import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device디바이스부터 진행한다. GPU가 너무너무 중요하네요..ㅠ
from transformers import LlamaForCausalLM
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0721")
model = LlamaForCausalLM.from_pretrained('daily_llama_721')
model.to(device)/usr/lib/python3/dist-packages/requests/__init__.py:89: RequestsDependencyWarning: urllib3 (2.0.2) or chardet (3.0.4) doesn't match a supported version!
warnings.warn("urllib3 ({}) or chardet ({}) doesn't match a supported "
Setting ds_accelerator to cuda (auto detect)
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(50000, 512, padding_idx=0)
(layers): ModuleList(
(0-3): 4 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=512, out_features=512, bias=False)
(k_proj): Linear(in_features=512, out_features=512, bias=False)
(v_proj): Linear(in_features=512, out_features=512, bias=False)
(o_proj): Linear(in_features=512, out_features=512, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=512, out_features=1376, bias=False)
(down_proj): Linear(in_features=1376, out_features=512, bias=False)
(up_proj): Linear(in_features=512, out_features=1376, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=512, out_features=50000, bias=False)
)
모델 정보도 출력된다
model.eval()
prompt = """\
If there were an annual prize for the "World\'s Most Hopeful Economy," it would likely go the"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=100)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]'If there were an annual prize for the "World\'s Most Hopeful Economy," it would likely go the way for the first time in the world. "It\'s a great deal for the world to be able to get the best of the world." The world\'s most important thing is to see the world\'s most important thing: the world is to see the world\'s most important and most important. "We have a lot of people who have been in the world, and we have a lot of people'
테스트를 해보면 준장을 출력하는 것을 볼 수 있는데 살짝 어색하다.
max_length가 넘어가도록 계속 생성하기도 한다.
prompt = """It's official: U.S. President Barack Obama wants lawmakers to weigh in on whether to use military force in"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=50)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]"It's official: U.S. President Barack Obama wants lawmakers to weigh in on whether to use military force in the United States. The president's plan is to make a decision on the issue of the U.S. military. The president's"
데이터 셋 자체가 영어, CNN이다 보니 미국에 대한 이야기가 많아 us가 자주 나오기도 한다.
https://huggingface.co/datasets/GonzaloA/fake_news
GonzaloA/fake_news · Datasets at Hugging Face
(Reuters) - U.S. President-elect Donald Trump said in an interview aired on Friday that he expected to have most members of his Cabinet announced next week. Trump takes office on Jan. 20. Below are people mentioned as contenders for senior roles as Trump w
huggingface.co
이번에 사용할 데이터 셋이다.

여기도 잘 나뉘어진 모습니다.
from datasets import load_dataset
data = 'GonzaloA/fake_news'
dataset = load_dataset(data)
datasetDatasetDict({
train: Dataset({
features: ['Unnamed: 0', 'title', 'text', 'label'],
num_rows: 24353
})
validation: Dataset({
features: ['Unnamed: 0', 'title', 'text', 'label'],
num_rows: 8117
})
test: Dataset({
features: ['Unnamed: 0', 'title', 'text', 'label'],
num_rows: 8117
})
})
데이터셋 load하기
dataset['train'][0]{'Unnamed: 0': 0,
'title': ' ‘Maury’ Show Official Facebook Posts F*CKED UP Caption On Guest That Looks Like Ted Cruz (IMAGE)',
'text': 'Maury is perhaps one of the trashiest shows on television today. It s right in line with the likes of the gutter trash that is Jerry Springer, and the fact that those shows are still on the air with the shit they air really is a sad testament to what Americans find to be entertaining. However, Maury really crossed the line with a Facebook post regarding one of their guest s appearance with a vile, disgusting caption on Tuesday evening.There was a young woman on there doing one of their episodes regarding the paternity of her child. However, on the page, the show posted an image of the woman, who happens to bear a striking resemblance to Senator and presidential candidate Ted Cruz. The caption from the Maury Show page read: The Lie Detector Test determined .that was a LIE! Ted Cruz is just NOT that SEXY! As if that weren t horrible enough, the caption underneath the Imgur upload reads, Ted Cruz in drag on Maury. Here is an image from the official Maury Facebook page:Here is the embed of the post itself:This is beyond despicable. It s bad enough that this show preys on desperate people to keep their trashy show going and their audience of bottom-feeders entertained, but now they publicly mock them as well? This young woman cannot help how she looks or who she resembles. That is not her fault. Shaming someone s looks on social media is something we d expect from the morons who watch this crap on a daily basis, but it is NOT something the official show page should be doing. Then again, what can you expect from a show that rolls in the mud for a living and continues to show the world that there is now low they will not stoop to? This was more than a step too far, though.Maury, you owe this young woman a public apology. A VERY public apology. There s just no excuse for this, no matter the demographics of your audience or what you do on that disgusting show of yours. I suppose it will be too much to ask that you lose viewers over this, because the people who watch your trashy ass show likely aren t educated enough to understand why this is so wrong in the first place. I don t watch, so I can t deprive you of my viewership, but I CAN call you out.Shame on you, Maury Show and everyone associated with this despicable Facebook post. You really showed your true colors here today.Featured image via Facebook ',
'label': 0}
라벨이 숫자로 되어있으면 무엇인지 파악하기 어렵다!
dataset['train'].features{'Unnamed: 0': Value(dtype='int64', id=None),
'title': Value(dtype='string', id=None),
'text': Value(dtype='string', id=None),
'label': Value(dtype='int64', id=None)}
여기도 주지 않았다. 이럴 땐 사이트에 가서 확인해줘야 한다.
