https://arxiv.org/abs/2305.14325
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of p
arxiv.org
Agent 논문입니다!
그 중에서도 Prompt를 통해 토론을 진행하고, 성능을 향상시킵니다.
CoT도 Hallucination에서 자유롭지 않았기에 Multi Agent Debate를 통해 LLM의 사실성과 추론 능력을 증진합니다.
처음엔 각 Agent 들이 동일한 입력에 대해 개별적인 답을 생성합니다.
그 후 각 Agent 들은 다른 Agent의 답을 읽고 논리적 비판을 진행한 뒤 자신의 답안을 다시 업데이트합니다.
이러한 과정을 여러 라운드에 걸쳐 반복하여 최적의 답을 도출합니다.
최종 답안은 도델들 간의 Consensus 즉 합의가 이루어지면 결정됩니다.
이 방법이 단일 모델 Reflection 방식보다 더 강력한 추론이 가능하고, 모델이 서로 상반된 답을 제시하는 경우 공통적으로 신뢰할 수 있는 답으로 수렴한다고 합니다.
사실적 오류를 포함한 답변이 토론을 거치면서 자동으로 제거도 됩니다.

여러 라운드에 거쳐서 Agent 들의 답이 통일되는 것을 볼 수 있다.


| 연구 목적 | - 언어 모델의 환각(hallucination) 및 논리적 추론 오류 문제 해결 - 다중 에이전트 간 협력을 통해 더 신뢰할 수 있는 답을 생성 - 다양한 문제 해결에서 언어 모델의 성능 향상 |
| 문제 정의 | - 기존 언어 모델은 학습 데이터의 한계로 인해 비논리적 추론 및 사실적 오류를 생성할 가능성이 높음 - 단일 모델 기반의 접근법으로는 문제 해결이 어려움 |
| 주요 기법 | 다중 에이전트 토론(Multiagent Debate) - 여러 에이전트가 개별 답변을 생성한 후, 서로의 답을 검토 및 비판하여 수정 - 라운드 수를 정해 토론 후 최종적으로 합의된 답 도출 |
| 연구 방법 | 1. 초기 답변 생성: 각 에이전트가 동일한 입력에 대해 독립적으로 답 생성 2. 토론 과정: 각 에이전트가 상대 에이전트의 답변을 분석 및 비판 3. 최종 답변 수렴: 라운드 종료 후 합의된 최종 답 결정 |
| 실험 데이터 | - GSM8K 데이터셋: 수학 문제 해결 능력을 평가 - 다양한 수리적 추론, 전략적 의사 결정, 사실적 질문 응답 태스크 |
| 실험 결과 | - 단일 모델 성능: ChatGPT: 14/20 문제 해결, Bard: 11/20 문제 해결 - 다중 에이전트 토론: 17/20 문제 해결 (85% 정확도) - 협력을 통해 개별 모델의 한계를 보완하며 더 나은 성능을 기록 |
| Figure 사례 | - Figure 11: Windows 업데이트와 다운로드 시간 문제 - ChatGPT와 Bard가 각자 오류를 범했으나, ChatGPT가 Bard의 답을 활용하여 최종적으로 올바른 답(160분)을 도출 |
| 기여 | 1. 협력 기반 문제 해결: 다중 에이전트가 상호작용을 통해 개별 모델보다 뛰어난 성능을 달성 2. 일반화 가능성: 다양한 문제와 데이터셋에 적용 가능 3. 성능 향상: 기존 방법 대비 더 높은 정확도와 추론력 확보 |
| 한계점 | 1. 높은 계산 비용: 여러 모델의 병렬 실행으로 인해 비용 증가 2. 오류 전파 가능성: 잘못된 논리가 협력 과정에서 증폭될 위험 3. 라운드 최적화 필요: 과도한 라운드는 효과 감소 및 계산 부담만 초래 |
| 결론 | - 다중 에이전트 토론은 언어 모델의 성능을 향상시키는 강력한 방법론 - 협력을 통해 개별 모델의 오류를 보완하며 신뢰도 높은 결과를 생성 - 향후 다양한 AI 시스템의 협력적 설계에 중요한 기여 가능 |
| 향후 연구 방향 | 1. 효율적인 토론 설계: 라운드 수 및 에이전트 수 최적화 2. 다양한 모델 간 협력: 이질적인 모델 간 상호작용 강화 3. 실제 응용 확대: 의료, 법률, 교육 등 실생활 응용에서의 가능성 탐구 |
1. 연구의 목적 및 문제 정의
최근 대형 언어 모델(LLM)은 자연어 생성 및 이해, 그리고 소수 샘플 학습(few-shot learning)에서 뛰어난 성능을 보인다. 하지만 훈련 데이터가 인터넷 기반의 방대한 텍스트에서 추출되기 때문에 사실적 오류(factual errors)나 비논리적인 추론 오류(hallucination)가 발생할 가능성이 크다. 기존에는 프롬프트 기법(prompting techniques)이나 자체 검증(self-consistency), 체인 오브 싱킹(chain-of-thought, CoT) 등을 활용하여 모델의 정확성을 개선하려는 연구가 많았다.
