Linear Regression
선형 회귀로 지도학습(Supervised Learning)을 통해 정답을 학습해 입력에 대한 예측을 출력
ex) 집값 예측, 키에 따른 몸무게 예측, 주식 등등..
Cost function
예측 값h(x)과 정답 값(y)에 대한 오차를 Loss function으로 보여주며 값을 감소하는 방향으로 나아간다.
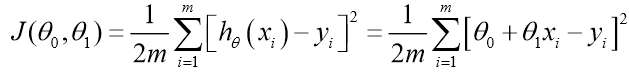
학습에 관련된 단어

Batch - 전체 데이터 세트
Epoch - 전체 데이터 세트를 몇 번 반복하는가
Mini batch - Batch를 batch size로 나눈 작은 데이터 뭉치
Iteration - 총 반복한 횟수로 Epoch*mini batch개수 이다.
Gradient descent
경사 하강법으로 딥러닝이 학습하는 방식이다.

Cost function을 미분하여 기울기를 구하고, 딥러닝의 파라미터 즉 theta를 오차가 감소하는 방향으로 업데이트한다.

여기서 alpha 는 학습률(Learning rate)로 너무 크면 오버 슈팅이, 너무 작으면 학습속도가 매우 느려진다.

2023.11.13 - [인공지능/공부] - Linear regression 1
Linear regression 1
import numpy as np import matplotlib.pyplot as plt # ==================== Part 1: Basic Function ==================== print('Running warmUpExercise ... ') print('5x5 Identity Matrix: ') def warmUpExercise(): return np.eye(5)# YOUR CODE HERE warmUpExercise(
yoonschallenge.tistory.com
Linear regression을 직접 구현한 코드는 여기 있습니다.
이 코드를 통해 cost function (J)가 어떻게 되는지, 학습이 어떻게 이루어 지는지 확인할 수 있습니다.
Logistic regression
분류(Classifiction) 문제를 풀며 학습을 통해 입력에 대한 예측을 출력한다.
이진 분류에서 cost function으로는 binary cross entropy를 사용한다.

Sigmoid

sigmoid를 사용하여 분류를 좀더 확실하게 0,1로 나눌 수 있게 된다.
Sigmoid식은 위에 써져있는 식으로 미분하는 방식은 아래와 같다.

Decision Boundary
Logistic regression은 Decision Boundary(결정 경계)를 그리는 것으로 이해해도 된다.
이 Boundary는 Linear Regression과 동일한 방식으로 그릴 수 있다.
2023.11.13 - [인공지능/공부] - logistic Regression
logistic Regression
import numpy as np import matplotlib.pyplot as plt from google.colab import drive drive.mount('/content/drive') # ==================== Load Data ==================== # The first two columns contains the exam scores and the third column # contains the label
yoonschallenge.tistory.com
여기에서 확인할 수 있다.

여기 보라색 선이 decision boundary이다.
이 것은 layer를 여러 개 사용하여 decision boundary가 휘는 것을 볼 수 있다.
Neural Network
Layer들을 직렬로 연결하고, Nonlinear actication function을 도입하여 nonlinear decision boundary(혹은 nonlinear regression)를 표현할 수 있다.
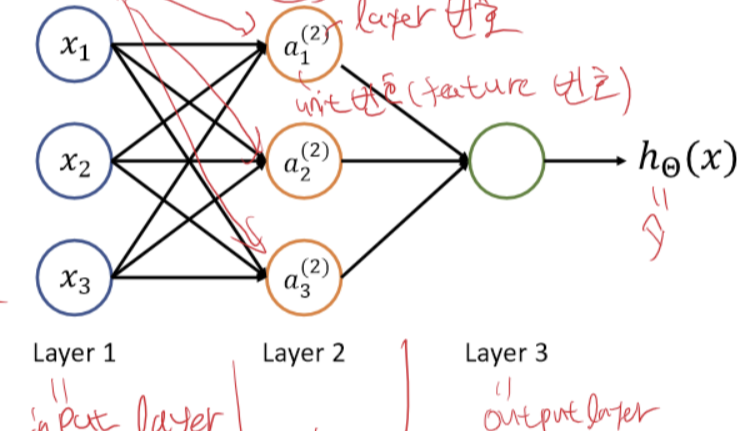
계산하는 방식은 Logistic regression과 비슷하나 Cost function은 마지막에서 구한다는 것, Decision boundary가 비선형적 이라는 차이가 있다.
forward propagation

Layer가 입력을 받으면 진행하는 과정이다.
마지막에 출력, 즉 예측을 얻을 수 있다.
Back Propagation
Forward propagation을 통해 얻은 예측의 정답 값과 예측 값 차이로 내부 파라미터를 업데이트 하는 과정이다.
이 과정은 뒤에서 부터 체인 룰을 통해 미분해서 진행한다.

여기서 activation function은 Sigmoid이고, 여기서 +1은 연산을 간편하게 하기 위해 하나씩 추가된 노드라고 보면 된다.
Cost function은 binary cross entropy이다.



이렇게 back propagation은 연쇄적으로 진행된다.

over fitting
과적합으로 테스트문제는 잘 풀지만 실제 예측, test set에서는 높은 성능을 보여주지 못하는 것으로 사전에 방지해한다.


방지하는 방식으로 정규화가 있는데 이 것은 다음 글에 또 작성하겠다.
zero initialization?!
모두 같은 값이나 0으로 파라미터를 초기화 하게 되면 gradient가 모두 같아 layer마다 학습 파라미터가 같은 값을 가지게 되어 학습이 진행되지 않는다.
Improve a learning algorithm
data set 늘리기, feature 늘리거나 줄이기, layer 수의 변화, 정규화 값의 변화
cross validation data set
test set만 테스트 하기엔 우연의 일치도 있고, 오버 피팅을 즉각적으로 확인하기 어려우니 교차 검증 데이터 셋을 만든다.
보통 비율은 train : validation : test를 6 : 2 : 2로 나눈다.

validation과 train곡선의 차이가 거의 없다 == 학습이 잘 되고 있다.
validation과 train의 차이다 크다 == 오버 피팅이 났다.
둘 다 너무 크다 == 언더 피팅이 났다.
'인공지능 > 공부' 카테고리의 다른 글
| 재미있는 인공지능 속 세상 여행 1, 2주차 - 생성형 AI (10) | 2024.09.10 |
|---|---|
| 딥러닝 복습 2 - Regularization, Drop out, Hyper Parameter, optimization (0) | 2024.08.25 |
| 인공지능과 빅데이터 문제 만들기 (0) | 2024.06.21 |
| 인공지능과 빅데이터 11 ~ 15주차 정리 (0) | 2024.06.20 |
| LSTM, GRU 연산 정리하기 (0) | 2024.06.18 |