https://arxiv.org/abs/2005.14165
Language Models are Few-Shot Learners
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fi
arxiv.org

Few-Shot은 이 그림으로 명확하게 설명이 가능하겠네요
파라미터의 변경 없이 Prompt에 몇 개의 예시만으로 Fine-Tuning을 뛰어넘는 성능을 보여줍니다.
In-Context-Learning이라는 개념을 처음 도입한 논문으로 Agent에 필수적으로 사용되는 Prompting 기술입니다.
하지만 역시 모델의 다양성 부족인지, 아니면 초기 모델의 한계인지 대규모 모델이 아니면 Few-Shot의 성능이 떨어집니다.

이 Figure를 보면 175B가 넘어야 Few-Shot의 성능이 확실하게 보이는 것을 볼 수 있습니다.
또한 No Prompt를 통해 Instruction의 중요성을 나타내줍니다.

이 논문에선 Few-Shot 뿐만이 아니라 다양한 GPT-3의 학습 내용을 보여줍니다.
여기에 집중하지 않을 것이라 다루지는 않겠지만 GPT에 대해 궁금하고, 학습이 어떻게 이루어지는지 궁금하시다면 읽어보시는 것도 좋아보입니다.
| 연구 목표 | - Fine-Tuning 없이도 Zero-Shot, One-Shot, Few-Shot 학습을 통해 강력한 성능을 발휘하는 대규모 언어 모델 개발. - In-Context Learning을 통해 새로운 태스크를 효율적으로 학습 및 수행. |
| 모델 크기 | - 총 8가지 크기(125M ~ 175B 파라미터) 모델 학습. - GPT-3 175B는 가장 큰 모델로, 2048 토큰 컨텍스트 윈도우를 사용. |
| 아키텍처 | - Transformer 기반 Autoregressive 모델. - Sparse Attention 패턴 활용. - Feedforward 레이어는 bottleneck 크기의 4배. - 모든 모델은 Byte-Pair Encoding(BPE)를 사용해 토큰화 수행. |
| 학습 데이터 | - Common Crawl, WebText2, Books1/Books2, Wikipedia 등에서 수집. - 약 3000억 개의 토큰, 570GB의 고품질 텍스트. - 데이터 품질 개선을 위해 중복 제거와 필터링 수행. |
| 학습 방법 | - 학습은 Microsoft 제공 V100 GPU 클러스터에서 병렬 처리. - 배치 크기와 학습률은 모델 크기에 따라 조정. - 최대 3000억 개의 토큰으로 학습. - Train Loss와 Validation Loss가 안정적으로 수렴. |
| 평가 방식 | - Zero-Shot: 지시어만 제공. - One-Shot: 지시어 + 1개의 예제 제공. - Few-Shot: 지시어 + 여러 개의 예제 제공(K=10~100). |
| 주요 성능 | - LAMBADA (Few-Shot): 정확도 86.4%(SOTA: 68.0%). - TriviaQA (Few-Shot): 정확도 71.2%(Fine-Tuned 모델과 동등). - CoQA (Few-Shot): 85.0 F1(Fine-Tuned 모델과 유사). - 일부 태스크에서 사람 수준의 성능. |
| In-Context Learning 특징 | - 컨텍스트 내 예제(K)가 많아질수록 성능 향상. - 자연어 지시어(Natural Language Prompt)를 제공하면 학습 효율이 크게 증가. - 지시어 없이(No Prompt) 작업을 수행할 경우 성능 저하. |
| 모델 크기와 성능 관계 | - 모델 크기와 학습 데이터가 증가할수록 Validation Loss가 전력 법칙(Power Law)을 따라 감소. - 175B 모델은 작은 모델에 비해 더 효율적으로 학습하고 더 낮은 Loss를 기록. |
| 한계 | - 논리적 추론(NLI) 및 복잡한 태스크(ANLI, RACE)에서 성능 저하. - 학습 데이터 편향으로 인한 부정확한 결과. - Character Manipulation(예: 철자 반전)에서 성능 저하. |
| 연구 기여 | - Fine-Tuning 없이도 Few-Shot 학습으로 SOTA 성능을 초과하거나 근접. - 새로운 태스크를 예제와 지시어로 학습하는 In-Context Learning의 가능성 제시. - Prompt Engineering의 중요성을 강조. |
| 향후 연구 방향 | - Prompt Engineering 최적화. - Fine-Tuning과 In-Context Learning 결합. - 데이터 편향 해결 및 고품질 학습 데이터 확장. - 논리적 추론과 같은 고난이도 태스크 성능 향상. |
1. 연구의 배경과 문제 정의
기존의 NLP 시스템들은 대규모 언어 모델을 사전 학습한 후, 특정 작업에 대해 미세 조정(fine-tuning)하는 방식이 주류였습니다. 하지만 이는 특정 작업을 수행하기 위해 수천~수만 개의 레이블된 데이터를 필요로 했으며, 일반화 능력이 떨어지는 문제가 있었습니다.
반면, 인간은 새로운 언어 작업을 수행할 때 극소수의 예제만 보고도 적응할 수 있습니다. 이러한 인간의 학습 방식을 모방하기 위해 연구진은 대규모 모델을 단순한 프롬프팅만으로 활용할 수 있는지 탐구하였습니다.
주요 연구 질문
- 대규모 언어 모델을 활용하여 Few-Shot Learning(소수의 예제만으로 학습) 성능을 높일 수 있는가?
- 모델의 크기를 확장할수록 Few-Shot Learning 능력이 향상되는가?
- 특정 작업에 대해 Fine-Tuning 없이 단순한 텍스트 프롬프팅만으로도 높은 성능을 달성할 수 있는가?
2. 연구 방법
2.1 모델 및 아키텍처
- 연구진은 GPT-3(175B 파라미터)를 포함한 여러 크기의 GPT 모델을 학습함.
- 모델은 GPT-2 아키텍처를 기반으로 하되, 파라미터 수를 확장함.
- 8개의 다른 크기의 모델(125M ~ 175B)을 비교하여 성능 변화를 분석.
2.2 학습 데이터
- Common Crawl(필터링된 웹 데이터), WebText2, Wikipedia, Books Corpus 등을 조합하여 학습.
- 총 3000억 개의 토큰을 사용하여 모델을 학습함.
- 일부 벤치마크 데이터셋과 겹치는 데이터가 존재했지만, 이를 분석하여 결과에 미치는 영향을 평가함.
2.3 평가 방식
- 모델을 사전 학습한 후, Few-Shot Learning 방식으로 다양한 NLP 태스크를 평가함.
- Fine-Tuning 없이 순수 텍스트 프롬프팅만으로 모델을 조정함.
- Zero-Shot, One-Shot, Few-Shot 설정을 비교.
- Zero-Shot: 단순한 지시어(prompt)만 제공
- One-Shot: 단 하나의 예제와 지시어 제공
- Few-Shot: 여러 개(10~100)의 예제를 함께 제공
3. 실험 결과
3.1 모델 크기 확장과 Few-Shot 학습 능력
- 모델 크기를 확장할수록 Few-Shot Learning 성능이 크게 향상됨.
- Zero-Shot과 One-Shot 성능도 모델 크기 증가에 따라 개선됨.
- 특히, 175B 모델(GPT-3)은 일부 작업에서 Fine-Tuned 모델과 비슷한 성능을 보임.
3.2 다양한 NLP 태스크에서의 성능 분석
(1) 문장 완성 및 Cloze 테스트
- LAMBADA 데이터셋에서 Zero-Shot 76.2%, Few-Shot 86.4%의 성능을 기록하며 기존 SOTA(68%)를 크게 초월함.
- 단순한 프롬프팅만으로도 문맥을 이해하고 정답을 예측하는 능력이 향상됨.
