Regularization
이전 글에서 나왔던 오버 피팅을 방지하기 위해 나왔던 방법이다.
2024.08.25 - [인공지능/공부] - 딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network
딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network
Linear Regression 선형 회귀로 지도학습(Supervised Learning)을 통해 정답을 학습해 입력에 대한 예측을 출력ex) 집값 예측, 키에 따른 몸무게 예측, 주식 등등..Cost function예측 값h(x)과 정답 값(y)에 대한
yoonschallenge.tistory.com
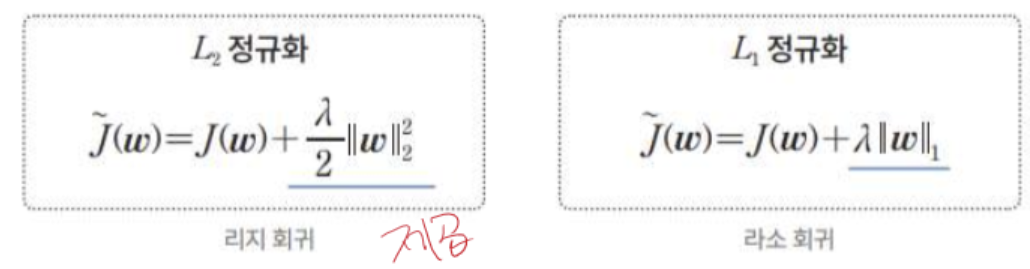
이렇게 정규화 항은 loss function뒤에 붙이며 파라미터가 커지지 못하도록 막는다.

람다에 따라 파라미터의 변동성이 커지면서 over fitting과 under fitting이 나타나는 것을 볼 수 있다.
가중치의 사전 분포가 가우시안 분포라면 L2 정규화를 사용하고, 라플라스 분포라면 L1 정규화를 사용한다.
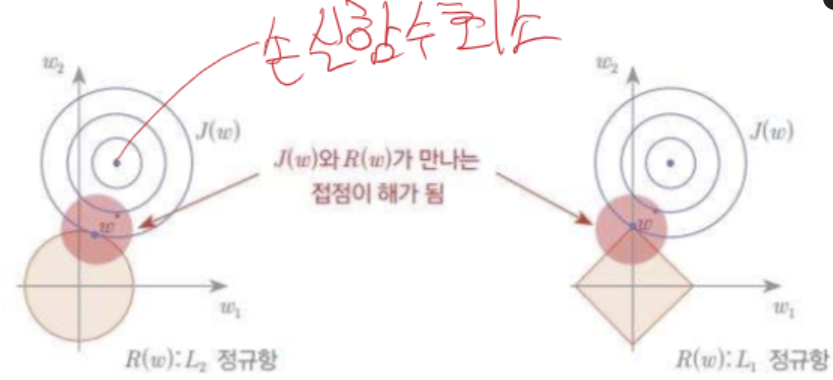
위와 같은 방식으로 학습이 빨리 끝나게 된다.
Drop out
Drop out도 오버피팅을 방지하기 위한 방법으로, 레이어에서 모든 노드를 사용하는 것이 아닌 일정 부분을 확률상으로 사용하지 않아 학습에서 제외시켜 과적합을 피한다.
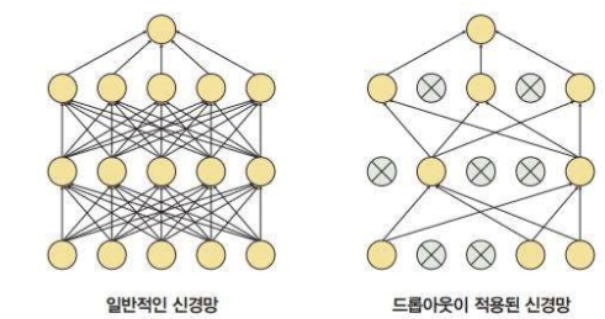
이렇게 Drop out은 간단하다.
https://youtu.be/QpW4_cjc4Jo?si=P-o0jWuTnqU94Lq-
드롭 아웃은 노드를 일부분 탈락 시킨다. - 몇 개의 노드가 없더라도 잘 돌아가도록 훈련된다. == 각 노드가 의미있는 특징을 잘 뽑는다.
테스트는 다른 모델을 앙상블 하는 느낌이 난다.
256개의 28*28 weight map이 drop out을 적용해야 비슷한 특징을 뽑지 않고 특색(의미) 있는 노드를 뽑게 된다.
Hyper parameter
이전 페이지에서 나왔던 반복 회수, 배치 사이즈 등 학습에 영향을 주는 숫자들이 하이퍼 파라미터이다.
#(num) of iterator
# of layer
# of node
# of learning rate
type of activation function - 이건 교수님들 마다 생각이 다르신 것 같습니다.
type of optimizer
learnable parameter는 network 내부에 있는 theta입니다.
optimizer
optimizer는 경사하강법을 진행하면서 극소점을 찾아가는데 일정 부분에서 최소가 아닌 전역적인 최소를 찾게 도와주거나, 빠른 수렴을 도와줍니다.


각각의 장 단점을 합쳐서 ADAM이 되었다.
각각에 대한 설명은
2023.12.16 - [인공지능/공부] - 인공지능 backpropagation, optimization- 개념
인공지능 backpropagation, optimization- 개념
backpropagation backpropagation은 대부분의 인공지능의 파라미터 업데이트 방식이다. 우린 경사하강법을 통해 loss를 최소화 시키는 방향으로 학습한다. 기본적인 gradient 계산 방법이다. 이제 activation fun
yoonschallenge.tistory.com
여기에 작성되어 있습니다.
'인공지능 > 공부' 카테고리의 다른 글
| 재미있는 인공지능 속 세상 여행 3주차 - Chat GPT의 등장과 비즈니스 환경 변화 (8) | 2024.09.18 |
|---|---|
| 재미있는 인공지능 속 세상 여행 1, 2주차 - 생성형 AI (10) | 2024.09.10 |
| 딥러닝 복습 1 - Linear Reagression, Logistic regression,Neural Network (0) | 2024.08.25 |
| 인공지능과 빅데이터 문제 만들기 (0) | 2024.06.21 |
| 인공지능과 빅데이터 11 ~ 15주차 정리 (0) | 2024.06.20 |