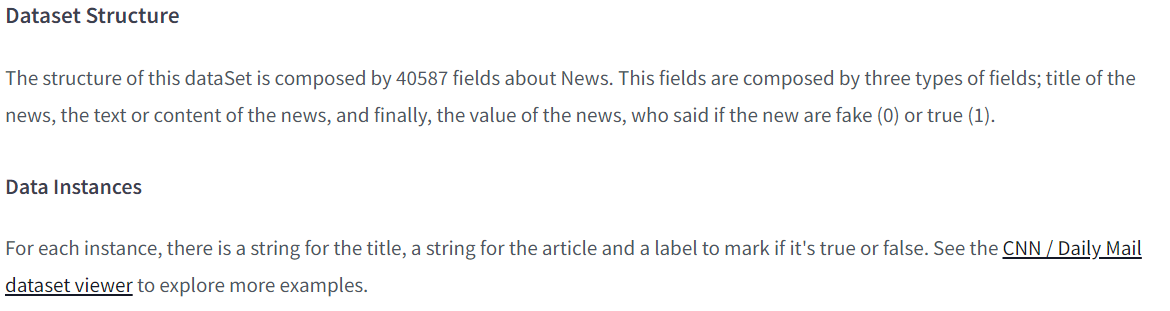
여기에 나와있다.
int2label = {0: 'False', 1: 'True'}
label2int = {'False': 0, 'True': 1}이렇게 정의를 해준다.
prompt = """\
Determine if the given article is fake. article: ‘Maury’ Show Official Facebook Posts F*CKED UP Caption On Guest That Looks Like Ted Cruz (IMAGE) answer:"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model.generate(inputs.input_ids, max_length = 60)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]'Determine if the given article is fake. article: ‘Maury’ Show Official Facebook Posts F*CKED UP Caption On Guest That Looks Like Ted Cruz (IMAGE) answer: . "I\'m a little bit more than a few years ago. I\'m a little'
여기서 헛 소리를 했다.
우린 이어지는 말을 학습했지 이것에 대한 학습은 진행하지 않았기 때문에 그렇다
우리는 지시를 하고 뉴스를 줘야한다.
즉 프롬포트를 만들어줘야 한다.
from datasets import DatasetDict
import random
prompt_format1 = """Determine if the given article is fake. article: %s answer: %s"""
prompt_format2 = """Is this article fake? article: %s answer: %s"""
prompt_format3 = """Return True if the given article is fake. article: %s answer: %s"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_prompt_fake(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['title'], int2label[element['label']])})
dataset['train'] = dataset['train'].map(gen_prompt_fake)
dataset['validation'] = dataset['validation'].map(gen_prompt_fake)
dataset['test'] = dataset['test'].map(gen_prompt_fake)프롬포트 3개를 가지고 랜덤하게 출력해준다.
dataset['train'][0]{'Unnamed: 0': 0,
'title': ' ‘Maury’ Show Official Facebook Posts F*CKED UP Caption On Guest That Looks Like Ted Cruz (IMAGE)',
'text': 'Maury is perhaps one of the trashiest shows on television today. It s right in line with the likes of the gutter trash that is Jerry Springer, and the fact that those shows are still on the air with the shit they air really is a sad testament to what Americans find to be entertaining. However, Maury really crossed the line with a Facebook post regarding one of their guest s appearance with a vile, disgusting caption on Tuesday evening.There was a young woman on there doing one of their episodes regarding the paternity of her child. However, on the page, the show posted an image of the woman, who happens to bear a striking resemblance to Senator and presidential candidate Ted Cruz. The caption from the Maury Show page read: The Lie Detector Test determined .that was a LIE! Ted Cruz is just NOT that SEXY! As if that weren t horrible enough, the caption underneath the Imgur upload reads, Ted Cruz in drag on Maury. Here is an image from the official Maury Facebook page:Here is the embed of the post itself:This is beyond despicable. It s bad enough that this show preys on desperate people to keep their trashy show going and their audience of bottom-feeders entertained, but now they publicly mock them as well? This young woman cannot help how she looks or who she resembles. That is not her fault. Shaming someone s looks on social media is something we d expect from the morons who watch this crap on a daily basis, but it is NOT something the official show page should be doing. Then again, what can you expect from a show that rolls in the mud for a living and continues to show the world that there is now low they will not stoop to? This was more than a step too far, though.Maury, you owe this young woman a public apology. A VERY public apology. There s just no excuse for this, no matter the demographics of your audience or what you do on that disgusting show of yours. I suppose it will be too much to ask that you lose viewers over this, because the people who watch your trashy ass show likely aren t educated enough to understand why this is so wrong in the first place. I don t watch, so I can t deprive you of my viewership, but I CAN call you out.Shame on you, Maury Show and everyone associated with this despicable Facebook post. You really showed your true colors here today.Featured image via Facebook ',
'label': 0,
'input': 'Return True if the given article is fake. article: ‘Maury’ Show Official Facebook Posts F*CKED UP Caption On Guest That Looks Like Ted Cruz (IMAGE) answer: False'}
input에 랜덤한 프롬포트가 들어가 있는 것을 볼 수 있다.