(2) 질의응답 (Question Answering)
- GPT-3는 TriviaQA에서 Few-Shot 71.2% F1 점수를 기록, Fine-Tuned 모델과 비슷한 성능을 보임.
- 하지만 일부 데이터셋(WebQuestions, Natural Questions)에서는 아직 Fine-Tuned 모델보다 성능이 낮음.
(3) 번역 (Translation)
- 프롬프트를 이용한 Few-Shot 번역에서도 좋은 성능을 보였으나, 최신 NMT 모델보다 BLEU 점수는 다소 낮음.
- 특히, 영어에서 다른 언어로 번역하는 경우보다 다른 언어에서 영어로 번역할 때 성능이 더 뛰어남.
(4) 문장 논리적 관계 분석 (NLI, Winograd)
- SuperGLUE 벤치마크에서는 일부 과제에서 Fine-Tuned 모델과 비슷한 성능을 달성.
- 하지만 추론이 필요한 논리적 관계 분석(NLI)에서는 아직 부족한 성능을 보임.
(5) 코드 생성 및 수학 문제 해결
- GPT-3는 간단한 산술 연산(2자리 덧셈, 뺄셈)에서는 높은 정확도를 보였지만, 4자리 이상의 연산에서는 정확도가 크게 감소함.
- 기초적인 논리 및 패턴을 학습하는 능력은 보였으나, 정형화된 규칙 기반 문제 해결에는 한계가 있음.
4. 주요 한계점
- 논리적 추론 부족
- NLI 및 일부 QA 태스크에서 인간 수준의 추론이 부족.
- 모델이 정답을 맞출 확률이 높아지는 것이지, 논리적으로 정답을 도출하는 것이 아님.
- 데이터 편향 (Bias)
- 모델이 훈련 데이터에서 편향을 학습하여 특정 인종, 성별, 종교적 편향을 보임.
- 예를 들어, ‘의사’라는 단어는 남성으로, ‘간호사’는 여성으로 연결될 확률이 높았음.
- 모델 크기에 따른 비용 및 환경 영향
- GPT-3는 훈련에 수천 PetaFLOPs의 연산 비용이 필요하며, 이는 상당한 에너지를 소비함.
- 실시간 사용에도 높은 계산 비용이 발생하여 실용성이 낮을 수 있음.
- 제어 및 안전성 문제
- 생성된 텍스트의 일관성과 신뢰성이 떨어지는 경우가 많음.
- 악용 가능성이 있으며, 특히 허위 정보(fake news) 생성이 쉬워질 수 있음.
5. 결론 및 연구 방향
- GPT-3는 Fine-Tuning 없이 단순한 Few-Shot Learning만으로도 강력한 성능을 보였음.
- 모델 크기를 확장하면 Few-Shot 학습 능력이 더욱 향상됨을 확인.
- 하지만 논리적 추론, 데이터 편향, 계산 비용 등의 문제점 해결이 필요함.
- 향후 연구 방향:
- MoE(Mixture of Experts) 적용: 비용을 줄이면서 대규모 모델의 성능 유지.
- 멀티모달 학습: 텍스트뿐만 아니라 영상, 소리 등 다양한 데이터를 함께 학습.
- 강화학습 및 인간 피드백 활용: 보다 정확하고 신뢰할 수 있는 답변을 생성하는 방향으로 연구.
6. 연구의 시사점
- 기존 NLP 모델이 필요로 했던 Fine-Tuning 없이도, 단순한 프롬프팅만으로 높은 성능을 낼 수 있는 가능성을 보여줌.
- 이는 Prompt Engineering 기술의 중요성을 더욱 부각시킴.
- 향후 연구에서 Prompt 디자인을 최적화하는 방법이 중요한 연구 분야로 떠오를 것으로 예상됨.
이 논문은 프롬프팅을 활용한 NLP 모델의 가능성을 극대화한 대표적인 연구이며, 향후 LLM 연구에서 핵심적인 레퍼런스로 활용될 것입니다.
연구 방법
논문 "Language Models are Few-Shot Learners"에서 연구진은 GPT-3를 중심으로 한 대규모 언어 모델을 활용하여 Few-Shot Learning의 가능성을 탐구했습니다. 연구 방법을 세부적으로 살펴보겠습니다.
1. 모델 아키텍처
1.1 GPT-3의 기본 구조
- Transformer 기반 Autoregressive 모델
- GPT-3는 GPT-2와 같은 Transformer 모델을 기반으로 함.
- 입력 시퀀스를 토큰 단위로 처리하며, 이전 토큰을 기반으로 다음 토큰을 예측하는 방식.
- Fine-Tuning 없이 프롬프트만 제공하는 방식으로 Few-Shot Learning 성능을 평가함.
- 크기별 모델 스케일링
- 모델 크기를 125M(1.25억) ~ 175B(1750억) 파라미터까지 확장하여 비교 실험 수행.
- 아래 표는 논문에서 사용된 다양한 크기의 모델 아키텍처입니다.
| 모델 명 | 파라미터 수 | 레이어 수 | 히든 유닛 수 | 헤드 수 |
| GPT-3 Small | 125M | 12 | 768 | 12 |
| GPT-3 Medium | 350M | 24 | 1024 | 16 |
| GPT-3 Large | 760M | 24 | 1536 | 16 |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 |
| GPT-3 13B | 13B | 40 | 5140 | 40 |
| GPT-3 175B | 175B | 96 | 12288 | 96 |
- 컨텍스트 길이(Context Window):
- 모든 모델은 최대 2048개의 토큰을 입력으로 받을 수 있도록 학습됨.
- Few-Shot 학습을 위해 컨텍스트 내에서 여러 개의 예제(최대 100개)를 제공.
- 학습 최적화 기법
- Adam 옵티마이저(β1=0.9, β2=0.95, ε=10⁻⁸) 사용.
- 학습 속도 조절을 위해 Cosine Decay 스케줄링 적용.
- Weight Decay = 0.1을 사용하여 과적합 방지.
- 모델 병렬화 기법 사용(모델 크기가 크기 때문에 다중 GPU 클러스터 활용).
2. 학습 데이터
2.1 사용된 데이터셋
GPT-3는 다양한 대규모 텍스트 데이터를 학습 데이터로 사용하였습니다. 주요 데이터셋 구성은 다음과 같습니다.
| 데이터셋 | 토큰 수(억) | 전체 학습 데이터에서의 비율 |
| Common Crawl (필터링됨) | 410 | 60% |
| WebText2 | 19 | 22% |
| Books1 | 12 | 8% |
| Books2 | 55 | 8% |
| Wikipedia (영어) | 3 | 3% |
2.2 데이터 전처리 과정
- Common Crawl 필터링:
- 웹 크롤링 데이터 중 질 낮은 문서 제거.
- 품질 높은 코퍼스(예: Wikipedia, Books Corpus)와 유사성이 높은 데이터를 선별하여 학습.
- 필터링 후 약 570GB의 텍스트(4000억 개의 토큰) 사용.
- 데이터 중복 제거(Deduplication):
- 동일한 문장이나 문서가 반복 학습되지 않도록 MinHashLSH 기법을 이용한 유사도 검사 후 제거.
- 테스트 데이터 중복 방지:
- 일부 벤치마크 데이터가 학습 데이터에 포함될 가능성이 있어 이를 탐지하고 제거하는 작업 수행.
