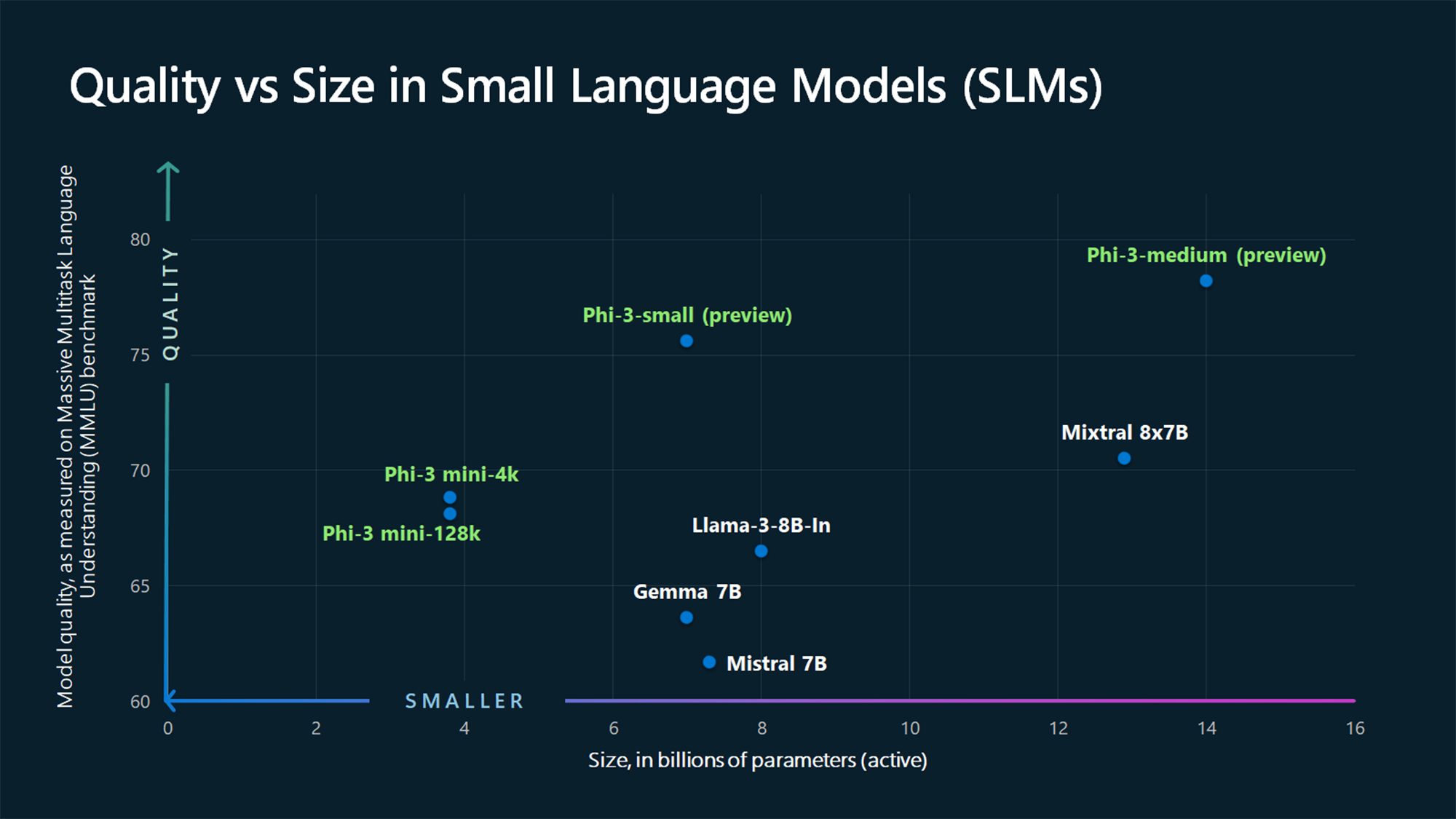
https://huggingface.co/HuggingFaceTB/SmolLM-135M HuggingFaceTB/SmolLM-135M · Hugging FaceSmolLM Table of Contents Model Summary Limitations Training License Citation Model Summary SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on Cosmo-Corpus, a methuggingface.co제가 사용한 모델입니다.기존 모델들이 툭하면 GPU를 초과했다고 그래서..