본 연구에서는 다중 에이전트 토론(Multiagent Debate) 방식을 활용하여 LLM의 사실성과 추론 능력을 향상하는 방법을 제안한다. 이를 통해 다음과 같은 문제를 해결하고자 한다.
- 언어 모델이 논리적으로 일관된 추론을 수행하도록 유도
- 모델이 생성하는 정보의 사실적 정확도를 높이고 환각(hallucination)을 줄임
- 단일 모델이 아닌 다중 모델이 상호 토론을 통해 최종 답을 도출하는 과정 설계
2. 연구 방법: 다중 에이전트 토론 기법
연구진은 "마음의 사회(Society of Mind)" 개념을 차용하여, 하나의 모델이 아니라 여러 개의 언어 모델(agents) 이 개별적으로 답을 생성하고, 이를 상호 토론하여 최종적으로 하나의 답을 도출하는 방식을 제안했다.
(1) 다중 에이전트 토론 프로세스
- 초기 답안 생성
- 다수의 언어 모델 인스턴스가 동일한 입력에 대해 개별적인 답을 생성함.
- 토론 및 반론 과정
- 각 모델이 다른 모델의 답을 읽고, 이에 대한 논리적 비판을 수행한 후 자신의 답안을 업데이트함.
- 이 과정을 여러 라운드에 걸쳐 반복하여 최적의 답을 도출함.
- 최종 답안 수렴
- 모델들 간의 합의(consensus)가 이루어지면 최종 답이 결정됨.
(2) 다중 에이전트 토론의 장점
- 기존의 단일 모델 기반 검증(Reflection) 방식보다 더 강력한 추론이 가능.
- 다양한 모델이 서로 상반된 답을 제시하는 경우, 공통적으로 신뢰할 수 있는 답으로 수렴하는 경향이 있음.
- 사실적 오류(factual errors) 를 포함한 답변이 토론을 거치면서 자동으로 제거됨.
3. 실험 및 성능 평가
연구진은 다중 에이전트 토론이 실제로 LLM의 성능을 향상하는지를 검증하기 위해 여러 실험을 수행했다.
(1) 실험 설계
- 실험은 3가지 주요 태스크에서 수행됨.
- 수리적 추론(Mathematical Reasoning)
- 기본 산술(arithmetic) 문제와 초등학교 수준의 수학 문제(GSM8K 데이터셋)를 풀도록 함.
- 전략적 추론(Strategic Reasoning)
- 체스에서 최적의 다음 수를 예측하는 태스크.
- 사실적 정확성(Factuality Accuracy)
- 역사적 인물의 전기(biographies) 생성 태스크 수행.
- MMLU(Massive Multitask Language Understanding) 데이터를 활용한 사실적 질문 답변 평가.
- 수리적 추론(Mathematical Reasoning)
(2) 실험 결과
- 다중 에이전트 토론 방식이 기존 방법보다 더 높은 정확도를 달성함.
- 특히, 잘못된 초깃값을 가진 답변들도 토론을 거치면서 올바른 답으로 수렴하는 현상이 관찰됨.