3. 평가 방식
3.1 Few-Shot Learning 평가 방법
GPT-3는 Fine-Tuning 없이 프롬프트 기반 학습 방식으로 평가되었습니다. 3가지 설정을 비교함.
| 학습 설정 | 설명 |
| Zero-Shot | 질문만 제공하고, 답변을 생성하도록 함 |
| One-Shot | 질문과 함께 정답 예제 1개 제공 후 답변을 생성 |
| Few-Shot | 질문과 함께 정답 예제 여러 개(10~100개) 제공 후 답변 생성 |
3.2 실험에 사용된 태스크
GPT-3의 Few-Shot 성능을 검증하기 위해 다양한 NLP 태스크에서 평가가 진행됨.
| 테스크 | 설명 | 주요 데이터 셋 |
| 언어 모델링 | 문맥을 기반으로 문장 완성 | LAMBADA |
| 기계 독해 (QA) | 문서 내에서 질문에 대한 정답 찾기 | SQuAD, TriviaQA |
| 번역 (MT) | 영어↔다른 언어 간 번역 수행 | WMT'14 |
| 문장 완성 | 문장에서 빠진 단어를 채우기 | StoryCloze, HellaSwag |
| 논리적 추론 (NLI) | 두 문장의 관계 분석 | RTE, ANLI |
| 문법 및 문장 교정 | 잘못된 문장 수정 | WiC, WSC |
4. Few-Shot Learning의 효과 분석
4.1 모델 크기와 Few-Shot 성능 비교
- 모델 크기가 커질수록 Few-Shot 학습 성능이 급격히 향상됨.
- Zero-Shot과 One-Shot 성능도 향상되지만, Few-Shot에서 가장 큰 성능 향상을 보임.
(1) LAMBADA (언어 모델링)
| 설정 | 13B | 175B |
| Zero-Shot | 69.0% | 76.2% |
| One-Shot | 72.5% | 78.1% |
| Few-Shot | 81.3% | 86.4% |
(2) TriviaQA (질의응답)
| 13B | 175B | |
| Zero-Shot | 41.8% | 64.3% |
| One-Shot | 51.3% | 68.0% |
| Few-Shot | 57.5% | 71.2% |
- LAMBADA: Few-Shot 설정에서 기존 SOTA(68%)보다 18% 높은 성능을 기록.
- TriviaQA: Few-Shot 설정에서 Fine-Tuned 모델과 동등한 성능을 달성.
4.2 Few-Shot의 한계
- 추론 기반 태스크(NLI, ANLI)에서는 성능이 낮음.
- 기본적인 연산(4자리 이상 덧셈, 곱셈 등)에서는 성능 저하.
- 편향(Bias) 문제: 학습 데이터에서 인종, 성별, 종교적 편향이 반영됨.
5. 결론
- GPT-3는 Few-Shot Learning을 통해 다양한 NLP 태스크에서 높은 성능을 기록.
- 모델 크기가 클수록 Few-Shot 학습 능력이 향상됨.
- Prompt Engineering이 중요한 연구 주제로 부상.
- 향후 MoE, 강화학습, 멀티모달 학습 등과 결합하여 성능 개선 가능성.
논문의 실험 결과
1. 실험 결과 요약
논문에서는 다양한 NLP 태스크에서 GPT-3의 Zero-Shot, One-Shot, Few-Shot Learning 성능을 평가하였으며, 기존의 Fine-Tuning 모델과 비교하였습니다.
1.1 Few-Shot Learning 성능 분석
1) 모델 크기 확장과 Few-Shot 학습 성능
- 모델 크기가 커질수록 Few-Shot 학습 성능이 급격히 향상됨.
- 특히 175B 모델(GPT-3)은 Fine-Tuned 모델과 비슷한 성능을 보이는 경우도 있음.
태스크 설정 13B 모델 175B 모델 Fine-Tuned 모델
| Task | 설정 | 13B | 175B | Fine-Tuned Model |
| LAMBADA (언어 모델링) | Few-Shot | 81.3% | 86.4% | 68.0% (SOTA) |
| TriviaQA (질의응답) | Few-Shot | 57.5% | 71.2% | 68.0% |
| WebQuestions (질의응답) | Few-Shot | 33.5% | 41.5% | 45.5% |
| SQuAD v2 (독해) | Few-Shot | 58.1% | 69.8% | 73.0% |
| Winograd (논리적 추론) | Few-Shot | 70.2% | 77.7% | 84.6% |
- LAMBADA (문맥 예측): Few-Shot 학습을 통해 기존 Fine-Tuning 기반 SOTA(68%)보다 18% 높은 성능을 기록.
- TriviaQA (질의응답): Few-Shot 설정에서 Fine-Tuned 모델을 초월하는 성능을 보임.
- WebQuestions, SQuAD v2, Winograd에서는 여전히 Fine-Tuned 모델이 우세하지만, Few-Shot도 상당한 성능을 보임.
2) 번역 (Machine Translation)
- 영어 → 프랑스어 번역(En→Fr)에서는 Fine-Tuned NMT 모델보다 낮은 BLEU 점수를 기록.
- 영어 → 독일어 번역(En→De)에서는 Few-Shot 설정에서도 기존 Fine-Tuned 모델보다 성능이 낮음.
| Task | 설정 | 13B | 175B | Fine-Tuned Model |
| En→Fr (번역) | Few-Shot | 29.7 BLEU | 32.6 BLEU | 45.6 BLEU |
| En→De (번역) | Few-Shot | 26.2 BLEU | 29.7 BLEU | 41.2 BLEU |
- 번역에서는 기존 Fine-Tuning된 NMT 모델이 Few-Shot보다 훨씬 뛰어난 성능을 보임.
3) 논리적 추론 (NLI, ANLI)
- NLI (Natural Language Inference) 태스크에서는 Fine-Tuned 모델보다 성능이 낮음.
- ANLI R3(Adversarial Natural Language Inference)에서 Few-Shot 모델은 40.2%를 기록했지만, Fine-Tuned 모델은 60% 이상의 성능을 달성.
2. Few-Shot Learning vs Fine-Tuning
Few-Shot Learning과 Fine-Tuning의 성능을 직접 비교하면 다음과 같은 차이점이 있습니다.
2.1 Few-Shot Learning의 장점
✅ 1) 사전 훈련된 모델을 즉시 사용할 수 있음 (No Fine-Tuning Required)
- 새로운 태스크에 대해 추가적인 학습 없이도 즉시 사용 가능.
- 데이터가 부족한 환경에서 매우 유리.
✅ 2) 다양한 태스크에 유연하게 적용 가능
- 다양한 NLP 태스크(질의응답, 문서 생성, 문법 교정, 번역 등)에 Prompt Engineering만으로 적응 가능.
✅ 3) 대형 모델일수록 성능이 향상됨
- GPT-3 (175B)는 일부 태스크에서 Fine-Tuned 모델과 비슷한 성능을 보임.
- 특히, LAMBADA, TriviaQA와 같은 태스크에서는 Fine-Tuned 모델보다 성능이 높음.
2.2 Fine-Tuning의 장점
✅ 1) 특정 태스크에서 강력한 성능 보장
- NLI, 번역 등에서는 Few-Shot보다 Fine-Tuned 모델이 훨씬 우수.
- Few-Shot 학습은 논리적 추론이 필요한 태스크(NLI, ANLI)에서 부족한 성능을 보임.
✅ 2) 작은 모델에서도 고성능 가능
- Fine-Tuning은 작은 모델에서도 높은 성능을 발휘할 수 있음.
- 반면, Few-Shot Learning은 대형 모델(175B)에서만 제대로 작동.
✅ 3) 계산 비용이 낮음
- Fine-Tuning이 완료된 모델은 추론 시 계산 비용이 상대적으로 적음.
- Few-Shot Learning은 매번 많은 텍스트를 입력해야 하므로 실제 서비스에서는 비효율적일 수 있음.
