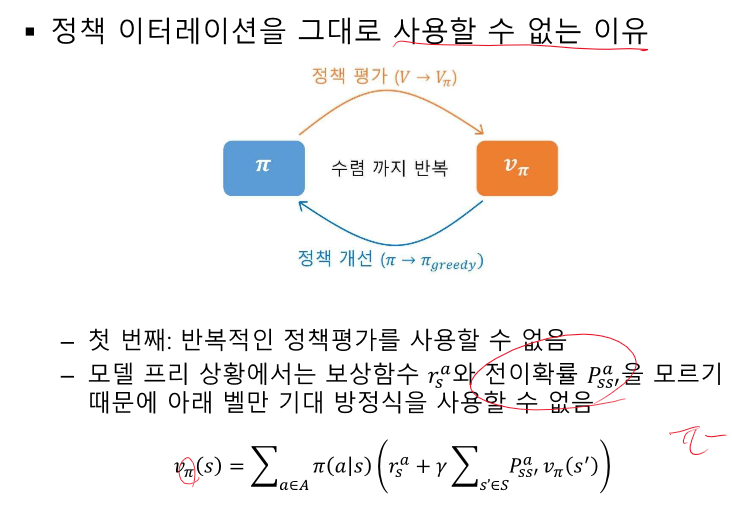
정책 이터레이션 - 정책 평가와 개선의 반복
2. P를 모른다 -> 내가 어떤 s로 갈지 모른다.
해결법!
1. 평가 자리에 MC 방법론 이용하여 각 상태 v 구하기!
몬테카를로 방법론(Monte Carlo Methods)은 무작위 샘플링을 기반으로 하는 계산 알고리즘의 한 종류입니다. 다양한 분야에서 광범위하게 활용되며, 특히 복잡한 문제의 수치적 해를 찾는데 유용하게 사용됩니다. 기본 아이디어는 무작위성(randomness)을 이용하여 문제의 해를 확률적으로 추정하는 것입니다.
몬테카를로 방법은 다양한 형태로 나타날 수 있지만, 일반적인 사용 예로는 다음과 같은 것들이 있습니다:
- 적분의 근사: 함수의 적분을 근사하기 위해 무작위로 점들을 선택하고 함수 값의 평균을 이용합니다.
- 확률적 시뮬레이션: 금융, 물리학, 생물학 등에서 다양한 시나리오를 시뮬레이션하고 결과를 분석합니다.
- 최적화 문제: 가능한 해의 공간을 무작위로 탐색하여 최적 또는 근사적인 해를 찾습니다.
특히, 강화학습 분야에서 몬테카를로 방법은 정책이나 가치 함수를 평가하는 데 사용됩니다. 여기서 말씀하신 "v를 다 0으로 두고 반복해서 v를 구하는" 방법은 몬테카를로 예측(Monte Carlo Prediction)으로, 주어진 정책(policy) 하에 각 상태의 가치를 추정하는 방법 중 하나입니다.
몬테카를로 예측(Monte Carlo Prediction)
강화학습에서 몬테카를로 예측은 다음과 같은 단계로 진행됩니다:
- 초기화: 모든 상태의 가치 추정 ( V(s) )를 0 (또는 임의의 값)으로 초기화합니다.
- 에피소드 생성: 현재 정책을 따라 여러 에피소드를 실행합니다. 에피소드는 상태, 행동, 보상의 시퀀스입니다.
- 가치 함수 업데이트: 각 에피소드가 끝날 때마다, 에피소드를 통틀어 발생한 각 상태에 대해 반환값(return, 즉 미래 보상의 합)을 계산하고 이를 이용해 해당 상태의 가치 추정치를 업데이트합니다.
이 방법은 각 상태의 가치를 단순한 평균으로 계산합니다. 이렇게 하면 많은 에피소드를 통해 더 정확한 가치 추정이 가능해집니다. 몬테카를로 방법은 각 상태를 많이 방문해야 하는 높은 "샘플 복잡성"이라는 단점이 있지만, 모든 경로의 가능한 결과를 고려한다는 점에서 동적 계획법(dynamic programming)과 같은 다른 방법보다 장점을 가지고 있습니다.
2. v 대신 q 사용하기
상태-액션 가치 함수를 MC를 활용하여 계산. q를 이용하여 새로운 그리디 정책 생성
BUT 위 방식은 새로운 길을 탐색하지 못해서 최적 해를 찾지 못할 수 있다.
3. 그리디 대신에 입실론(랜덤) 그리디 사용
입실론 만큼은 랜덤하게, 나머지는 최대 q를 따라가게 a 하기
decaying 입실론 그리디 : 처음엔 입실론을 크게하고 점차 줄이기