- 사실적 정확성(factual accuracy)이 유의미하게 개선되었으며, 특히 역사적 인물 전기 생성에서 거짓 정보를 줄이는 효과가 나타남.
- 체스 최적 수 예측에서도 다중 에이전트 토론 방식이 기존 단일 모델 기반 방법보다 더 높은 점수를 기록함.
| 모델 | 산술(%) ↑ | 초등 수학(%) ↑ | 체스(ΔPS) ↑ |
| 단일 모델 | 67.0 ± 4.7 | 77.0 ± 4.2 | 91.4 ± 10.6 |
| 단일 모델 (반성 적용) | 72.1 ± 4.5 | 75.0 ± 4.3 | 102.1 ± 11.9 |
| 다중 에이전트 (다수결) | 69.0 ± 4.6 | 81.0 ± 3.9 | 102.2 ± 6.2 |
| 다중 에이전트 (토론) | 81.8 ± 2.3 | 85.0 ± 3.5 | 122.9 ± 7.6 |
4. 분석 및 추가 실험
(1) 토론 에이전트 수 증가 효과
- 에이전트 수가 많아질수록 더 정확한 답을 도출함.
- 하지만 너무 많은 에이전트를 사용할 경우 계산량 증가로 인한 비용이 발생.
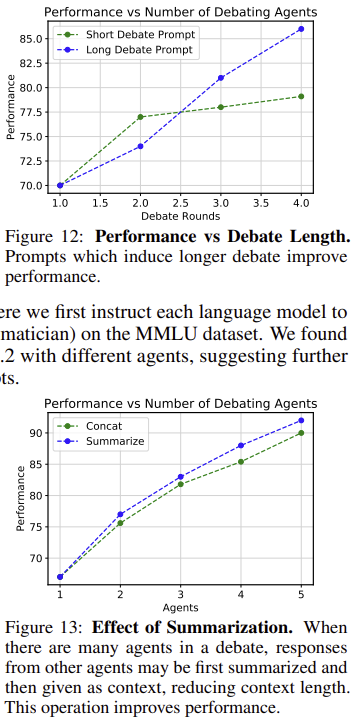
(2) 토론 라운드 수 증가 효과
- 최대 4라운드까지는 성능이 점진적으로 향상되었으나, 4라운드 이후에는 추가적인 개선 효과가 크지 않음.
(3) 다른 모델과의 토론 효과
- ChatGPT와 Google Bard 모델을 섞어서 실험한 결과, 서로 다른 언어 모델이 협력하여 성능을 향상할 수 있음이 확인됨.
5. 연구의 한계점 및 미래 연구 방향
(1) 높은 계산 비용
- 다중 모델을 사용해야 하므로 계산 비용이 기존 방법보다 높음.
- 하지만 학습 데이터를 추가 생성하는 방식으로 활용하면 비용 문제를 해결할 수도 있음.
(2) 정보가 틀린 경우에도 합의가 이루어질 수 있음
- 모델들이 토론을 거쳐 하나의 답으로 수렴하지만, 이 답이 반드시 정답이라는 보장은 없음.
- 즉, 모델들이 동일한 오류를 공유하게 될 수도 있음.
(3) 긴 토론의 처리 문제
- 모델이 긴 토론을 다룰 때, 최근 정보에 집중하는 경향이 있음.
- 이 문제는 컨텍스트 길이를 늘리거나 토론 내용을 요약하는 방식으로 해결 가능.
6. 결론 및 연구 기여
본 연구에서는 다중 에이전트 토론 기법을 통해 언어 모델의 사실성과 추론력을 향상하는 방법을 제안했다.
이 연구의 주요 기여는 다음과 같다.
- 다중 에이전트 토론 기법을 최초로 적용하여 LLM 성능을 개선
- 사실적 정확성을 평가할 수 있는 새로운 벤치마크 데이터셋을 구축
- 수학, 논리적 추론, 전략적 의사 결정, 정보 검색 등 다양한 태스크에서 효과 검증
- 기존 방법(체인 오브 싱킹, 자체 검증)과 결합하여 더 높은 성능을 달성할 수 있음을 입증
이 연구는 향후 LLM의 신뢰성과 추론 능력을 개선하는 중요한 토대를 제공하며, 강력한 AI 시스템 개발을 위한 기반 연구로 활용될 수 있다.

