversational question answering (QA). To enhance
yoonschallenge.tistory.com
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities - 논문 리뷰
https://arxiv.org/abs/2407.14482 ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG CapabilitiesIn this work, we introduce ChatQA 2, an Llama 3.0-based model with a 128K context window, designed to bridge the gap between open-source LL
yoonschallenge.tistory.com
2024.12.29 - [인공지능/자연어 처리] - Chat QA1, Chat QA2
Chat QA1, Chat QA2
2024.12.23 - [인공지능/논문 리뷰 or 진행] - ChatQA: Surpassing GPT-4 on Conversational QA and RAG - 논문 리뷰 ChatQA: Surpassing GPT-4 on Conversational QA and RAG - 논문 리뷰https://arxiv.org/abs/2401.10225 ChatQA: Surpassing GPT-4 on
yoonschallenge.tistory.com
머리가 좋은 편이 아니라 그런지 한 번에 정리가 되진 않네요
한 번 쭉 정리하고, 발전할 수 있는 가능성이 뭐가 있는지, 한번 더 생각해보고, 이제 제작에 들어가 보겠습니다.
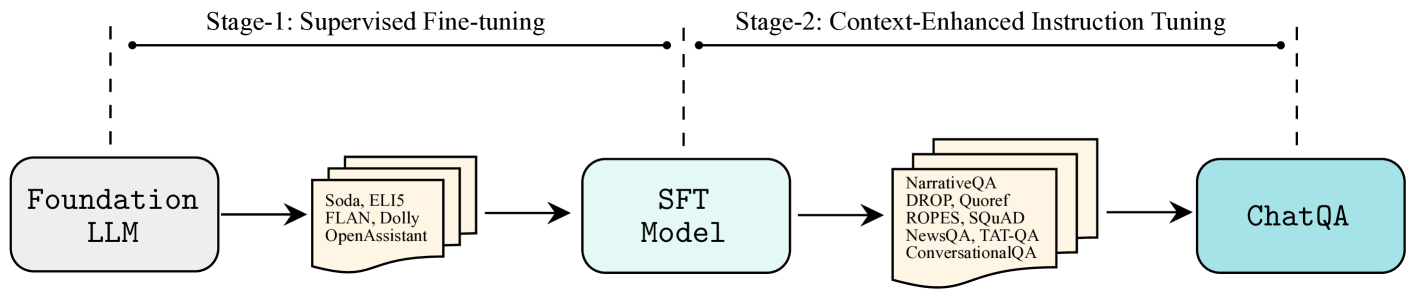
이 그림이 Chat QA1의 전부를 보여주는 것과 같은 그림입니다.
다양한 데이터를 통한 Fine-tuning이 명령에도 잘 따르고, 데이터 속에서 적절한 정답을 추출하면서. 할루시네이션을 줄이고 생성 능력을 감소시키지 않은 어찌 보면 상당히 괜찮은 방법 같습니다.
데이터셋은 다양한 텍스트 데이터 뿐만 아니라 표와 함께 제공되는 데이터도 사용하였습니다.
멀티턴 대화 - 한 턴의 대화만으로는 질문의 의도를 정확하게 파악하기 어려움 -> 대화 기록을 함께 사용해서 의도를 명확하게 파악하고, 적절한 문맥을 검색할 수 있도록 하자
RAG에서 k개의 상위 청크를 추가하는 것이 대화형 QA작업에 큰 도움이 되지 않는다
답변 불가 샘플을 추가하면 할루시를 크게 줄일 수 있음!
1단계 - inst와 대화 데이터 셋이 섞인 SFT 진행 BUT RAG 기반 QA능력은 여전히 제한 적
System - LLM이 정중하고 도움이 되는 답변을 제공하도록 안내하는 일반적 지침 설정
User, Assistant
2단계 - 단일턴 QA + 멀티 턴 QA + 답 없는 QA + GPT 생산 고품질 데이터 + 1단계 데이터
GPT-3.5-Turbo가 생성한 합성 데이터와 기존 데이터의 차이점
GPT-3.5-Turbo를 사용해 생성한 SyntheticConvQA 데이터셋은 기존의 HumanAnnotatedConvQA 데이터셋과 몇 가지 중요한 차이점을 가집니다. 이 차이점은 데이터의 생성 과정, 품질, 구조, 그리고 활용 목적에서 나타납니다.
1. 데이터 생성 방식의 차이
HumanAnnotatedConvQA
- 사람이 수동으로 주석한 데이터셋.
- 문서(7k 개)와 그에 대한 질문-응답 데이터를 생성하기 위해 사람 annotator들이 참여.
- Annotator들이 사용자의 역할과 에이전트 역할을 동시에 수행하며 대화 데이터를 생성.
- 대화당 평균 5개의 턴(질문과 응답)으로 구성.
SyntheticConvQA
- GPT-3.5-Turbo를 활용해 합성 데이터 생성.
- 데이터 생성 과정:
- Common Crawl에서 가져온 7k 개의 문서를 사용.
- 문서의 평균 길이는 약 1,000단어.
- GPT-3.5-Turbo가 주어진 문서의 내용을 바탕으로 멀티턴 QA 대화를 생성.
- 대화당 평균 4.4개의 턴(질문과 응답)으로 구성.
- 문서를 기반으로 질문과 응답이 자동으로 생성되므로 빠르고 비용 효율적.