2.3 결론: Few-Shot Learning vs Fine-Tuning, 어느 것이 더 나은 방법인가?
| 기준 | Few-Shot | Fine-Tuning |
| 학습 데이터 필요성 | 필요 없음 | 필요함 (대량의 레이블 데이터) |
| 유연성 | ✅ 매우 유연함 | ❌ 특정 태스크 전용 |
| 즉각적인 사용 가능성 | ✅ 가능 (프롬프팅만 필요) | ❌ Fine-Tuning 후 사용 가능 |
| 성능 (QA, 문맥 예측) | ✅ Fine-Tuning과 비슷하거나 뛰어남 | ✅ 매우 우수함 |
| 성능 (논리적 추론, 번역) | ❌ Fine-Tuned 모델보다 낮음 | ✅ 우수함 |
| 모델 크기 영향 | ✅ 크면 클수록 성능 증가 | ❌ 작은 모델에서도 가능 |
| 계산 비용 | ❌ 매우 높음 (프롬프트가 길어질수록 비효율적) | ✅ 추론 시 비용이 적음 |
✅ 결론:
- 즉시 적용 가능한 일반적인 NLP 모델을 만들고 싶다면 → Few-Shot Learning이 더 효과적.
- 특정한 태스크에서 최고의 성능을 원한다면 → Fine-Tuning이 필수적.
3. 결론 및 마무리
논문은 GPT-3가 Fine-Tuning 없이도 Few-Shot Learning만으로 매우 높은 성능을 달성할 수 있음을 입증하였습니다. 그러나 태스크별로 Fine-Tuning이 여전히 더 나은 경우가 많다는 점도 확인되었습니다.
3.1 연구의 주요 성과
✅ 1) Few-Shot Learning의 가능성을 입증
- GPT-3는 Few-Shot Learning만으로 일부 태스크에서 Fine-Tuned 모델과 동일한 수준의 성능을 기록.
✅ 2) 모델 크기의 중요성
- GPT-3 (175B)는 Few-Shot에서 뛰어난 성능을 보였지만, 작은 모델은 그렇지 않음.
✅ 3) Prompt Engineering의 중요성
- 모델을 효과적으로 활용하려면 적절한 프롬프트 설계(Prompt Engineering)가 필수적.
3.2 연구의 한계
❌ 1) 논리적 추론과 번역 성능이 부족
❌ 2) 매우 높은 계산 비용
❌ 3) 데이터 편향(Bias) 문제 발생 가능성
3.3 향후 연구 방향
🔹 Mixture of Experts(MoE) 적용 → 성능 유지하면서 계산 비용 절감
🔹 LLM + 강화학습 활용 → 보다 논리적인 결과 생성 가능
🔹 멀티모달 학습 → 이미지, 영상, 소리까지 함께 학습하는 방향
4. 최종 결론
Fine-Tuning은 특정 태스크에서 최고의 성능을 내는 확실한 방법이고, Few-Shot Learning은 데이터 없이 즉시 사용할 수 있는 강력한 방법입니다.
💡 향후 연구는 Few-Shot과 Fine-Tuning을 조합하여 더 강력한 AI를 만드는 방향으로 진행될 가능성이 큽니다.
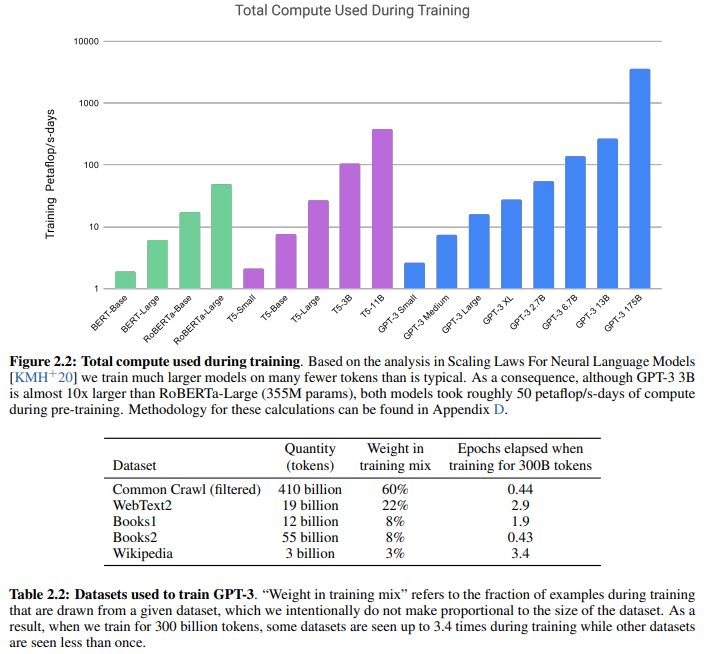
1. Figure 2.2: Total Compute Used During Training
그래프 개요
- 그래프는 모델 크기와 학습에 사용된 계산 비용(연산량) 간의 관계를 보여줍니다.
- x축: 다양한 모델 (BERT, RoBERTa, T5, GPT-3 등).
- y축 (로그 스케일): 학습에 사용된 총 계산량 (단위: Petaflop/s-days, PFLOP/s-days).
분석
- 계산량 증가:
- 모델 크기가 커질수록 학습에 사용된 계산량이 지수적으로 증가합니다.
- 예를 들어:
- GPT-3 Small(125M 파라미터)은 상대적으로 낮은 연산량을 필요로 하지만,
- GPT-3 175B 모델은 1000 PFLOP/s-days 이상을 소모합니다.
- 비교:
- RoBERTa-Large (355M 파라미터)는 GPT-3 3B 모델보다 파라미터가 10배 작지만, 학습에 소모된 계산량은 거의 동일함(~50 PFLOP/s-days).
- 이는 GPT-3의 학습이 더 효율적인 방식으로 이루어졌음을 암시.
- GPT-3 모델 군:
- GPT-3의 다양한 크기의 모델(GPT-3 Small ~ GPT-3 175B)은 점진적으로 계산량이 증가하며, 특히 대규모 모델일수록 학습 비용이 급증합니다.
결론
- 대규모 모델 학습은 매우 높은 계산 비용이 필요하며, 이는 연구 비용 증가로 이어짐.
- 그러나 GPT-3는 더 큰 모델 크기에서 효율적으로 학습이 이루어졌음을 나타냄.
2. Table 2.2: Datasets Used to Train GPT-3
표 개요
- GPT-3 모델 학습에 사용된 주요 데이터셋과 학습 비중, 반복 학습 횟수(epochs)를 설명합니다.
| Dataset | Quantity | Weight in training mix | Epochs elapsed when training for 300B tookens |
| Common Crawl | 410 billion | 60% | 0.44 |
| WebText2 | 19 billion | 22% | 2.9 |
| Books1 | 12 billion | 8% | 8.0 |
| Books2 | 55 billion | 8% | 0.43 |
| Wikipedia | 3 billion | 3% | 3.4 |
분석
- 데이터셋 구성
- Common Crawl:
- 가장 큰 데이터셋(410B 토큰).
- 학습 데이터에서 60% 비중을 차지하지만, 총 300B 토큰으로 학습할 때 0.44 epoch(즉, 데이터셋 전체를 한 번도 다 학습하지 않음)만 사용됨.
- WebText2:
- 19B 토큰으로 구성되었으며, 학습 데이터의 22%를 차지.
- 데이터셋 전체를 약 2.9번 반복 학습.
- Books1, Books2:
- 각 12B, 55B 토큰으로 구성되었으며, 학습 데이터에서 각각 8%를 차지.
- Books1은 전체를 약 8번 반복 학습, Books2는 0.43번 반복.
- Wikipedia:
- 가장 작은 데이터셋(3B 토큰).
- 학습 데이터에서 3%만 차지하지만, 전체 데이터를 약 3.4번 반복 학습.
- Common Crawl:
- 학습 반복 횟수(Epochs)의 차이
- 특정 데이터셋은 비중이 낮음에도 반복 학습이 많았음(Wikipedia: 3.4 epochs).
- 반면, Common Crawl은 가장 큰 데이터셋임에도 반복 학습이 적음(0.44 epochs).
- 이는 특정 데이터셋이 모델 학습에 미치는 영향을 조절하기 위한 의도적인 설계임.