네, 제공하신 Figure를 기반으로 보면, 논문에서 제안하는 다중 에이전트 토론(Multiagent Debate)은 여러 언어 모델(Agent)들이 각자의 답을 제시하고, 다른 에이전트들의 답변을 분석 및 비판하며 자신의 답을 수정하는 과정을 반복합니다. 중요한 특징은 다음과 같습니다:
- 정해진 턴(Turn) 기반 진행
- 논문에서 제안하는 방식은 "동적으로 종료"를 판단하기보다는, 정해진 라운드 수 (예: 3 라운드) 내에서 토론을 진행합니다. 각 라운드에서 에이전트들은 자신의 답을 수정하고, 최종적으로 라운드 종료 후 하나의 답에 합의하거나 다수결 방식으로 결과를 정합니다.
- 라운드 내 상호 참조 및 비판
- 첫 번째 라운드에서는 각 에이전트가 독립적으로 답변을 생성합니다.
- 이후 라운드에서는 이전 라운드에서 제시된 답변들을 기반으로 비판, 수정, 보완하여 자신의 새로운 답변을 생성합니다.
- 최종 라운드에서 합의된 답 도출
- 마지막 라운드에서는 각 에이전트가 자신의 결론을 제시하며, 일반적으로 다수결 방식 또는 논리적으로 가장 일관된 답이 최종 결과로 채택됩니다.
Figure의 사례를 보면:
- Round 1: 에이전트 1과 2가 각각 독립적으로 답변을 생성하며 상반된 결과를 제시.
- Round 2: 서로의 답을 참조하며 수정, 보완된 답변을 제시.
- Round 3: 이전 논의 결과를 통해 에이전트들이 같은 결론(595개 보석)을 도출.
이처럼 논문에서 제안하는 방식은 에이전트 간의 상호 작용을 통해 더 신뢰할 수 있는 결론에 도달하려는 의도를 가지고 있습니다. 토론 종료는 사전에 정해진 라운드 수에 따라 종료되며, 특정 기준에 의해 동적으로 결정되지는 않습니다.

다중 모델을 활용한 다중 에이전트 토론 결과
1. 실험 개요
논문에서는 다양한 언어 모델(ChatGPT와 Bard)을 활용한 다중 에이전트 토론의 효과를 평가했습니다.
20개의 GSM8K 수학 문제 세트를 대상으로 두 모델이 협력하여 문제를 해결하는 성능을 비교했으며, Figure 11에서 이 과정을 구체적으로 설명합니다.
2. 실험 방법
- 모델 구성: ChatGPT와 Bard라는 두 서로 다른 언어 모델을 에이전트로 활용.
- 평가 데이터: GSM8K 데이터 세트에서 선택된 20개의 수학 문제를 사용.
- 토론 방식:
- 각 에이전트가 독립적으로 첫 번째 답변을 생성.
- 각 에이전트는 상대 에이전트의 답변을 검토하고, 이를 기반으로 자신의 답변을 수정 및 보완.
- 최종적으로 합의된 답안을 도출.
3. 주요 결과
- ChatGPT와 Bard 개별 모델의 성능:
- Bard: 20개 중 11개 문제 해결.
- ChatGPT: 20개 중 14개 문제 해결.
- 다중 에이전트 토론 결과:
- 두 모델이 토론을 통해 20개 중 17개의 문제를 해결하며, 개별 성능보다 높은 정확도를 기록.
4. Figure 11에 대한 사례 분석
Figure 11에서는 두 모델(ChatGPT와 Bard)이 협력하여 수학 문제를 해결하는 과정을 설명합니다.
(1) 문제 설명
- Carla가 200GB 파일을 다운로드합니다.
- 다운로드 속도는 2GB/분.
- 파일의 40%를 다운로드했을 때, Windows가 재시작을 요구하고 20분간 업데이트를 진행합니다.
- Carla는 이후 다시 처음부터 다운로드를 시작해야 합니다.
- 총 다운로드에 걸리는 시간은?