v(s) = E(q(s,a))
MC 대신 TD 사용하기
SARSA - TD를 이용해 Q를 계산하는 접근 법

target policy(타깃 정책) : 강화하고자 하는 목표가 되는 정책 - 최적 정책
behaviro policy(행동 정책) : 실제로 환경과 상호작용하며 경험을 쌓고 있는 정책
on-policy : 타깃 정책과 행동 정책이 같은 경우 (직접 경험, 입실론을 빼면 항상 여기로 간다.)
off-Policy : 타깃 정책과 행동 정책이 다른 경우(간접 경험, 랜덤 적으로 경험 하는 것을 포함한다. 타깃 정책은 행동 정책의 좋은 점은 수용하고 좋지 않은 점은 수정한다. - 다른 에이 전트의 경험 가지고 와서 정책 만들기)
강화학습에서 On-policy와 Off-policy 방법은 학습 과정에서 사용하는 데이터가 어떻게 수집되고 사용되는지에 따라 구분됩니다. 두 용어는 정책(policy)에 대해 어떻게 학습이 진행되는지를 나타냅니다.
On-policy
On-policy 방법에서는 학습 알고리즘이 현재 평가하고 개선하려는 같은 정책을 사용하여 행동을 선택하고 데이터(경험)를 수집합니다. 즉, 학습 중인 정책으로부터 직접 데이터를 수집하고 그 데이터를 이용해 해당 정책을 개선합니다.
예시:
- SARSA (State-Action-Reward-State-Action): 이 알고리즘은 현재 정책에서 파생된 데이터를 사용하여 학습하고, 현재 정책을 기반으로 다음 행동을 선택합니다.
Off-policy
Off-policy 방법에서는 학습 알고리즘이 행동을 선택하고 데이터를 수집하기 위해 다른 정책(behavior policy)을 사용하고, 이렇게 수집된 데이터를 이용해 다른 목표 정책(target policy)을 평가하고 개선합니다. 이 방식은 더 유연하게 다양한 종류의 경험을 학습에 활용할 수 있게 해줍니다.
예시:
- Q-learning: 이 알고리즘은 최적의 행동을 선택하는 정책을 학습하지만, 실제로는 다른 정책(예를 들어, 탐험적인 행동을 하는 ε-greedy 정책)을 사용하여 데이터를 수집할 수 있습니다. Q-learning은 최적 정책을 찾기 위해 각 상태에서 최대의 기대 보상을 주는 행동을 선택하는 정책을 학습합니다.
요약
따라서, On-policy는 학습 중인 정책을 직접 사용하여 행동을 결정하고 경험을 수집합니다. 반면, Off-policy는 다른 정책을 사용하여 데이터를 수집하고, 이를 바탕으로 다른 목표 정책을 학습합니다. 이는 Off-policy 방법이 더 다양한 데이터와 상황에 대해 학습할 수 있게 해주며, 특히 최적의 정책을 찾는 데 효과적일 수 있습니다.
off-policy 장점
1. 과거의 경험 재사용 가능 (on policy(정책에 의존하여 경험)에서 정책을 바꾸기 위해선 이전 정책에 따른 평가 후 수정이 되지만 off Policy에서는 다른 여러 경험을 가지고 와서 수정할 수 있다.)
2. 사람의 데이터에서 학습 가능하다. (이전의 기록을 (s, a, r, s')로 만들어서 off policy 학습이 가능하다.)
3. 일대다, 다대일 학습이 가능하다. (동시에 여러 개의 정책 데이터를 모아 1개의 정책을 만들거나 다양한 관점에서 학습이 가능하다.)

벨만 기대 방정식(Bellman Expectation Equation)과 벨만 최적 방정식(Bellman Optimality Equation)은 강화학습에서 매우 중요한 개념으로, 정책의 평가와 최적화에 관련되어 있습니다. 이 두 방정식은 강화학습 문제를 해결하는 데 필수적이며, 각각의 방정식은 상태 가치 함수나 행동 가치 함수를 업데이트하는 규칙을 정의합니다.
벨만 기대 방정식 (Bellman Expectation Equation)
벨만 기대 방정식은 특정 정책 ( \pi ) 아래에서 각 상태의 가치를 평가하는 방정식입니다. 이 방정식은 주어진 정책 ( \pi ) 하에서 각 상태의 기대 반환(기대 보상의 합계)을 계산합니다. 즉, 이 방정식은 현재 정책을 평가하기 위한 것이며, 그 정책이 최적이라고 가정하지 않습니다.

벨만 최적 방정식 (Bellman Optimality Equation)
벨만 최적 방정식은 최적의 정책 하에서의 상태 가치나 행동 가치를 계산합니다. 이 방정식은 각 상태 또는 상태와 행동 쌍에서 최대 가치를 산출하도록 설계되어 있으며, 최적의 정책을 찾는 데 사용됩니다.

요약
벨만 기대 방정식은 주어진 정책의 효과를 평가하기 위한 것이며, 특정 정책에 대한 가치 함수의 기대치를 계산합니다. 반면 벨만 최적 방정식은 최적의 정책을 찾기 위해 각 상태 또는 상태-행동 쌍에서 가능한 최고의 결과를 추구합니다. 기대 방정식은 주어진 정책을 평가하는 반면, 최적 방정식은 최고의 가능한 행동을 찾아내는 데 초점을 맞춥니다.
즉 벨만 기대 방정식 == on policy - 정책 따라 움직이며 계산
벨만 최적 방정식 == off policy - 최고 따라 움직이며 계산


식의 모양이 조금 다르다
살사 - 파이 정책을 따르면서 맥스(혹은 입실론 만큼의 랜덤)가 되는 q를 가져와 찾는다.
Q러닝 - q 업데이트 하는 과정에서 파이를 무시하고 전체중에 맥스를 찾자!

safe path - 마이너스가 크게 쌓인다 - Sarsa
optimal path - 최단 길을 찾으나 빠질 확률이 크다 - Q
살사는 안정적인 길을 선호한다.
Q는 맥스를 가기 때문의 최적 길을 선호한다.



'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 중간 정리 4 - MC, 벨만 방정식, planning, 최적 정책 찾기, value 평가 (0) | 2024.04.22 |
|---|---|
| 딥러닝 개론 정리 7강 - 합성곱 신경망 2 CNN (0) | 2024.04.21 |
| 강화 학습 중간 정리 2 - MDP planning, MDP X value평가, X planning (0) | 2024.04.20 |
| 강화 학습 중간 정리 1 - MC, 마르코프 프로세스, MDP, MRP, 벨만 방정식 (1) | 2024.04.20 |
| 강화 학습 정리 - 6장 MDP를 모를 때 최고의 정책 찾기 (0) | 2024.04.20 |