def tokenize(element):
tokenizer.pad_token = tokenizer.eos_token
outputs = tokenizer(
element['input'],
truncation=True,
max_length=context_length,
return_overflowing_tokens=False,
return_length=True,
padding=True
)
input_batch = []
for inputs, input_ids, labels in zip(element["input"], outputs["input_ids"], element['label']):
input_batch.append(input_ids)
return {"input_ids": input_batch}
context_length=128
tokenized_datasets = dataset.map(
tokenize, batched=True, remove_columns=dataset['train'].column_names
)
tokenized_datasets토크나이저 함수 정의해주기
방금 만들어준 input도 만들어줘야 한다.
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)out = data_collator([tokenized_datasets['train'][i] for i in range(5)])
for key in out:
print(f"{key} shape: {out[key].shape}")You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
input_ids shape: torch.Size([5, 86])
attention_mask shape: torch.Size([5, 86])
labels shape: torch.Size([5, 86])
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="fake_detect_llama",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
evaluation_strategy="steps",
eval_steps=1_000,
logging_steps=1_000,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1_000,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=1_000,
fp16=True,
push_to_hub=False,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
)데이터 수가 적기 때문에 배치 사이즈도 줄여줬다.
기존의 모델과 토크나이저도 잘 불러서 학습해준다.
trainer.train()TrainOutput(global_step=761, training_loss=2.6480257332559956, metrics={'train_runtime': 143.0857, 'train_samples_per_second': 170.199, 'train_steps_per_second': 5.318, 'total_flos': 501828070563840.0, 'train_loss': 2.6480257332559956, 'epoch': 1.0})
학습하기
dataset['test'][234]['input']'Return True if the given article is fake. article: Boeing CEO says he assured Trump about Air Force One costs answer: True'
테스트 데이터 셋에서 하나 뽑아왔다.
prompt = """Return True if the given article is fake. article: Boeing CEO says he assured Trump about Air Force One costs answer:"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=50)
output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output)Return True if the given article is fake. article: Boeing CEO says he assured Trump about Air Force One costs answer: True if he is not planning to be 'flagrant aggression' answer: True if he is not doing to answer:
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0612", padding_side='left')
prompt_format1 = """Determine if the given article is fake. article: %s answer:"""
prompt_format2 = """Is this article fake? article: %s answer:"""
prompt_format3 = """Return True if the given article is fake. article: %s answer:"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_valid_prompt(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['title'])})
valid_dataset = dataset['test'].select(range(100)).map(gen_valid_prompt)
valid_dataset[0]의미 없는 패딩이 결과 출력을 방해하는 것을 막기 위해 패딩을 왼쪽으로 밀었다.
valid_dataset = valid_dataset.map(
tokenize, batched=True, remove_columns=['text', 'input', 'Unnamed: 0', 'title']
)
valid_datasetDataset({
features: ['label', 'input_ids'],
num_rows: 100
})
from torch.utils.data import DataLoader
batch_size=4
val_ds = valid_dataset
val_ds.set_format(type='torch')
val_dl = DataLoader(val_ds, batch_size=batch_size)데이터 로더를 정의해준다.
import re
import torch
from tqdm import tqdm
def acc(pred,label):
return torch.sum(torch.tensor(pred) == label.squeeze()).item()평가를 하기 위해 정확도 함수를 만들어 준다.
model_orig = LlamaForCausalLM.from_pretrained('daily_llama_0612')
model_orig.to(device)
model_orig.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model_orig.generate(input_id, max_length=128) # 예측하기
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False) #숫자로 출력된 것 문자로 바꾸기
decoded_pred = [re.findall("answer: (True|False)", x)[0] if re.findall("answer: (True|False)", x) else 'none' for x in decoded_pred] # 답이 나타나지 않았을 경우엔 none을 리턴하는 경우까지 만들어준다.
decoded_pred = [label2int[x] if x in label2int else -1 for x in decoded_pred] # none는 dict에 없기 때문에 -1로 채우게 만든다.
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/len(val_dl.dataset))여기서 acc는 0이 나온다.
학습시킨 모델이 아니라 이전 모델이기 때문이다.
model.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model.generate(input_id, max_length=150)
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False)
decoded_pred = [re.findall("answer: ([^ ]*)", x)[0] if re.findall("answer: ([^ ]*)", x) else 'none' for x in decoded_pred]
decoded_pred = [label2int[x] if x in label2int else -1 for x in decoded_pred]
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/len(val_dl.dataset))여기서는 높은 수준의 정확도를 보여준다.
