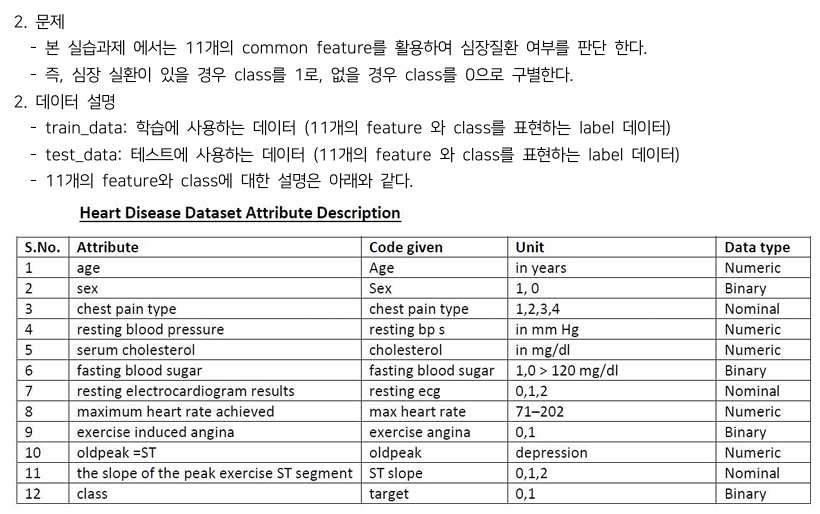
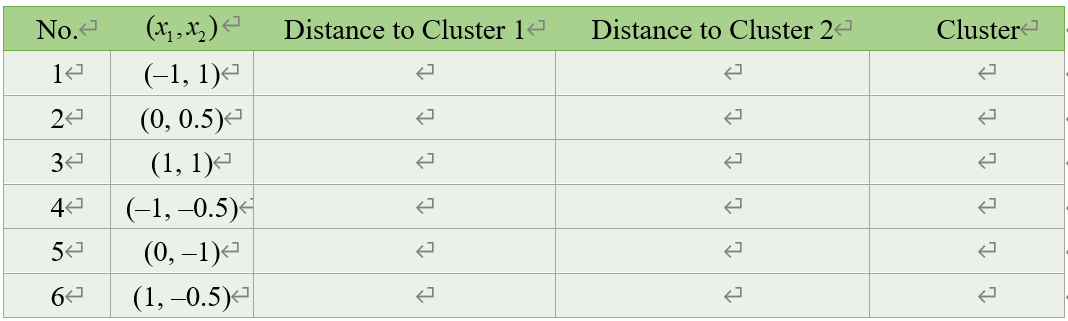
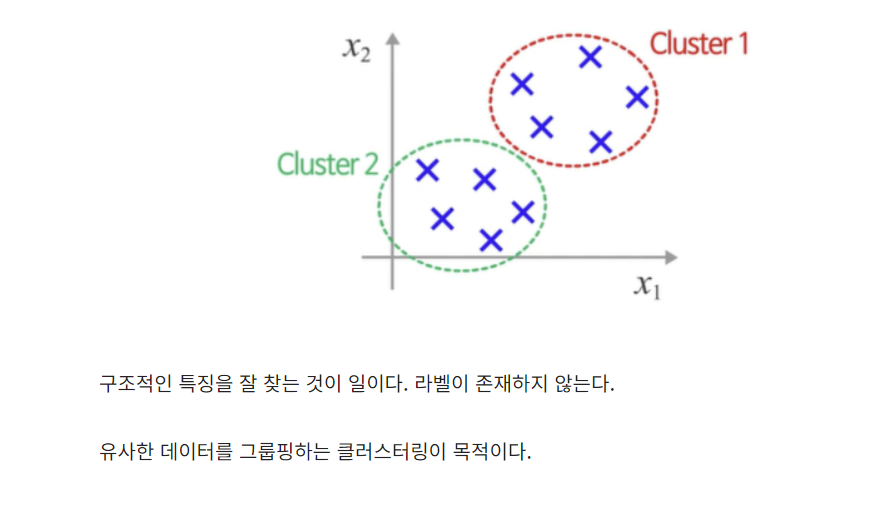
from google.colab import drive, filesimport pandas as pdfrom keras.datasets.mnist import load_datafrom keras.models import Sequential, Modelfrom keras.layers import Dense, Input ,Flatten, Dropout, Conv2D, MaxPooling2Dfrom keras.utils import plot_model, to_categoricalfrom keras.regularizers import l2from sklearn.model_selection import train_test_splitimport numpy as npimport matplotlib.pyplot as ..