결론
Figure 2.2의 결론:
- 대규모 모델 학습은 계산량의 급증을 초래하지만, 이를 통해 모델 성능이 향상될 가능성이 있음.
- GPT-3는 효율적으로 학습되었으며, 작은 모델과 대형 모델 간의 계산량 차이가 매우 큼.
Table 2.2의 결론:
- GPT-3는 다양한 데이터셋(총 300B 토큰)을 혼합하여 학습.
- Common Crawl이 학습에서 가장 큰 비중(60%)을 차지하며, 나머지 데이터셋은 반복 학습을 통해 모델의 균형 학습을 지원.
- 데이터셋 비중 조절과 반복 횟수 설계는 특정 데이터셋의 중요성을 강조하거나 과적합을 방지하는 데 사용됨.
PFLOP/s-days
PFLOP/s-days는 대규모 모델 학습에서 연산량을 나타내는 지표입니다. 이 개념은 컴퓨팅 성능과 학습 시간을 결합하여, 특정 모델이 학습하는 동안 소모한 총 연산량을 표현합니다. 이를 하나씩 풀어서 설명하겠습니다.
1. FLOP (Floating Point Operations)
- FLOP(Floating Point Operation):
- 컴퓨터가 부동소수점 연산(덧셈, 곱셈, 나눗셈 등)을 한 번 수행하는 작업.
- 예: a×b+c는 2 FLOP입니다.
- FLOPS (Floating Point Operations Per Second):
- 1초 동안 처리할 수 있는 FLOP의 수.
- 예: 1 TFLOPS = 10^{12} FLOP/s (1초에 1조 개의 부동소수점 연산 가능).
2. PFLOP/s
- PetaFLOP/s (PFLOP/s):
- 10^{15} FLOP/s를 나타냅니다.
- 초당 1천조 개의 부동소수점 연산을 수행할 수 있는 계산 능력을 의미.
- 대규모 GPU 클러스터 또는 슈퍼컴퓨터가 주로 사용하는 단위입니다.
3. PFLOP/s-days
- PFLOP/s-days는 PFLOP/s × 학습 시간(일)로 표현됩니다.
- 모델 학습 중 소비된 총 계산량을 측정하는 데 사용됩니다.
- 예를 들어, 시스템이 1 PFLOP/s의 연산 능력을 가진 상태에서 1일(24시간) 동안 학습하면:
소모된 연산량 = 1 PFLOP/s×1 day=86,400 PFLOP - 만약 시스템이 10 PFLOP/s의 성능으로 2일간 학습한다면:
소모된 연산량= 10 PFLOP/s× 2 days=1,728,000 PFLOP
GPT-3 학습 예시
- GPT-3(175B)의 학습에 사용된 총 연산량은 약 1,000 PFLOP/s-days로 추정됩니다.
- 이는 약 10억 조 번의 부동소수점 연산을 포함.
- 이를 구현하려면, 100 PFLOP/s 성능의 클러스터에서 10일간 학습하거나, 10 PFLOP/s에서 100일간 학습해야 합니다.
4. PFLOP/s-days의 중요성
PFLOP/s-days는 대규모 모델의 학습 효율성과 계산 비용을 평가하는 데 중요한 지표입니다.
비교 지표
- BERT-Base (110M 파라미터): 약 3 PFLOP/s-days 필요.
- RoBERTa-Large (355M 파라미터): 약 50 PFLOP/s-days 필요.
- GPT-3 (175B 파라미터): 약 1,000 PFLOP/s-days 필요.
이 수치는 모델 크기와 학습 데이터 크기에 따라 증가하며, 대규모 모델 학습이 얼마나 연산 집약적인지 나타냅니다.
5. 정리
- FLOP: 한 번의 부동소수점 연산.
- FLOPS: 1초당 수행 가능한 FLOP의 수.
- PFLOP/s: 초당 1천조 번의 연산.
- PFLOP/s-days: PFLOP/s에 학습 시간(일)을 곱한 값으로, 모델 학습 중 사용된 총 계산량.
GPT-3 같은 대규모 모델에서 PFLOP/s-days는 계산 자원의 크기와 효율성을 측정하는 핵심 단위입니다. 대규모 연산량은 고성능 하드웨어 클러스터와 막대한 에너지 비용을 요구하기 때문에, 연구자들이 계산 효율성을 높이는 방법을 고민해야 하는 이유이기도 합니다.
No Prompt와 Context 증가에 따른 성능 변화
1. No Prompt의 의미
- "No Prompt"란, 모델이 특정 작업에 대한 명시적인 자연어 설명이나 지시어(natural language task description) 없이 학습 데이터를 처리하는 상황을 의미합니다.
- Prompt를 제공하지 않는 경우: 모델이 단순히 입력 데이터를 보고 패턴을 학습하려고 시도하지만, 해당 데이터가 어떤 작업(Task)에 해당하는지 구체적으로 알지 못합니다.
- 예: "Remove random symbols from a word"라는 과제가 주어졌을 때, 이 작업을 설명하는 자연어 프롬프트 없이 모델이 입력 데이터를 보고 직접 패턴을 추론하려고 시도합니다.
2. "No Prompt"가 가능한 이유
- 대규모 언어 모델(LLM)의 특성:
- LLM은 사전 학습 단계에서 방대한 양의 데이터를 학습하여 일반적인 언어 패턴과 관계를 이해합니다.
- Prompt가 없어도 입력된 데이터를 기반으로 어떤 규칙을 추론하려는 In-Context Learning 능력을 가지고 있습니다.
- In-Context Learning:
- Context(예제)가 제공되면, 모델은 이를 통해 패턴을 추론하고 작업을 수행하려고 합니다.
- 예제들이 반복적으로 나타나면, 작업의 목적을 구체적으로 지시하지 않아도 모델이 데이터를 분석하여 점진적으로 규칙을 이해합니다.
3. Context 증가에 따른 No Prompt 성능 향상 이유
- Context란?:
- Context는 모델 입력으로 제공된 예제 데이터(입력-출력 쌍 등)를 의미합니다.
- 예: "@@Hello@@ → Hello" 와 같은 몇 개의 예제를 제공하면, 모델은 이 예제를 학습하여 새로운 입력에서도 유사한 패턴을 적용하려고 시도합니다.
- Context가 증가할수록 No Prompt 성능이 향상되는 이유:
- 더 많은 예제 제공 → 패턴 학습 가능성 증가:
- 초기에는 모델이 작업의 목적을 전혀 알 수 없지만, 예제가 누적되면서 점점 더 명확한 패턴을 학습합니다.
- 예를 들어, 여러 예제를 통해 "특정 기호를 제거하는 작업"이 반복적으로 나타나는 것을 파악할 수 있습니다.
- 작업의 목적을 간접적으로 추론 가능:
- Prompt 없이도, 다양한 예제가 제공되면 모델은 입력과 출력 간의 관계를 분석하여 규칙성을 추론할 수 있습니다.
- 이 과정은 자연어 지시어가 없이도 작업을 '암묵적으로' 이해하도록 모델을 학습시키는 결과를 낳습니다.
- 모델 크기와 학습 데이터의 일반화 능력:
- 모델이 클수록(No Prompt에서도 175B > 13B > 1.3B), 사전 학습에서 습득한 패턴을 더 효과적으로 사용합니다.
- 이는 대규모 언어 모델이 내부적으로 더 정교한 문맥 분석 및 패턴 일반화 능력을 가지고 있음을 보여줍니다.
- 더 많은 예제 제공 → 패턴 학습 가능성 증가:
4. 자연어 Prompt와 No Prompt 성능 비교
- 자연어 Prompt가 더 높은 성능을 보이는 이유:
- 자연어로 작업(Task)을 명시적으로 설명하면, 모델이 바로 작업의 목적을 이해할 수 있습니다.