(2) 각 모델의 초기 답변 (Round 1)
- ChatGPT의 초기 답변:
- Carla가 재시작 후 120분이 걸린다고 계산했으나, 실제로는 초기 다운로드 시간을 고려하지 않아 오류 발생.
- Bard의 초기 답변:
- 재시작 후 100분이 걸린다고 계산했으나, 40%의 다운로드가 무효화된다는 점을 간과.
(3) 수정 및 최종 답변 (Round 2)
- ChatGPT가 Bard의 답변을 검토하고, 초기 다운로드된 40%가 무효화되며 처음부터 다운로드를 재시작해야 한다는 점을 반영.
- ChatGPT가 최종적으로 160분이라는 올바른 답변을 도출.
5. 분석
- 개별 모델의 오류:
- 초기 답변에서 두 모델 모두 계산 과정에서 오류를 범함.
- ChatGPT는 부분적으로 문제를 과소 계산했고, Bard는 40%의 다운로드 손실을 고려하지 않음.
- 다중 에이전트 협력의 장점:
- ChatGPT가 Bard의 잘못된 논리를 반영하여 자신의 계산을 수정.
- 협력 과정에서 상호 비판 및 보완을 통해 더 정확한 답변(160분)을 도출.
6. 결론
다중 에이전트 토론을 통해 개별 모델의 약점을 상호 보완하며 더 높은 성능을 기록할 수 있음을 확인했습니다.
특히, 모델 간 협력은 개별 모델이 독립적으로 생성하는 오류를 줄이고, 더 신뢰할 수 있는 결과를 생성하는 데 크게 기여했습니다.
이 접근 방식은 향후 다양한 언어 모델을 결합하여 복잡한 문제 해결이나 학습 효과를 극대화하는 데 응용될 수 있습니다.
논문의 결과, 결론, 그리고 마무리
1. 연구 결과
본 연구는 다중 에이전트 토론(Multiagent Debate)을 활용하여 언어 모델의 사실성(factuality)과 추론 능력을 향상하는 방법을 제안하며, 다음과 같은 주요 결과를 도출했습니다.
(1) 성능 향상
- 다중 에이전트 토론 기법은 기존 단일 모델 기반 접근법보다 더 나은 성능을 보임.
- GSM8K 수학 문제 데이터셋 실험 결과:
- 단일 ChatGPT 모델: 14문제 해결
- 단일 Bard 모델: 11문제 해결
- 다중 에이전트 토론: 17문제 해결 (약 85% 정확도)
- GSM8K 수학 문제 데이터셋 실험 결과:
(2) 협력의 시너지 효과
- 다중 에이전트 토론 과정에서 개별 모델의 오류를 상호 비판 및 수정하여, 더 신뢰할 수 있는 답변으로 수렴.
- 예시: Figure 11의 Windows 업데이트 문제에서, Bard와 ChatGPT가 초기 답변에서 각각 오류를 범했으나, 협력을 통해 최종적으로 올바른 답(160분)을 도출.
(3) 다양한 태스크에서의 개선
- 수학적 추론, 전략적 문제 해결, 사실적 질문 응답 등 다양한 태스크에서 다중 에이전트 토론이 성능을 향상함.
- 다중 에이전트 시스템이 단일 모델 기반의 접근보다 더 견고하며, 다양한 오류를 줄이는 데 효과적임.
2. 결론
(1) 주요 기여
- 다중 에이전트 토론 기법 도입:
- 여러 언어 모델이 협력 및 경쟁하며 사실성(factual accuracy)과 추론력을 향상할 수 있음을 입증.
- 특히, 모델 간 상호작용이 개별 모델의 한계를 보완하며, 최종적으로 더 나은 답변을 도출.
- 효과적이고 일반화 가능한 방법론:
- 본 연구는 특정 태스크나 데이터셋에 국한되지 않고, 다양한 문제와 태스크에 적용 가능한 일반적 방법론을 제안.
- 단순한 모델 성능 비교를 넘어, 협력을 통한 모델 강화라는 새로운 방향성을 제시.