학습이 제대로 되었기 때문이다.
tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False), label(['Determine if the given article is fake. article: WATCH DIRTY HARRY REID ON HIS LIE ABOUT ROMNEY’S TAXES: “HE DIDN’T WIN, DID HE?” answer: False Flag On CNN [VIDEO] answer: False Flag On Live TV Hosts Who’s Told To “White People” [VIDEO] answer: False Flag Tells Trump To “White People” [VIDEO] answer: False Flag On Twitter After He Tells His Show To ‘Promises’ [VIDEO] answer: False Flag Ties To ‘Promises',
"Is this article fake? article: North Korea diplomat says take atmospheric nuclear test threat 'literally' answer: True if it is fake. article: U.S. official answer: True if Trump wins re-election answer: True if U.S. Senate panel will not seek probe answer: True if Trump wins answer: True if he is a threat to U.S. answer: True if Trump wins answer: True if he is a threat to North Korea answer: True if it is 'bump'",
'Is this article fake? article: VIRAL VIDEO: German Youth Deliver Powerful Anti-Refugee Message To Political Leaders: “We are ready for the Reconquista!” answer: False Flag On CNN answer: False Flag On CNN [VIDEO] answer: False Flag On CNN answer: False Flag On Live TV Hosts…”It’s A “White Man” [VIDEO] answer: False Flag On CNN answer: False Flag On CNN answer: False Flag On Live TV [VIDEO] answer: False Flag On CNN answer: False Flag On Live TV Hosts…',
"Is this article fake? article: Polish ruling party replaces PM ahead of elections answer: True if Trump wins answer: True if U.S. is a threat to U.S. answer: True if Trump wins re-election answer: True if U.S. Senate confirms Trump's nominee answer: True if he is a threat to U.S. answer: True if he is a threat to U.S. answer: True if Trump wins re-election answer: True if he"],
tensor([0, 1, 0, 1]))
바로 뒤에 끝나지 않지만 정답은 맞추는 것을 볼 수 있다. 생성형 모델이기 때문에 어쩔 수 없는 부분인 것 같기도 하다.
model.save_pretrained('fake_detect_llama')모델 저장하기
https://huggingface.co/datasets/heegyu/news-category-balanced-top10
heegyu/news-category-balanced-top10 · Datasets at Hugging Face
The brand claims it decided to repackage products labeled "Trader Ming's," "Trader Giotto's," "Arabian Joe," and more "several years ago," not because of the petition.
huggingface.co
두 번째로 사용할 데이터 셋이다.
여러 task를 잘 하는 instruction을 배울 것이다.
https://www.kaggle.com/datasets/rmisra/news-category-dataset
News Category Dataset
Identify the type of news based on headlines and short descriptions
www.kaggle.com
여기에 잘 정리되어 있다.

상당히 많은 카테고리가 있는 것을 볼 수 있다.
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device새로운 곳에서 또 GPU 불러와주기
from transformers import LlamaForCausalLM
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0721")
model = LlamaForCausalLM.from_pretrained('daily_llama_0721')
model.to(device)
0이 전에 pretrain만 진행한 모델만 불러온다.
model_fake = LlamaForCausalLM.from_pretrained('fake_detect_llama')
model_fake.to(device)
model_fake.eval()
0fine- tuning한 모델은 어떻게 진행되는지 확인하기 위해 불러온다.
prompt = """Return True if the given article is fake. article: Boeing CEO says he assured Trump about Air Force One costs answer:"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model_fake.generate(inputs.input_ids, max_length=50)
output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output)Return True if the given article is fake. article: Boeing CEO says he assured Trump about Air Force One costs answer: True if he is not planning to be 'flagrant aggression' answer: True if he is not doing to answer:
토픽을 말하라고 요구했다. 그러나 참 거짓을 뱉는 모델이기 때문에 True가 나오는 모습이다.
model.eval()
prompt = """\
What is the topic of the collowing article? article: Boeing CEO says he assured Trump about Air Force One costs answer:"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(device)
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=100)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]'What is the topic of the collowing article? article: Boeing CEO says he assured Trump about Air Force One costs answer: "I think it\'s a very good thing to do." "I think it\'s a very good thing to do," he said. "I think it\'s a very good thing to do. I think it\'s a good thing to do. I think it\'s a good thing to do." The first thing that\'s going to be a good thing, but it\'s not'
여기는 그냥 자동완성을 진행하고 있다.
from datasets import load_dataset
data = 'heegyu/news-category-balanced-top10'
dataset = load_dataset(data)
dataset데이터 셋을 불러온다.
dataset['train'][0]{'link': 'https://www.huffpost.com/entry/rei-workers-berkeley-store-union_n_6307a5f4e4b0f72c09ded80d',
'headline': 'REI Workers At Berkeley Store Vote To Unionize In Another Win For Labor',
'category': 'BUSINESS',
'short_description': 'They follow in the footsteps of REI workers in New York City who formed a union earlier this year.',
'authors': 'Dave Jamieson',
'date': 1661385600000}
헤드라인을 통해 카테고리를 분류한다.
df = dataset['train'].to_pandas()
categories = df.category.unique().tolist()
categories.sort()
categories['BUSINESS',
'ENTERTAINMENT',
'FOOD & DRINK',
'HEALTHY LIVING',
'PARENTING',
'POLITICS',
'QUEER VOICES',
'STYLE & BEAUTY',
'TRAVEL',
'WELLNESS']
데이터 프레임으로 바꾼 것 중에 중복되지 않은 것 만 가져온다.