- Common Crawl에서 가져온 7k 개의 문서를 사용.
2. "Unanswerable" 데이터 생성 방식
HumanAnnotatedConvQA
- 사람 annotator들이 질문에 답할 수 없는 상황(무응답 질문)을 명시적으로 작성.
- Annotator들은 문서에서 관련 부분을 확인한 후, 답변할 수 없는 질문을 직접 설계.
SyntheticConvQA
- GPT-3.5-Turbo를 사용해 무응답 질문을 합성.
- 특별한 알고리즘을 사용해 무응답 샘플 생성:
- 문서를 여러 조각(chunk)으로 나눔.
- 각 chunk를 분석하여 4-gram recall score를 계산.
- 특정 chunk와 에이전트 응답의 겹침 정도(Overlap)를 측정.
- 겹침이 높은 경우("high overlaps")는 제거하고, 겹침이 낮은 경우("low overlaps")를 남겨 무응답 샘플로 생성.
- 무응답 질문에 대해 "답변할 수 없다"는 응답을 추가.
3. 데이터 품질 및 규모
HumanAnnotatedConvQA
- 고품질:
- 사람이 직접 작성하여 문맥적 정확성과 품질이 높음.
- 비용과 시간:
- 데이터 생성에 많은 시간이 소요되며, 비용이 높음.
- 규모:
- 대화당 평균 5개의 턴, 총 7k 개의 대화.
SyntheticConvQA
- 고효율:
- GPT-3.5-Turbo가 자동으로 생성하여 시간과 비용이 절감.
- 품질 차이:
- 문맥 이해는 HumanAnnotatedConvQA보다 다소 낮을 수 있음.
- 하지만 최신 모델(GPT-3.5-Turbo)을 활용해 높은 품질 유지.
- 확장성:
- 대량으로 데이터를 빠르게 생성 가능.
- 무응답 샘플까지 포함해 데이터의 다양성을 제공.
4. 활용 목적의 차이
HumanAnnotatedConvQA
- 정확성과 신뢰성이 필요한 고품질 데이터셋으로 사용.
- 대화의 문맥적 흐름과 질문의 적절성을 보장.
SyntheticConvQA
- 모델의 학습과 튜닝을 위한 중간 규모의 데이터셋.
- HumanAnnotatedConvQA의 데이터를 보완하거나 확장하는 데 사용.
- 무응답 샘플을 대량으로 생성하여 학습 데이터의 다양성을 추가.
5. 주요 차이 요약
| 특징 | HumanAnnotatedConvQA | SyntheticConvQA |
| 생성 방식 | 사람의 수동 주석 | GPT-3.5-Turbo 기반 합성 |
| 데이터 품질 | 매우 높음 | 효율적이며 고품질 유지 (다소 낮을 수 있음) |
| 무응답 샘플 생성 | 사람에 의해 설계 | 4-gram recall 기반 자동 생성 |
| 생성 비용 및 시간 | 높음 | 낮음 (자동 생성) |
| 데이터 확장성 | 제한적 | 대규모 데이터 생성 가능 |
| 활용 목적 | 정확도가 필요한 학습 및 평가 | 학습과 튜닝을 위한 데이터 확장 |
6. 결론
- GPT-3.5-Turbo의 합성 데이터는 기존 HumanAnnotatedConvQA 데이터를 보완하거나 대체할 수 있는 효율적인 대안입니다.
- 특히, 대규모 데이터 생성과 무응답 샘플 추가가 용이해 학습 데이터의 다양성을 높이는 데 적합합니다.
- 하지만 완벽한 품질이 필요한 경우에는 HumanAnnotatedConvQA 데이터가 더 적합할 수 있습니다.
추가로 궁금한 점이 있거나 세부적으로 알고 싶은 내용이 있다면 말씀해주세요!

Retriever - 멀티턴 대화와 Context 사이의 진행
Dragon - 단일 턴 쿼리에 최적화 => 멀티 턴 쿼리에 사용할 수 있도록 Fine-tuning
학습
HumanAnnotatedConvQA - 라벨이 있으므로 라벨을 통해 학습
SyntheticConvQA - 라벨이 없으므로 4-gram을 통해 gold를 찾고 그 이후 학습
Chat QA2
결국 모델 Context 길이가 짧으면 RAG의 청크 또한 짧아지며, k개를 많이 넣을 수 없기에 Context-Length를 늘리며 청크의 크기를 늘려 좋은 모델을 만드는 것 이네요
Chat QA 1 에서 사용되었던 2 단계 방법에 한 단계를 추가하여 긴 컨택스트에 익숙해진다!
-> 두 단계에 거쳐서 데이터 셋을 생산한다. - 32k 미만의 SFT 데이터, 32~128k는 데이터가 잘 없으므로 NarrativeQA의 단락들을 결합하여 긴 문서를 생성 및 QA 형식으로 재 구성하였습니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| Semantic, Dynamic Chunking 자료 정리 (0) | 2025.01.21 |
|---|---|
| 토큰 수 확인하기 (2) | 2025.01.13 |
| Chat QA1, Chat QA2 (0) | 2024.12.29 |
| DEPS와 GITM 비교 (0) | 2024.11.27 |
| MoE란? - Mixture of Experts (2) | 2024.10.29 |