- 이는 모델이 직접 추론할 필요를 줄이고, 명확한 지침을 따라 예측하도록 만듭니다.
- 예: "Remove symbols from a word"이라는 Prompt를 제공하면 모델이 즉각적으로 올바른 작업을 수행합니다.
- No Prompt의 성능 한계:
- 작업(Task)에 대한 명시적인 정보가 없으므로, 모델은 단순히 예제 데이터에서 패턴을 찾아야 합니다.
- 이 과정은 많은 Context(예제)가 필요하며, 여전히 Prompt 기반 학습보다 효율성이 떨어집니다.
5. Figure 1.2 요약
- Zero-Shot, One-Shot, Few-Shot Learning:
- Zero-Shot: 예제나 Prompt 없이 작업 수행 (정확도 낮음).
- One-Shot: 하나의 예제와 Prompt 제공.
- Few-Shot: 여러 예제와 Prompt 제공.
- No Prompt vs Natural Language Prompt:
- No Prompt:
- 명시적인 지시 없이 예제를 통해 작업을 암묵적으로 학습.
- Context 수가 증가할수록 정확도가 향상되지만, Prompt 사용보다 성능이 낮음.
- Natural Language Prompt:
- 작업(Task)을 명시적으로 설명해주기 때문에 적은 Context로도 높은 정확도를 달성.
- No Prompt:
- 모델 크기의 효과:
- 대규모 모델일수록(No Prompt 상황에서도) 더 높은 성능을 보임.
- 이는 대규모 모델이 학습 데이터에서 일반화 능력을 더 많이 배운 결과.
6. 결론
- No Prompt는 자연어로 명시적인 작업 지시를 제공하지 않는 상황을 의미하며, 모델은 제공된 Context(예제)를 통해 작업 규칙을 학습합니다.
- Context가 많아질수록 모델이 패턴을 학습하여 성능이 향상되며, 대규모 모델일수록 이러한 추론 능력이 강화됩니다.
- 그러나, Prompt를 사용하는 경우 작업 목표를 명확히 전달하므로 더 효율적이고, 성능도 높습니다.
- 이 결과는 Prompt Engineering이 Few-Shot 학습에서 중요한 이유를 잘 설명합니다.
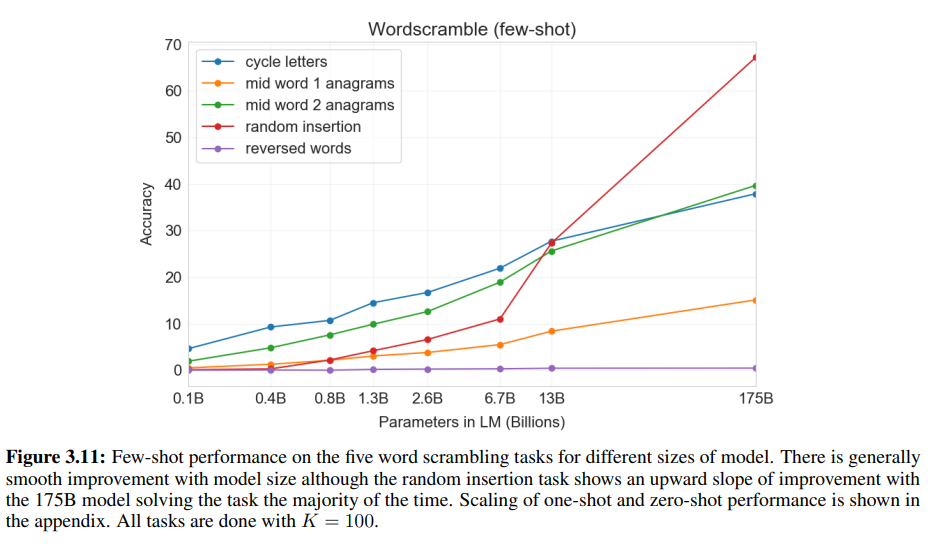
1. 실험 목표
- GPT-3의 Few-Shot 학습 능력을 평가하기 위해, 연구진은 5가지 문자 조작(Character Manipulation) 태스크를 설계했습니다.
- 각 태스크는 모델이 새로운 상징적 조작(symbolic manipulation)을 몇 개의 예제만 보고 학습할 수 있는지 평가하도록 설계되었습니다.
2. 태스크의 세부 설명
1) Cycle Letters in Word (CL)
- 설명: 단어의 글자를 순환시키고 원래 단어를 복원.
- 예시: lyinevitab → inevitably.
- 난이도: 중간. 모델이 순환 패턴을 이해하고 원래 단어를 복원해야 함.
2) Anagrams of All but First and Last Characters (A1)
- 설명: 단어의 첫 글자와 마지막 글자를 제외한 나머지를 무작위로 섞음.
- 예시: criroptuon → corruption.
- 난이도: A2보다 어려움. 고정된 문자 수가 더 적음. 쉬운 편.
3) Anagrams of All but First and Last 2 Characters (A2)
- 설명: 첫 2글자와 마지막 2글자를 제외한 나머지를 무작위로 섞음.
- 예시: opoepnnt → opponent.
- 난이도: 단어의 첫 2 글자와 마지막 2 글자가 고정되어 있어 복원이 더 간단함.
4) Random Insertion in Word (RI)
- 설명: 단어의 각 문자 사이에 무작위 구두점이나 공백을 삽입하고 원래 단어를 복원.
- 예시: s.u!c/c!e.s s i/o/n → succession.
- 난이도: 가장 높은 정확도를 기록했지만 복잡한 규칙 학습이 필요함.
5) Reversed Words (RW)
- 설명: 단어의 철자를 거꾸로 제공하고 원래 단어로 복원.
- 예시: stcejbo → objects.
- 난이도: 모델이 거의 해결하지 못함.
3. 실험 설정
- 데이터 생성:
- 10,000개의 예제를 생성.
- 각 예제는 4~15글자의 단어로 구성.
- 상위 10,000개 빈도 단어를 기준으로 사용.
- 평가 방법:
- 모델 크기(0.1B ~ 175B)와 태스크별 성능(Few-Shot, One-Shot, Zero-Shot)을 비교.
- Few-Shot: K=100개의 컨텍스트 예제를 제공.
- 정확도(Accuracy)를 기준으로 성능 평가.
4. Figure 3.11의 주요 내용
- 그래프 설명:
- x축: 모델 크기(파라미터 수, 0.1B ~ 175B).
- y축: 정확도(Accuracy %).
- 각 선은 5가지 태스크(Cycle Letters, A1, A2, RI, RW)의 Few-Shot 성능을 나타냄.
- 주요 결과:
- 모델 크기 증가 → 성능 향상:
- 모든 태스크에서 모델 크기가 증가할수록 성능이 점진적으로 향상.
- 특히 175B 모델에서 가장 높은 성능을 기록.
- 태스크별 성능 차이:
- Random Insertion(RI): 175B에서 66.9%로 가장 높은 성능.
- Cycle Letters(CL): 175B에서 38.6%로 중간 수준 성능.
- A1, A2 (Anagrams): A2(40.2%)이 A1(15.1%)보다 높은 성능.
- A2은 복원 단서가 많아 더 쉽게 해결.
- Reversed Words(RW): 모델 크기에 관계없이 성능이 거의 0%.
- 단순한 반전 작업이지만, 모델은 철저한 규칙성을 학습하지 못함.
- 모델 크기 증가 → 성능 향상:
5. 분석
1) Random Insertion (RI)의 높은 성능
- 이유: 삽입된 구두점과 공백을 제거하는 것은 상대적으로 간단한 규칙 학습으로 해결 가능.
- 175B 모델 성능: 대부분의 경우 정확한 단어 복원.
2) Cycle Letters (CL)
- 난이도: 순환 이동은 복잡한 조작이 요구되므로 성능이 제한적.