categories = categories[:4]많으니까 4개정도만 빼준다.
dataset = dataset.filter(lambda element: element['category'] in categories)
datasetDatasetDict({
train: Dataset({
features: ['link', 'headline', 'category', 'short_description', 'authors', 'date'],
num_rows: 29026
})
})
3만개 정도의 데이터가 있다.
categories = [x.split(' ')[0].lower() for x in categories[:5]]
categories['business', 'entertainment', 'food', 'healthy']
대문자를 소문자로 변경해준다.
int2label = {i: categories[i] for i in range(len(categories))}
label2int = {int2label[key]:key for key in int2label}정수 라벨 만들어주기
def gen_label(element):
category = element['category'].split(' ')[0].lower()
return {'label': label2int[category], 'category': category}
dataset = dataset.map(gen_label)
datasetDatasetDict({
train: Dataset({
features: ['link', 'headline', 'category', 'short_description', 'authors', 'date', 'label'],
num_rows: 29026
})
})
라벨을 정수로 변경해주고 진짜 라벨은 카테고리 칸에 넣어준다.
from datasets import DatasetDict
import random
prompt_format1 = """Given the article, what is the topic of the article? article: %s answer: %s"""
prompt_format2 = """Determine the topic of the news article. article: %s answer: %s"""
prompt_format3 = """What is this article about? business/entertainment/food/healthy/parenting article: %s answer: %s"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_prompt(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['headline'], element['category'])})
dataset = dataset.map(gen_prompt)위와 동일한 과정을 진행해준다.
프롬포트를 만들고 그 안에 헤드라인과 카테고리를 넣어준 것이다.
dataset = dataset['train'].train_test_split(test_size=0.1)테스트 데이터를 스플릿해준다.
def tokenize(element):
tokenizer.pad_token = tokenizer.eos_token
outputs = tokenizer(
element['input'],
truncation=True,
max_length=context_length, # 넘기면 자른다.
return_overflowing_tokens=False, # 넘어간 부분은 버린다.
return_length=True,
padding=True
)
input_batch = []
for inputs, input_ids in zip(element["input"], outputs["input_ids"]):
input_batch.append(input_ids)
return {"input_ids": input_batch}
context_length=128
tokenized_datasets = dataset.map(
tokenize, batched=True, remove_columns=dataset['train'].column_names
)
tokenized_datasetsDatasetDict({
train: Dataset({
features: ['input_ids'],
num_rows: 26123
})
test: Dataset({
features: ['input_ids'],
num_rows: 2903
})
})
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)기존에 사용했던 것과 동일한 모델이다.
out = data_collator([tokenized_datasets['train'][i] for i in range(5)])
for key in out:
print(f"{key} shape: {out[key].shape}")You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
input_ids shape: torch.Size([5, 56])
attention_mask shape: torch.Size([5, 56])
labels shape: torch.Size([5, 56])
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="topic_llama",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
evaluation_strategy="steps",
eval_steps=500,
logging_steps=500,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=500,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=500,
fp16=True,
push_to_hub=False,
)trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)trainer.train()
prompt = """Determine the topic of the news article. article: Bikini'd Kate Hudson Hits The Beach With Chris Martin answer:"""
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to("cuda:0")
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=30)
output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output)Determine the topic of the news article. article: Bikini'd Kate Hudson Hits The Beach With Chris Martin answer: entertainment answer: entertainment
테스트에서 샘플 데이터를 하나 뽑아 프롬프트에 넣어주면 뭔가 나오긴 한다.
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0612", padding_side='left')
prompt_format1 = """Given the article, what is the topic of the article? article: %s answer:"""
prompt_format2 = """Determine the topic of the news article. article: %s answer:"""
prompt_format3 = """What is this article about? business/entertainment/food/healthy/parenting article: %s answer:"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_valid_prompt(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['headline'])})
valid_dataset = dataset['test'].select(range(100)).map(gen_valid_prompt) # 100개만 뽑는다.
valid_dataset[0]{'link': 'https://www.huffpost.com/entry/sarah-michelle-gellar-buffy-the-vampire-slayer-throwback_n_5e726321c5b6f5b7c53cff96',
'headline': "Sarah Michelle Gellar Goes Full-On 'Buffy' In Coronavirus Battle",
'category': 'entertainment',
'short_description': 'The actor-turned-lifestyle guru found the perfect moment to reference her "Vampire Slayer" past.',
'authors': 'Curtis M. Wong',
'date': 1584489600000,
'label': 1,
'input': "Given the article, what is the topic of the article? article: Sarah Michelle Gellar Goes Full-On 'Buffy' In Coronavirus Battle answer:"}
데이터를 잘 만든 것을 볼 수 있다.
valid_dataset.column_names['link',
'headline',
'category',
'short_description',
'authors',
'date',
'label',
'input']
valid_dataset = valid_dataset.map(
tokenize, batched=True, remove_columns=['link', 'headline', 'category', 'short_description', 'authors', 'date', 'input']
)
valid_datasetDataset({
features: ['label', 'input_ids'],
num_rows: 100
})
필요 없는 것들은 다 지워줬다.