(2) 한계점
- 높은 계산 비용:
- 다중 에이전트 토론은 여러 모델을 병렬로 실행해야 하므로 계산 비용이 기존보다 높음.
- 이는 실제 적용 시 비용 효율성을 고려해야 하는 과제로 남음.
- 토론 중 오류 전파 가능성:
- 에이전트 간 상호작용이 때때로 잘못된 정보나 논리를 증폭할 가능성도 존재.
- 따라서 토론 과정에서의 신뢰도 평가 메커니즘이 필요.
- 라운드 수와 에이전트 수의 최적화 필요:
- 과도한 라운드 수는 성능 향상 효과가 미미하며, 계산 부담만 증가시킬 수 있음.
- 에이전트 수와 라운드 수에 대한 최적화 연구가 필요함.
3. 마무리 및 연구 방향
(1) 연구 의의
- 다중 에이전트 토론은 언어 모델의 신뢰성과 추론력을 향상시키는 새로운 방법으로, 미래의 AI 협력 시스템 개발에 중요한 역할을 할 수 있음.
- 특히, 단일 모델의 한계를 넘어서 다중 모델 간의 상호작용을 통해 더 높은 수준의 문제 해결이 가능하다는 점을 증명.
(2) 향후 연구 방향
- 효율적인 토론 구조 설계:
- 계산 비용 문제를 해결하기 위해, 에이전트 수와 라운드 수를 최적화하는 연구가 필요.
- 라운드 기반 토론 외에도, 동적으로 종료 조건을 결정하는 방식을 탐구 가능.
- 다양한 모델 간 협력 연구:
- 이질적인 모델(Bard, ChatGPT 등)을 조합하여 협력의 효과를 극대화하는 방법 탐구.
- 모델 간 지식 교환과 오류 보완 메커니즘 강화.
- 실제 응용 사례 확대:
- 본 연구에서 제안한 방법론을 의료, 법률, 교육, 데이터 분석 등 실생활의 다양한 문제에 적용 가능.
- 예를 들어, 법률 자문 시스템에서 다중 에이전트를 활용해 더 신뢰할 수 있는 법적 의견 생성.
4. 종합
이 연구는 다중 에이전트 토론을 통해 대형 언어 모델의 성능 한계를 극복하고, 협력을 통해 새로운 수준의 성능을 달성할 수 있음을 보여줍니다.
향후 연구를 통해 이러한 협력 기반 접근법이 더욱 정교해지고, 다양한 응용 분야에 혁신적인 영향을 미칠 것으로 기대됩니다.
논문의 방법과 연구 방향성 검증
1. 연구의 주장: 다중 에이전트 토론
논문은 언어 모델의 사실성과 추론력을 개선하기 위해 다중 에이전트 토론(Multiagent Debate) 방식을 제안합니다. 이 주장을 검증하기 위해 아래와 같은 요소를 분석합니다.
2. 방법론 검증
Step 1: 문제 정의의 타당성
- 문제 제기: 언어 모델은 데이터 기반 학습의 한계로 인해 환각(hallucination)과 논리적 오류를 범함.
- 타당성: 기존 연구에서도 대형 언어 모델의 오류와 사실성 문제는 잘 알려진 한계임. 따라서 이를 해결하려는 접근은 연구적으로 타당합니다.
- 가설: 다중 에이전트가 상호작용하며 오류를 보완할 수 있다.
- 타당성: 인간의 의사 결정 과정에서 다양한 관점의 논의를 통해 결론을 도출하는 것과 유사한 접근으로, 심리학적 및 협업 기반 문제 해결 이론에 부합합니다.
Step 2: 제안한 방법의 논리적 구조
- 초기 답변 생성: 각 에이전트가 독립적으로 답변을 생성.
- 논리적 검증: 서로 독립적인 답변은 편향을 줄이고, 다양한 시각을 확보하는 데 유리합니다.
- 토론 및 비판 과정: 에이전트가 서로의 답변을 비판하고 자신의 답을 수정.
- 논리적 검증:
- 오류가 있는 답변은 다른 에이전트의 비판을 통해 수정될 가능성이 높음.
- 다중 관점에서의 검토는 더 높은 신뢰도와 정확도로 이어질 가능성이 있음.
