728x90
728x90




지도 학습 - 정답
비지도 학습 - 목적 함수
강화 학습 - 보상의 총합 최대화 -> 보상이 학습을 가능하게 해준다.
누적합 - 시간의 흐름에 따라 보상이 쌓인다.
끝나면 그게 하나의 에피소드이다.


에이전트 - 게이머, 사람
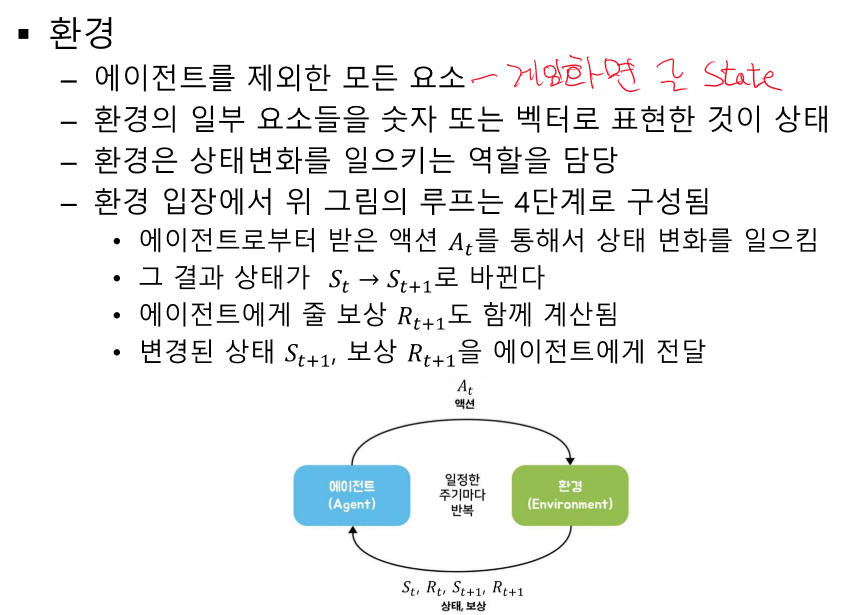
환경 전체를 이해하고 모델링 할 수 있다. -> 굳이 강화학습 사용하지 않아도 된다.
환경이 너무 복잡해서 일부만 쓴다. -> state, 간소화해서 모델링 한다.

728x90
'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 정리 - 4강 MDP를 알 때의 플래닝 (1) | 2024.04.20 |
|---|---|
| 강화 학습 정리 - 3강 벨만 방정식 (1) | 2024.04.20 |
| 강화학습 정리 - 2강 마르코프 프로세스 (1) | 2024.04.20 |
| 생성형 인공지능 특강 (0) | 2024.04.17 |
| Back propagation 손으로 하나하나 적어보기 (0) | 2024.04.17 |