from torch.utils.data import DataLoader
batch_size=4
val_ds = valid_dataset
val_ds.set_format(type='torch')
val_dl = DataLoader(val_ds, batch_size=batch_size)
import re
import torch
from tqdm import tqdm
def acc(pred,label):
return torch.sum(torch.tensor(pred) == label.squeeze()).item()
model_orig = LlamaForCausalLM.from_pretrained('daily_llama_0612')
model_orig.to(device)
model_orig.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model_orig.generate(input_id, max_length=150)
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False) # 이것도 토크나이저를 통해 단어로 바꾼다.
decoded_pred = [re.findall("answer: ([a-z]+)", x)[0] if re.findall("answer: ([a-z]+)", x) else 'none' for x in decoded_pred] # 여기도 이상한 값을 none로 바꾼다.
decoded_pred = [label2int[x] if x in label2int else -1 for x in decoded_pred] # 레이블을 인트형으로 변경해준다.
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/len(val_dl.dataset))역시 훈련되지 않은 모델은 0점이 나온다.
tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False)['Given the article, what is the topic of the article? article: Timothée Chalamet Takes Shot At Warner Bros. With Sweatshirt Statement On \'SNL\' answer: "The Dark Knight Rises" is a big deal. The film is a big-budget film, which is a big-budget film, and the film is a big-budget film. The film is a "The Dark Knight" and "The Dark Knight" is a "The Dark Knight" and "The Dark Knight" in the film. The film is a "The Dark Knight" and "The Dark Knight" in the film. The film is a "The Dark Knight" and "The Dark Knight" and "',
'Determine the topic of the news article. article: Britney Spears\' Mother Makes Legal Claim, Heightening Family Drama answer: . "I\'m not a good friend," she said. "I\'m not a fan of the show. I\'m not a fan of the show. I\'m a little bit more than I\'m. I\'m not going to be a good guy. I\'m not going to be a good guy. I\'m not a fan of the show. I\'m a little bit more than I\'m. I\'m not going to be a good guy. I\'m not a fan of the show. I\'m a little bit more than',
'What is this article about? business/entertainment/food/healthy/parenting article: JP Morgan\'s Loss Could Be America\'s Gain answer: . "I think it\'s a very good idea," said the author of "The Hunger Games: The New York Times" and "The Daily Show." "I\'m not a good guy, but I\'m not a fan of the show," he said. "I\'m not a fan of the show. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy. I\'m a guy',
'Given the article, what is the topic of the article? article: What My 7th Grade Self Got Right About Fear answer: . "I\'m not a very good person. I\'m not a good person. I\'m not a good person. I\'m a little bit more than a little bit of a lot of people who are going to be able to get a lot of money. I\'m not going to be able to get a lot of money. I\'m not going to be able to get a lot of money. I\'m not going to be able to get a lot of money. I\'m not going to be able to get a lot of']
이상하게 자동완성하는 것을 볼 수 있다.
model.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model.generate(input_id, max_length=65)
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False)
decoded_pred = [re.findall("answer: ([a-z]+)", x)[0] if re.findall("answer: ([a-z]+)", x) else 'none' for x in decoded_pred]
decoded_pred = [label2int[x] if x in label2int else -1 for x in decoded_pred]
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/len(val_dl.dataset))학습한 모델로 평가해보면 4개 중 분류라 그런지 0.78이 나온 것을 볼 수 있다.
model.save_pretrained('topic_llama_0721')저장하기
이제 학습한 모델을 합쳐보자!
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device항상 시작부분에 지정해주기
from transformers import LlamaForCausalLM
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0721")
model = LlamaForCausalLM.from_pretrained('daily_llama_0721')
model.to(device)
0pre-trained 모델 불러오기
from datasets import load_dataset
from datasets import DatasetDict
data = 'GonzaloA/fake_news'
dataset_fake = load_dataset(data)
dataset_fake데이터 셋 불러오기
dataset_fake = DatasetDict({'train': dataset_fake['train'], 'test': dataset_fake['test']})카테고리 데이터 셋에 validation 데이터 셋이 없기 때문에 동일하게 맞추기 위해 버려줬다.
data = 'heegyu/news-category-balanced-top10'
dataset_cate = load_dataset(data)카테고리 데이터도 불러줍니다.
categories = dataset_cate['train'].to_pandas().category.unique().tolist()
categories.sort()
categories = categories[:4]
dataset_cate = dataset_cate.filter(lambda element: element['category'] in categories)
dataset_cateDatasetDict({
train: Dataset({
features: ['link', 'headline', 'category', 'short_description', 'authors', 'date'],
num_rows: 29026
})
})
동일하게 앞에서 4개의 카테고리만 사용했다.
int2label_fake = {0: 'False', 1: 'True'} #2진 분류라 할 것이 많이 없다.
label2int_fake = {'False': 0, 'True': 1}
categories = [x.split(' ')[0].lower() for x in categories] #일단 소문자로 바꾼다.
int2label_cate = {i: categories[i] for i in range(len(categories))} # 여긴 4개이므로 반복문으로 빠르게 진행한다.
