https://huggingface.co/google/gemma-3-12b-it
google/gemma-3-12b-it · Hugging Face
This repository is publicly accessible, but you have to accept the conditions to access its files and content. To access Gemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged in
huggingface.co
일단 저는 12b모델을 사용했습니다.
from transformers import pipeline
import torch
pipe = pipeline(
"image-text-to-text",
model="google/gemma-3-12b-it",
device="cuda",
torch_dtype=torch.bfloat16
)이렇게 그냥 불러오면!

이런 오류가 발생합니다.
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3이걸 꼭 해야지 Transformer 오류가 발생하지 않습니다 ㅎㅎ...
처음 설치에는 생각보다 오래 걸립니다...
이렇게 불러오기도 완료 했다면!
일단 예시코드 한번 사용해보겠습니다.
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0][0]["generated_text"][-1]["content"])
# Okay, let's take a look!
# Based on the image, the animal on the candy is a **turtle**.
# You can see the shell shape and the head and legs.그런데 이걸 하면 또 오류가 발생합니다.
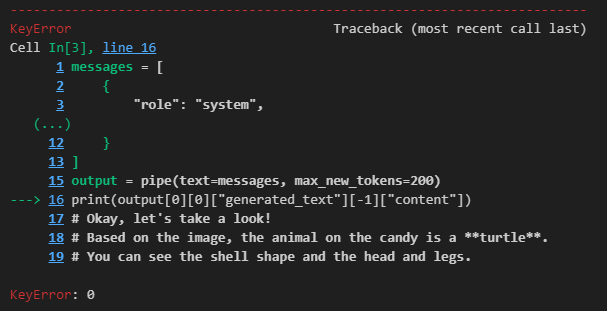
print(output[0]["generated_text"][-1]["content"])이렇게 0 하나 빼주면 됩니다...

이렇게 출력이 잘 나오는 것을 볼 수 있습니다.
이제 텍스트만 한번 넣어보자!
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "text", "text": "Hello"}
]
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
# Okay, let's take a look!
# Based on the image, the animal on the candy is a **turtle**.
# You can see the shell shape and the head and legs.이렇게 하면

이런 오류가 발생합니다.

이 Image-text-to-text라서 문제가 발생하는 것 같습니다!
그럼 이걸 text-generation으로 바꿔주면!

뭐 어쩌라는 듯한 오류 메세지가 발생합니다.........
구글링 해야죠...
https://github.com/huggingface/transformers/issues/36683
AttributeError: 'Gemma3Config' object has no attribute 'vocab_size' · Issue #36683 · huggingface/transformers
System Info v4.50.0.dev0 Who can help? @ArthurZucker @LysandreJik @xenova Information The official example scripts My own modified scripts Tasks An officially supported task in the examples folder ...
github.com
여기 동일한 문제가 있습니다.
pip install --upgrade git+https://github.com/huggingface/transformers.git일단 여기서 임시로 해결했다고 하네요!

아... CasualLM으로 부르는 것만 해결했나 봅니다...
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-3-12b-it", device_map="auto")이것도 한번 해봤는데 동일하게...

그래서 이전에 사용하던 방법을 씁니다...
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torch
model_id = "google/gemma-3-12b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)이렇게 보델을 불러옵니다.
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"},
{"type": "text", "text": "Describe this image in detail."}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)이번에도 일단 예시 먼저 해봅니다.

잘 되는 것을 볼 수 있습니다.
이제 텍스트만 넣어봅니다.
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "text", "text": "안녕하세요. 적당히 바람이 시원해 기분이 너무 좋아요 유후"}
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
여기선 잘 되는 것을 볼 수 있습니다.
이제 제가 진행중인 걸로 실행시켜보면!

잘 됩니다.
당분간은 이 방법으로 하는데, 다른 오류들이 너무 많을 것 같아서 조심해야겠습니다...
다른 모델을 주로 쓰는 걸로..
'인공지능 > 자연어 처리' 카테고리의 다른 글
| vllm 통해 reasoning path 데이터 만들기 (1) | 2025.03.24 |
|---|---|
| Vllm을 활용한 빠른 Bench Mark Test 진행하기 (0) | 2025.03.21 |
| Few-Shot, CoT(Chain-of-Thought)와 ReAct 하나 하나 뜯어보기 (0) | 2025.02.05 |
| Late Chunking 사용해보기 및 Chunking 코드 익숙해지기 (1) | 2025.01.22 |
| Semantic, Dynamic Chunking 자료 정리 (0) | 2025.01.21 |