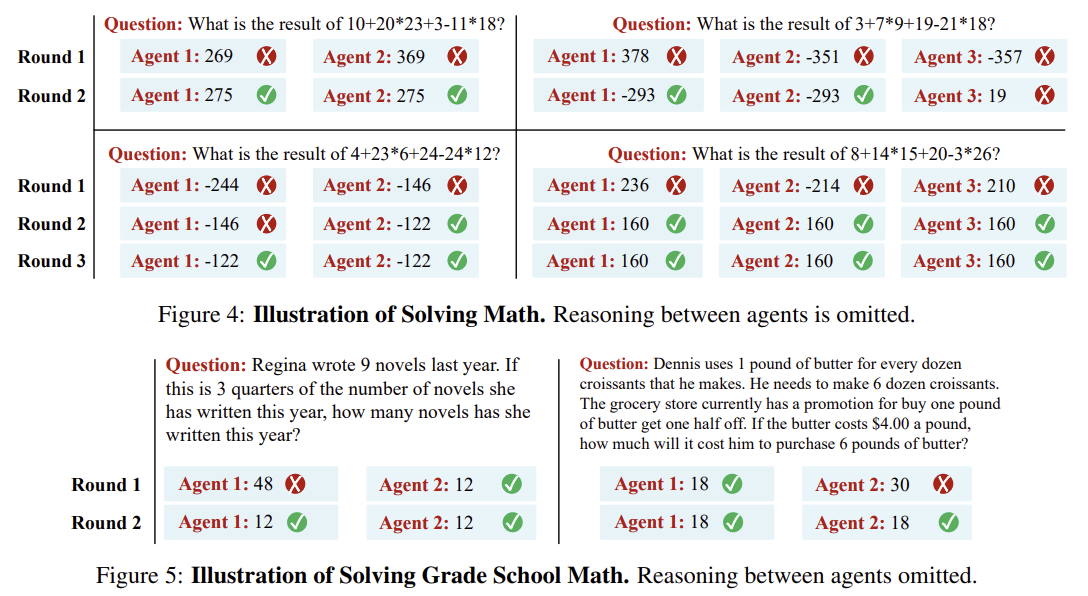
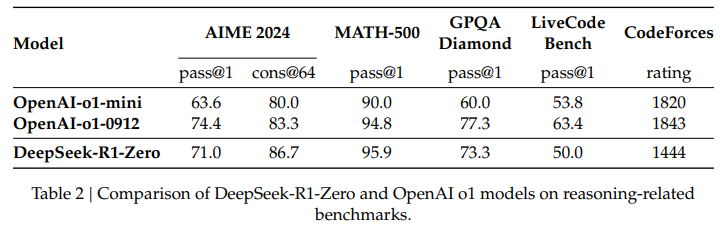
https://aclanthology.org/2023.findings-emnlp.153/ Chain of Thought with Explicit Evidence Reasoning for Few-shot Relation ExtractionXilai Ma, Jing Li, Min Zhang. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023.aclanthology.org 기존의 FSRE(Few-shot Relation Extraction)은 제한된 학습 샘플을 이용해 두 엔티티간 관계를 예측하는 문제를 다룬다.소수의 주석된 샘플 데이터만을 사용해 관계를 학습하고 예측해야하는 상황으로 메타 학습이나 신경 그래프, In-Con..