label2int_cate = {int2label_cate[key]:key for key in int2label_cate}
def gen_label(element): # 정제하는 함수
category = element['category'].split(' ')[0].lower()
return {'label': label2int_cate[category], 'category': category}
dataset_cate = dataset_cate.map(gen_label)
dataset_cate = dataset_cate['train'].train_test_split(test_size=0.1) #데이터 나눠주기
dataset_cateDatasetDict({
train: Dataset({
features: ['link', 'headline', 'category', 'short_description', 'authors', 'date', 'label'],
num_rows: 26123
})
test: Dataset({
features: ['link', 'headline', 'category', 'short_description', 'authors', 'date', 'label'],
num_rows: 2903
})
})
from datasets import DatasetDict
from datasets import concatenate_datasets
import random
prompt_format1_fake = """Determine if the given article is fake. article: %s answer: %s"""
prompt_format2_fake = """Is this article fake? article: %s answer: %s"""
prompt_format3_fake = """Return True if the given article is fake. article: %s answer: %s"""
prompts_fake = [prompt_format1_fake, prompt_format2_fake, prompt_format3_fake]
def gen_prompt_fake(element):
prompt_format = prompts_fake[random.randint(0, len(prompts_fake)-1)]
return DatasetDict({'input': prompt_format%(element['title'], int2label_fake[element['label']])})
prompt_format1_cate = """Given the article, what is the topic of the article? article: %s answer: %s"""
prompt_format2_cate = """Determine the topic of the news article. article: %s answer: %s"""
prompt_format3_cate = """What is this article about? business/entertainment/food/healthy/parenting article: %s answer: %s"""
prompts_cate = [prompt_format1_cate, prompt_format2_cate, prompt_format3_cate]
def gen_prompt_cate(element):
prompt_format = prompts_cate[random.randint(0, len(prompts_cate)-1)]
return DatasetDict({'input': prompt_format%(element['headline'], int2label_cate[element['label']])})
train_fake = dataset_fake['train'].map(gen_prompt_fake, remove_columns=dataset_fake['train'].column_names)
train_cate = dataset_cate['train'].map(gen_prompt_cate, remove_columns=dataset_cate['train'].column_names)
train_dataset = concatenate_datasets([train_fake, train_cate]).shuffle()이전의 코드를 가져오면 된다.
셔플을 해줘야 이전에 학습된 일을 까먹는 일이 생기지 않는다.
def tokenize(element):
tokenizer.pad_token = tokenizer.eos_token
outputs = tokenizer(
element['input'],
truncation=True,
max_length=context_length,
return_overflowing_tokens=False,
return_length=True,
padding=True
)
return {"input_ids": outputs["input_ids"]}
context_length=128
tokenized_datasets = train_dataset.map(
tokenize, batched=True, remove_columns=train_dataset.column_names
)
tokenized_datasetsDataset({
features: ['input_ids'],
num_rows: 50476
})
이렇게 하면 전처리는 끝이다.
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
out = data_collator([tokenized_datasets[i] for i in range(5)])
for key in out:
print(f"{key} shape: {out[key].shape}")You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
input_ids shape: torch.Size([5, 77])
attention_mask shape: torch.Size([5, 77])
labels shape: torch.Size([5, 77])
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="combined_instruct_llama",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
evaluation_strategy="steps",
eval_steps=5_000,
logging_steps=5_000,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1000,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=1_000,
fp16=True,
push_to_hub=False,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets,
)trainer.train()학습하기!
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0612", padding_side='left')
prompt_format1 = """Determine if the given article is fake. article: %s answer:"""
prompt_format2 = """Is this article fake? article: %s answer:"""
prompt_format3 = """Return True if the given article is fake. article: %s answer:"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_valid_prompt_fake(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['title'])})
valid_dataset = dataset_fake['test'].select(range(100)).map(gen_valid_prompt_fake)
context_length=128
valid_dataset = valid_dataset.map(
tokenize, batched=True, remove_columns=['text', 'input', 'Unnamed: 0', 'title']
)
valid_datasetDataset({
features: ['label', 'input_ids'],
num_rows: 100
})
from torch.utils.data import DataLoader
batch_size=4
val_ds = valid_dataset
val_ds.set_format(type='torch')
val_dl = DataLoader(val_ds, batch_size=batch_size)데이터 로더 정의하기
import torch
from tqdm import tqdm
import re
def acc(pred,label):
return torch.sum(torch.tensor(pred) == label.squeeze()).item()
model.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model.generate(input_id, max_length=128)
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False)
decoded_pred = [re.findall("answer: (True|False)", x)[0] if re.findall("answer: (True|False)", x) else 'none' for x in decoded_pred]
decoded_pred = [label2int_fake[x] if x in label2int_fake else -1 for x in decoded_pred]
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/((step+1)*batch_size))높은 성능을 보여준다.
