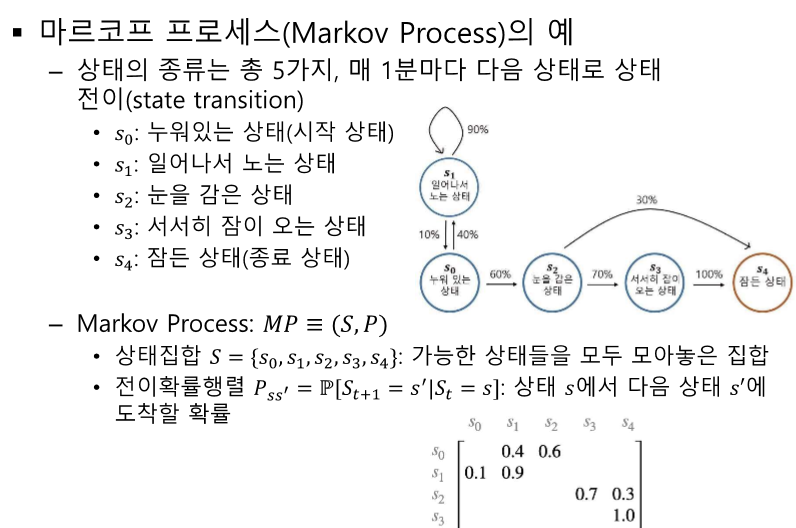
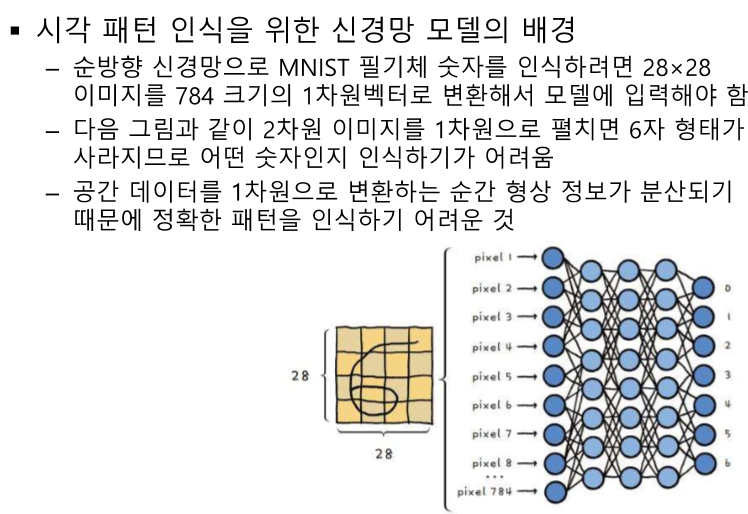
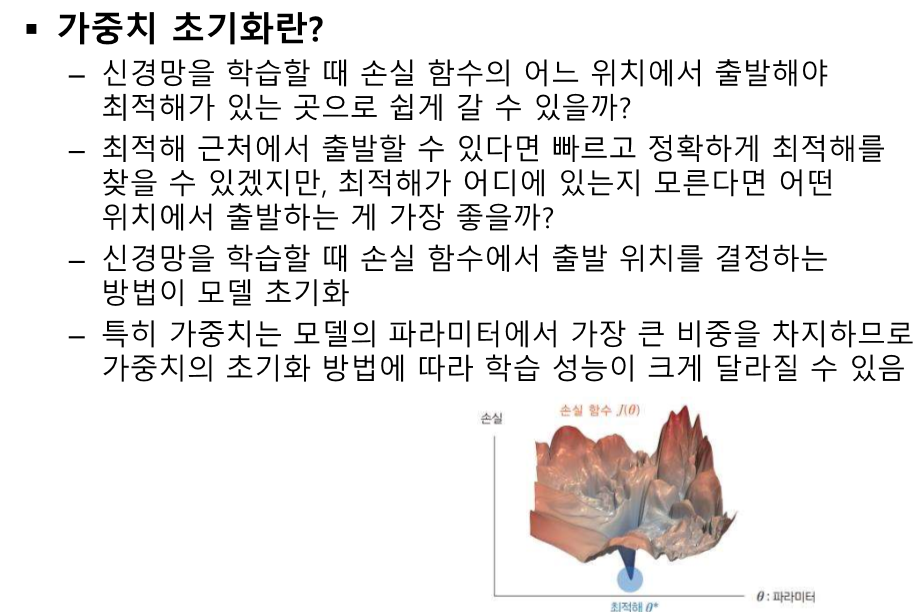
R- 보상, 리워드 G - 리턴 v - 상태 가치 방정식 q - 액션 가치 방정식 E - 평균 취하기 * - 최적 값 t - 상태 시간 단위 (k 보다 작은 시간인데 이전에서 나왔던 시간의 개념과 똑같다.) k - 에피소드 시간 단위 평균은 어디? - 어차피 마지막에 평균있어서 ㄱㅊ 항상 성립하는 것은 아니다 v(s) != v(s')이기 때문 v : s에 대한 리턴의 기댓값 액션이 추가되었다. v(특정 s의 가치)와 q(특정 s에서 a를 취했을 때 가치)의 관계 모델 프리 : 결과는 얻어지나 어떤 값으로 계산되는지 모르는 경우 v와 q의 선택은 목표에 따라 다르다. 어떤 위치에 도달해야 한다. S를 변화해야 한다. S를 예측할 수 없다. -> q를 사용한다. s'을 모를 때 q(s,a)를 대신해서 사용한..