- 실제 Figure 11 사례에서, 초기에는 두 모델이 모두 오류를 범했으나, 상호 검토를 통해 올바른 답을 도출함.
- 논리적 검증:
- 최종 답변 수렴: 일정 라운드 후 합의된 답을 도출.
- 논리적 검증:
- 라운드를 제한함으로써 불필요한 계산 비용을 줄이고, 실용성을 확보함.
- 다만, 동적으로 라운드를 종료하는 메커니즘이 없으므로, 적정 라운드 수 설정이 필수적임.
- 논리적 검증:
Step 3: 실험 설계의 타당성
- GSM8K 데이터셋 사용:
- GSM8K는 수학적 추론을 요구하는 문제들로 구성되어 있어 언어 모델의 추론력과 논리성을 평가하기에 적합.
- 데이터셋 선택은 타당함.
- 다중 에이전트와 단일 모델 비교:
- 단일 ChatGPT, 단일 Bard와 다중 에이전트 협력 결과를 비교하여 성능 향상을 검증.
- 비교 기준이 명확하고, 성능 향상을 실험적으로 입증했음.
- 결과 해석:
- 다중 에이전트가 20개 중 17개 문제를 해결(85%)하며, 개별 모델 성능(14개, 11개 해결)보다 높은 성능을 보임.
- 실제 사례(Figure 11)에서 오류를 수정하고 올바른 답을 도출한 사례는 가설을 뒷받침함.
Step 4: 한계점 및 보완
- 계산 비용 문제:
- 다중 에이전트를 사용하면 계산 비용이 단일 모델에 비해 기하급수적으로 증가.
- 이를 보완하기 위해 에이전트 수와 라운드 수의 최적화 필요.
- 오류 전파 가능성:
- 에이전트가 서로의 오류를 보완하지 못하면, 오히려 잘못된 결론으로 수렴할 가능성 존재.
- 신뢰도 평가 메커니즘이나 가중치 기반 평가 시스템 추가가 필요.
- 적정 라운드 수의 설계:
- 라운드 수가 너무 적으면 충분한 토론이 이루어지지 않고, 너무 많으면 계산 비용이 증가.
- 동적 라운드 종료 조건 설계가 연구 방향으로 필요.
3. 연구 방향성의 타당성
논문의 연구 방향은 기존 언어 모델의 한계를 해결하려는 실질적이고 유의미한 접근법을 제시하며, 다음과 같은 점에서 타당성을 갖습니다.
- 새로운 협력 기반 접근법:
- 단일 모델 중심의 기존 접근을 넘어, 협력 기반의 문제 해결로 새로운 가능성을 열었음.
- 이는 기존 연구와 차별화된 독창성을 보여줌.
- 일반화 가능성:
- 다중 에이전트 토론 기법은 수학 문제뿐만 아니라 법률, 의료, 데이터 분석 등 다양한 응용 분야에 적용 가능.
- 실제로 여러 분야에서 다중 에이전트 협력 시스템 개발에 활용될 수 있음.
- 성능 개선 가능성 입증:
- 실험 결과를 통해 다중 에이전트 협력이 단일 모델 대비 성능 향상을 가져온다는 점을 입증.
- 이는 추후 연구자들이 이 접근법을 기반으로 더 발전된 시스템을 설계하도록 유도.
4. 종합 평가
- 논리적 일관성: 논문의 가설, 방법론, 실험 설계, 결과는 서로 밀접하게 연결되어 있어 높은 논리적 일관성을 보임.
- 타당성: 기존 문제를 해결하려는 방식과 실험 결과는 타당하며, 방법론의 효과가 입증됨.
- 미래 가능성: 연구는 단순한 언어 모델 개선을 넘어, AI 협력 시스템이라는 새로운 패러다임을 제시.
결론적으로, 논문의 주장과 연구 방향은 타당하며, 다중 에이전트 토론 기법은 언어 모델의 성능을 개선하는 효과적인 접근법으로 평가할 수 있습니다. 다만, 계산 비용 및 오류 전파 문제를 해결하기 위한 후속 연구가 필요합니다.