강화 학습 : 지도자의 도움 없이 혼자서 수많은 시행착오를 거치면서 학습하는 방법
지도 학습 : 아버지가 아들에게 자전거 타는 방법을 가르쳐 주듯이 지도자의 도움을 받아서 학습하는 방법
비지도 학습 : 사람 얼굴 1만장을 학습 후에 새로운 사람 얼굴을 생성하는 인공지능, 주어진 데이터의 성질이 비슷한 것들 끼리 묶는 클러스터링
순차적 의사결정 문제 해결 방식 - 시간 순서대로 주어진 상황에서 목적을 이루기 위해 상황을 근거로 목적에 부합한 행동을 하고 상황이 변하면 그 것을 근거로 목적을 향해 행동
보상 : 목적에 부합하여 의사 결정을 잘 했을 때 그 부분을 의사결정 행위자가 인지할 수 있도록 알려주는 신호
강화학습 : 순차적 의사결정 과정에서 받은 보상의 누적합을 최대화 하는 것
보상의 특징
1. 어떻게 X, 얼마나 O- 보상은 얼마나 잘했는지에 대한 정보를 가지고 있다.
2. 스칼라 - 벡터 형식이 아니라 스칼라 값으로 오직 하나의 목적이다.
3. 희소하고 지연된 보상 - 보상이 희소할 수 있고 지연될 수 있다. 대부분 어떤 특정 행동이 목적에 부합하게 된 것인지 판단을 지나고 나서야 할 수 있다. -> 보상은 여러가지 행동을 한 이후에 주어질 수 있고, 결국 보상은 지연되어 제공될 수 있다는 의미
에이전트 - 학습자, 어떤 액션을 할지 정한다.
환경 - 에이전트를 제외한 모든 요소. 환경의 일부 요소를 숫자나 벡터로 표현하면 상태 (s)

강화 학습 장점
1. 병렬성 - 수 많은 컴퓨터를 병렬 연결하여 시뮬 진행 후 결과를 모아 학습 가능
2. 자가학습 - 목적에 부합하도록 스스로 행동을 개선하는 능력
마르코프 성질 - 미래(t+1)는 오로지 현재(t)에 의해 결정됨
마르코프 리워드 프로세스 (MRP)= 마르코프 프로세스 + 보상
보상함수 R - 어떤 상태 s에 도착했을 때 받게 되는 보상
감쇠인자 - 미래에 얻을 보상에 비해 당장 얻는 보상을 얼마나 더 중요하게 여길지 나타내는 파라미터 = 미래의 불확실성
리턴 : 에피소드가 끝날 때 까지 보상의 합 -> 즉 강화학습은 리턴의 최대화를 향해 학습
MRP에서 각 상태의 벨류(가치) 평가 - 현재 상태에서 미래에 받을 보상을 기준으로 평가
현재 상태 s에서 시작하여 미래에 받을 보상의 합인 리턴 G의 기대값을 측정
에피소드 샘플링 : 그냥 에피소드 겁나 돌려서 각각의 리턴 알기
상태 가치 함수 : 임의의 상태 s의 밸류를 알아내는 것
현재 상태에서의 리턴의 기댓값(평균값)
마르코프 결정 프로세스(MDP) : MRT + action
전이 확률 행렬 P - 상태 s일 때 에이전트가 액션 a를 취했을 때 다음 상태가 s'이 될 확률
보상 함수 R - 상태 s에서 액션 a를 선택하면 받는 보상함수
정책 함수 - 각 s에서 a을 정해준다. 에이전트 안에 존재. 더 큰 보상을 얻기 위해 업데이트
상태 가치 함수 - 정책에 따른 s 평가. s에서 정책이 a 선택. 정책에 따라 리턴(G)가 달라진다.
액션 가치 함수 - 각 s에서 a에 대한 평가. s에서 강재로 a 선택
Prediction - 정책이 주어졌을 때 각 s의 v 평가
Control - 최적 정책을 찾는 문제.
MDP에서 최적의 결정적 정책이 하나 이상 존재한다는 사실이 수학적으로 증명되어 있다.
최적 정책과 최적 가치 함수를 찾으면 MDP는 풀렸다!
벨만 방정식 - t와 t+1사이의 v의 관계를 다루며 v와 정책 함수 사이의 관계도 다룬다.


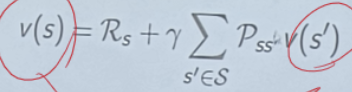




2단계 식을 계산하기 위해선 보상함수 (r)과 전이 확률 (P)를 반드시 알아야 한다.
모델 프리 - MDP를 모를 때 학습하는 접근법
모델 베이스 - MDP를 알고 있을 때 학습하는 접근법
최적 밸류 - 최대값이 되는 v나 q
모든 s에서 최적 밸류를 갖게하는 정책이 최소한 1개 이상 존재한다.
최적 정책 - 보상의 총합이 가장 크다. 모든 s에 대해 가장 크다.
최적 밸류- v*
최적 액션 밸류 - q*

벨만 최적 방정식 1단계 - q* 이용해 v* 계산하기
v*(s) = max q*(s,a)
why ? - 최적정책 = 하나의 최적 정책을 찾으면 된다.


'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 중간 정리 3 - MDP 모를 때 최적 정책 찾기 (0) | 2024.04.21 |
|---|---|
| 강화 학습 중간 정리 2 - MDP planning, MDP X value평가, X planning (0) | 2024.04.20 |
| 강화 학습 정리 - 6장 MDP를 모를 때 최고의 정책 찾기 (0) | 2024.04.20 |
| 강화 학습 정리 5강 - MDP를 모를 때 밸류 평가하기 (34) | 2024.04.20 |
| 강화 학습 정리 - 4강 MDP를 알 때의 플래닝 (1) | 2024.04.20 |