- 175B 성능: 38.6%. 중간 수준의 성능.
3) Anagrams (A1, A2)
- A1과 A2는 문자 조합이 고정되지 않아 복원이 어려움.
- A2은 첫 글자와 마지막 글자가 고정되어 있어 단서가 더 많아 성능이 높음.
- A1는 고정된 글자 수가 적어 성능이 낮음.
4) Reversed Words (RW)의 낮은 성능
- 모델이 단어를 철저히 뒤집어 복원하는 규칙성을 학습하지 못함.
- BPE(문자열 토큰화 방식)로 인해 모델이 문자 단위의 조작에 익숙하지 않음.
6. 결론
- Few-Shot 학습 가능성:
- GPT-3는 대규모 모델일수록 Few-Shot 학습 능력이 뛰어남.
- 특히 Random Insertion과 같은 명확한 규칙이 있는 태스크에서 높은 성능.
- Character-Level 작업의 한계:
- GPT-3는 단어의 BPE(하위 단위) 구조를 조작해야 하므로, 단순한 문자 레벨 작업에서 성능 저하.
- 특히 비결정적 복원 문제(CL, A1, A2)에서는 추가적인 추론 능력이 요구됨.
- 모델 크기의 중요성:
- 모델 크기가 커질수록 태스크 성능이 점진적으로 향상.
- 175B 모델만이 대부분의 태스크에서 학습 성능을 보임.
- Reversed Words의 실패:
- 단순한 규칙성을 가진 태스크도 모델이 학습하지 못하는 사례.
- 이는 문자 단위 조작(Character Manipulation)이 LLM에서 약점임을 나타냄.
- 실제 학습 여부:
- Few-Shot 학습에서 높은 성능을 보이는 반면, Zero-Shot에서는 거의 성능이 없었음.
- 이는 모델이 주어진 예제를 기반으로 태스크를 학습하고 수행함을 시사.
이 결과는 GPT-3가 단순히 사전 학습 데이터를 반복하는 것이 아니라, 새로운 문제를 Context를 통해 학습할 수 있는 능력을 보여줍니다.
분석: GPT-3의 Few-Shot 학습 능력 및 강점과 한계
1. Figure 1.2와 Few-Shot 학습의 주요 관찰
- Figure 1.2는 GPT-3가 특정 작업에서 Few-Shot 학습 능력을 보이는 과정을 보여줍니다.
- 실험 조건:
- 목표: 단어에서 불필요한 기호(extraneous symbols)를 제거하는 간단한 태스크.
- 변수:
- 자연어 작업 설명(Task Description): "불필요한 기호를 제거하라"와 같은 명시적 지시.
- 컨텍스트 내 예제 수 (K): 모델에 제공된 예제(입력-출력 쌍)의 수.
결과
- 자연어 작업 설명의 추가 효과:
- 작업을 명시적으로 설명하면, 모델의 성능이 크게 향상됩니다.
- 자연어 설명은 모델이 태스크의 목적을 명확히 이해하도록 돕습니다.
- 컨텍스트 내 예제 수(K)의 증가 효과:
- 예제 수가 많아질수록, 모델의 성능이 점진적으로 향상.
- 이는 GPT-3가 컨텍스트에 포함된 예제를 통해 작업 규칙을 학습하고 추론할 수 있음을 보여줍니다.
- 모델 크기의 영향:
- 모델 크기가 클수록 Few-Shot 학습 능력이 대폭 향상.
- GPT-3(175B)는 작은 모델(1.3B)에 비해 동일한 작업에서 훨씬 높은 성능을 기록.
특징적 학습 방식
- 학습 곡선의 독특성:
- Figure 1.2는 "학습 곡선"이 모델이 Fine-Tuning 없이, 단지 더 많은 예제와 명시적 설명으로 태스크를 이해할 수 있음을 보여줍니다.
- Gradient Update 없이 수행: 학습 중 모델의 파라미터 업데이트 없이, 컨텍스트 예제만을 활용해 작업을 수행.
2. NLP 태스크에서의 성능 분석
GPT-3는 Zero-Shot, One-Shot, Few-Shot 설정에서 다양한 NLP 태스크를 평가받았습니다.
1) CoQA (질문 응답, QA)
- CoQA는 대화 기반 질문 응답 데이터셋으로, GPT-3는 Fine-Tuning 없이 높은 성능을 기록:
- Zero-Shot: 81.5 F1
- One-Shot: 84.0 F1
- Few-Shot: 85.0 F1 (Fine-Tuned 모델과 비슷한 성능)
2) TriviaQA (질문 응답, QA)
- TriviaQA는 사실 기반 질문 응답 데이터셋으로, GPT-3는 Few-Shot에서 SOTA를 기록:
- Zero-Shot: 64.3%
- One-Shot: 68.0%
- Few-Shot: 71.2% (Fine-Tuned 모델과 동일 수준)
3) 기타 태스크
- 문자 조작 및 산술 작업:
- 단어 unscrambling: 단어의 순서를 재배열하는 작업에서 GPT-3는 Few-Shot으로 높은 성능을 보임.
- 산술 문제: 산술 연산 및 수식 계산에서도 One-Shot 및 Few-Shot 설정에서 우수한 결과.
- 새로운 단어 정의 및 문맥 사용:
- 새로운 단어가 한 번 정의된 후 이를 문장에서 사용하는 능력 역시 Few-Shot에서 탁월.
3. GPT-3의 강점
- Zero-Shot, One-Shot 성능:
- Fine-Tuning 없이도 다양한 NLP 태스크에서 강력한 성능을 발휘.
- 일부 태스크에서는 Few-Shot 학습으로 Fine-Tuned 모델을 능가.
- 다양한 태스크에서의 적응력:
- 문자 조작, 산술 문제, 새로운 단어 학습 등 광범위한 작업 수행 가능.
- Few-Shot 설정에서 문맥 정보와 자연어 설명을 효과적으로 활용.
- Human-Like Text Generation:
- Few-Shot 설정에서 사람과 구별하기 어려운 수준의 텍스트 생성 가능.
- 예: Synthetic News Article Generation.
4. GPT-3의 한계
1) 논리적 추론 및 복잡한 태스크
- 자연어 추론 (Natural Language Inference):
- ANLI 데이터셋에서 성능이 낮음. 이는 GPT-3가 복잡한 논리적 추론을 잘 수행하지 못함을 나타냄.
- Fine-Tuned 모델에 비해 성능 격차가 큼.
- 읽기 이해 (Reading Comprehension):
- RACE, QuAC 데이터셋에서는 Few-Shot 성능이 낮음.
- 복잡한 맥락 이해와 추론 능력이 부족.
2) Fine-Tuning 모델과의 비교
- Few-Shot 학습은 빠르고 유연하지만, 특정 작업에서는 Fine-Tuning 모델보다 성능이 떨어짐.
- 이는 특히, 논리적 구조가 복잡하거나 고도의 추론을 요구하는 태스크에서 두드러짐.
3) 데이터 편향 및 한계
- 학습 데이터의 편향으로 인해 GPT-3는 일부 작업에서 부정확하거나 편향된 결과를 생성.
- 문자 조작(Character-Level Tasks):
- BPE 토큰화 방식으로 인해 문자 수준 작업에서 약점이 존재.
5. 결론
- Few-Shot Learning의 성공 가능성:
- GPT-3는 Fine-Tuning 없이도 다양한 NLP 태스크에서 높은 성능을 보이며, 특히 Few-Shot 설정에서 SOTA를 기록하는 경우도 존재.
- 이는 대규모 언어 모델이 단순히 데이터를 복사하는 것이 아니라 문맥에서 학습하고 추론할 수 있는 능력을 갖췄음을 보여줍니다.
- Few-Shot의 한계와 향후 연구 방향:
- 논리적 추론과 같은 고차원 작업에서의 성능 한계를 극복해야 함.