혼자 학습한 것과 동일한 성능을 보여준다.
tokenizer = AutoTokenizer.from_pretrained("daily_tokenizer_0612", padding_side='left')
prompt_format1 = """Given the article, what is the topic of the article? article: %s answer:"""
prompt_format2 = """Determine the topic of the news article. article: %s answer:"""
prompt_format3 = """What is this article about? business/entertainment/food/healthy/parenting article: %s answer:"""
prompts = [prompt_format1, prompt_format2, prompt_format3]
def gen_valid_prompt_cate(element):
prompt_format = prompts[random.randint(0, len(prompts)-1)]
return DatasetDict({'input': prompt_format%(element['headline'])})
valid_dataset = dataset_cate['test'].map(gen_valid_prompt_cate)
context_length=128
valid_dataset = valid_dataset.map(
tokenize, batched=True, remove_columns=['link', 'headline', 'category', 'short_description', 'authors', 'date', 'input']
)
valid_datasetfrom torch.utils.data import DataLoader
batch_size=4
val_ds = valid_dataset.select(range(100))
val_ds.set_format(type='torch')
val_dl = DataLoader(val_ds, batch_size=batch_size)from tqdm import tqdm
import re
import torch
model.eval()
val_losses = []
val_acc = 0
for step, batch in enumerate(tqdm(val_dl)):
device='cuda:0'
label = batch['label']
input_id= batch['input_ids'].to(device)
pred = model.generate(input_id, max_length=150)
decoded_pred = tokenizer.batch_decode(pred, skip_special_tokens=True, clean_up_tokenization_spaces=False)
decoded_pred = [re.findall("answer: ([a-z]+)", x)[0] if re.findall("answer: ([a-z]+)", x) else 'none' for x in decoded_pred]
decoded_pred = [label2int_cate[x] if x in label2int_cate else -1 for x in decoded_pred]
val_acc += acc(decoded_pred, label)
print("val acc: ", val_acc/len(val_dl.dataset))여기도 유사한 성능이 나온다.
이렇게 학습한 것을 보면 어떻게 instruction GPT가 학습한 것인지 볼 수 있었다.
model.save_pretrained('llama_combined_0721')저장하기
GPT나 LLaMa와 같은 대화형 LM은 pre-training할 때 epoch를 2이상 쓰지 않는것 같은데 이유가 뭐야? 대부분 1번만 진행하고 다시 쓰지 않네
대화형 언어 모델인 GPT나 LLaMa와 같은 모델들이 pre-training(사전 훈련)을 할 때 한 번의 epoch만 사용하는 데는 몇 가지 이유가 있습니다:
데이터의 양과 시간 문제: 대규모 언어 모델은 수백 기가바이트에서 테라바이트에 달하는 텍스트 데이터를 사용하여 훈련됩니다. 이렇게 많은 데이터를 여러 번 반복해서 학습시키는 것은 시간적으로나 자원적으로 매우 부담이 큽니다. 한 번의 epoch로도 충분한 학습이 가능하다면 추가적인 epoch는 비효율적일 수 있습니다.
과적합(Overfitting) 방지: 한 번의 epoch만 사용하는 이유 중 하나는 과적합을 방지하기 위함입니다. 데이터를 여러 번 반복해서 학습시키면 모델이 학습 데이터에 과적합될 가능성이 높아집니다. 즉, 모델이 훈련 데이터에 너무 특화되어 새로운 데이터에 대한 일반화 성능이 떨어질 수 있습니다. 한 번의 epoch로도 충분한 성능을 낼 수 있는 경우가 많기 때문에 추가적인 epoch는 오히려 모델 성능을 저하시킬 수 있습니다.
학습 효율성: 대규모 언어 모델의 경우, 모델의 크기와 데이터의 양이 매우 크기 때문에 한 번의 epoch로도 충분한 패턴을 학습할 수 있습니다. 초기 학습 과정에서 중요한 패턴들이 학습되며, 추가적인 epoch는 학습 성능의 큰 향상을 가져오지 않는 경우가 많습니다. 따라서, 자원을 효율적으로 사용하기 위해 한 번의 epoch만 사용하는 것이 일반적입니다.
데이터 순환의 필요성 감소: 일반적인 기계 학습에서는 데이터가 충분히 크지 않거나 다양하지 않을 때 여러 번의 epoch를 통해 데이터를 반복적으로 노출시킴으로써 모델이 더 나은 성능을 내도록 합니다. 그러나 대규모 언어 모델에서는 데이터 자체가 매우 크고 다양하기 때문에, 단 한 번의 순환으로도 다양한 패턴과 정보를 학습할 수 있습니다.
실험 결과: 실제로 많은 연구와 실험 결과에서 대규모 언어 모델들이 한 번의 epoch만으로도 충분한 성능을 발휘한다는 것이 확인되었습니다. 추가적인 epoch는 학습 시간과 자원만 소모하고 성능 향상에 큰 기여를 하지 않는다는 것이 입증된 경우가 많습니다.
이러한 이유들로 인해, 대화형 언어 모델의 사전 훈련 과정에서 한 번의 epoch만 사용하는 것이 일반적입니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| LLaMa3 LoRA를 통해 parameter efficient fine-tuning 진행하기 1(Matlab 도메인) - python (0) | 2024.07.22 |
|---|---|
| 자연어 처리 Python 실습 - Parameter Efficient Fine tuning (3) | 2024.07.22 |
| 자연어 처리 : LLaMa Pretrain하기 - python 실습 (1) | 2024.07.21 |
| 자연어 처리 LLaMa 모델 분석하기 (0) | 2024.07.21 |
| 자연어 처리 : 분산학습 - Distributed Training, Python 실습 (1) | 2024.07.21 |