자연어 처리 python 실습 - N gram language model
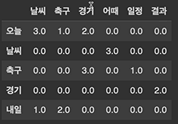
# N-gram Language Modeling 작은 샘플들을 활용해 N-gram language modeling을 구현해보고, 구현한 N-gram language model로 자동 완성 기능을 이해해보자 data corpus = ["오늘 날씨 어때", "오늘 날씨 어때", "오늘 날씨 어때", "오늘 축구 경기", "오늘 경기 결과", "오늘 경기 결과", "내일 날씨", "내일 축구 경기", "내일 축구 경기", "축구 일정", ] 문장의 빈도를 통한 확률 제대로 확인! # tokenization vocabs = set() for sample in corpus: for token in sample.split(): vocabs.add(token) vocabs = list(vocabs) vocabs 출력..