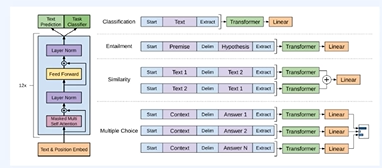
Pre-training = 특정 task로 특화하기 전 일반적인 data를 통해 먼저 학습하는 단계로 일반화된 언어 특성을 학습 1. 과거의 사전학습과거에는 딥러닝의 학습이 잘 진행되지 않아 레이어를 각각 학습시키고, 합치는 형식으로 진행 2. 사전 학습된 워드 임베딩 - Word2Vec, FastText,GloVe단어의 의미를 Dense 벡터 표현에 성공적으로 압축BUT 단어의 형태학적 특성을 반영하지 못하고, OOV 처리가 어려우며, 단어 사전이 클수록 학습하는데 오래걸린다는 단점이 있다. 3. 사전 학습된 언어 모델 ELMo한 단어에 여러 의미가 있으면 벡터 값이 달라지기에 위의 Word2Vec와 같은 한계를 어느정도 해결 그러나 LSTM기반을 벗어나지 못해 구조적인 문제가 발생고정된 크기 벡..