- Prompt Engineering과 훈련 데이터의 다양화가 모델 성능 개선에 중요한 역할을 할 것으로 보임.
GPT-3는 Fine-Tuning 없는 학습이라는 새로운 접근법의 가능성을 보여줬지만, 일부 고도화된 작업에서는 여전히 Fine-Tuned 모델의 성능이 필요합니다. 이러한 결과는 언어 모델 연구가 더 많은 컨텍스트 학습과 논리적 추론에 초점을 맞춰야 함을 시사합니다.
맞습니다. Instruction(지시어)의 중요성은 이 논문에서 매우 강조된 부분 중 하나이며, GPT-3의 Few-Shot Learning 성능과 밀접하게 연결되어 있습니다. 이 논문이 보여준 여러 결과는 자연어 지시어(Natural Language Instructions)가 언어 모델의 학습과 추론 능력을 크게 향상시킨다는 점을 분명히 드러냅니다.
1. Instruction의 역할
- Task Understanding:
- Instruction(지시어)는 모델이 태스크의 목적과 규칙을 명확히 이해하도록 돕습니다.
- 단순히 데이터(Context)를 제공하는 것만으로는 부족한 경우가 많으며, 명시적인 지시어를 통해 모델이 문제 해결 방식을 정확히 파악할 수 있습니다.
- 예를 들어, "불필요한 기호를 제거하라"는 설명을 추가했을 때 성능이 눈에 띄게 향상된 것을 볼 수 있었습니다.
- Few-Shot Learning에서의 강화 효과:
- Instruction이 없으면 모델은 컨텍스트에 포함된 예제만으로 작업의 규칙을 추론해야 하므로 성능이 제한될 수 있습니다.
- 하지만 지시어가 추가되면, 컨텍스트와 결합하여 학습 효과를 증폭시킵니다.
- 이는 특히 Figure 1.2에서 명확히 드러났습니다:
- No Prompt의 경우, 모델이 패턴을 추론하는 데 더 많은 예제가 필요했지만,
- Natural Language Prompt(Instruction)를 추가하면 적은 예제만으로도 높은 정확도를 달성했습니다.
2. Instruction의 중요성을 보여주는 결과
1) 자연어 지시어의 추가로 성능 향상
- Figure 1.2의 실험 결과:
- 자연어 지시어를 포함한 경우, 작업의 맥락을 더 잘 이해하고 성능이 개선됨.
- 이는 모델이 단순히 데이터를 학습하는 것이 아니라, 지시어를 이해하고 적용할 수 있는 능력을 가지고 있음을 시사합니다.
2) CoQA와 TriviaQA에서의 성능
- GPT-3는 질문 응답 태스크(CoQA, TriviaQA)에서 Zero-Shot, One-Shot, Few-Shot 모두에서 높은 성능을 기록했습니다.
- 자연어 지시어를 통해 태스크의 목적을 명확히 전달함으로써, Few-Shot에서 Fine-Tuned 모델과 동등하거나 더 나은 성능을 달성.
3) Synthetic News Generation
- 모델이 자연어 지시어를 기반으로 사람과 구별하기 어려운 수준의 뉴스 기사 생성도 가능.
- 이는 지시어가 단순한 태스크 설명뿐만 아니라, 창의적 작업을 유도하는 데도 중요한 역할을 한다는 점을 보여줍니다.
3. Instruction이 중요한 이유
1) Few-Shot Learning의 기반
- Few-Shot 학습은 프롬프트를 활용한 작업 수행을 전제로 합니다.
- 프롬프트에는 작업의 지시어와 예제가 포함되며, 모델은 이를 통해 작업의 맥락을 학습합니다.
- Instruction이 포함되지 않으면, 모델은 컨텍스트만으로 태스크를 추론해야 하며 이는 비효율적입니다.
2) 추론 능력 강화
- 자연어 지시어는 모델이 태스크의 목표를 명확히 파악하고, 필요한 추론 과정을 효율적으로 수행할 수 있도록 돕습니다.
- 이는 특히 논문에서 다룬 Character Manipulation과 같은 복잡한 태스크에서 중요한 역할을 합니다.
3) 작업 일반화와 적응
- GPT-3는 Instruction을 통해 작업을 일반화하고 새로운 태스크에 적응하는 능력을 보였습니다.
- 이는 Fine-Tuning 없이도 다양한 태스크를 처리할 수 있는 모델의 유연성을 보여줍니다.
4. Instruction의 한계
- Ambiguous Instructions:
- 지시어가 불분명하거나 모호하면, 모델의 성능이 크게 저하될 수 있습니다.
- 예를 들어, "기호를 제거하라"는 명령이 구체적이지 않다면, 모델이 정확히 어떤 기호를 제거해야 할지 혼란스러워할 수 있습니다.
- 추론이 필요한 태스크:
- 자연어 지시어가 포함되더라도, 논리적 추론이 필수적인 태스크(예: ANLI, RACE)에서는 여전히 성능 한계가 존재합니다.
5. 향후 연구 방향
1) Prompt Engineering의 중요성
- 자연어 지시어 설계(Prompt Engineering)는 모델의 학습 성능을 최적화하는 중요한 연구 주제입니다.
- 효과적인 지시어를 설계하면, 적은 예제만으로도 모델의 학습 효율을 크게 향상시킬 수 있습니다.
2) Instruction-Finetuning
- Instruction을 중심으로 모델을 미세 조정(Finetuning)하여, 다양한 태스크에서의 성능을 더 강화할 수 있습니다.
- OpenAI의 후속 연구(GPT-4)에서도 Instruction 기반 Fine-Tuning이 주요 성능 개선 전략으로 활용되었습니다.
6. 결론
논문은 Instruction의 중요성을 명확히 보여줍니다.
- 자연어 지시어는 GPT-3와 같은 대규모 언어 모델이 새로운 태스크를 이해하고 학습하는 데 핵심적인 역할을 합니다.
- Few-Shot 학습의 성공은 명확하고 잘 설계된 Instruction에 크게 의존합니다.
- 따라서, 향후 연구에서 효과적인 Instruction 설계(Prompt Engineering)와 이를 통한 모델 성능 개선이 중요한 주제로 부각될 것입니다.
GPT-3의 성공은 언어 모델 연구에서 Instruction을 통한 학습 접근법이 얼마나 강력한지를 입증한 사례입니다.
논문의 접근 방식 정리
논문은 GPT-3를 설계, 학습, 평가하는 과정에서 사용된 모델, 데이터, 학습 방법론, 평가 전략을 포괄적으로 다룹니다. 이를 체계적으로 정리하겠습니다.
1. Pre-Training 접근 방식
GPT-3의 사전 학습(Pre-Training) 접근 방식은 GPT-2의 연구(RWC+19)에서 사용된 기법을 기반으로 하며, 몇 가지 확장 및 개선이 이루어졌습니다.
1.1 핵심 요소
- 모델 크기:
- 모델의 파라미터 수를 125M에서 175B로 확장하며, 성능과 학습 데이터 처리량의 관계를 실험적으로 분석.
- 학습 데이터 크기와 다양성:
- 대규모 데이터셋(Common Crawl 등)을 기반으로, 고품질 데이터를 선별하여 학습에 활용.
- 학습 기간:
- 더 많은 데이터와 더 긴 학습 기간을 통해 모델의 성능을 최대화.
1.2 목표
- In-Context Learning을 심층적으로 탐구:
- 모델이 컨텍스트 내의 예제를 기반으로 태스크를 학습하는 능력을 체계적으로 연구.
- Fine-Tuning 없는 Task-Agnostic 성능:
- GPT-3는 Fine-Tuning 없이도 광범위한 태스크에서 강력한 성능을 보여줌.
- Fine-Tuning을 하지 않은 이유는 일반화 성능 평가를 목표로 했기 때문.
2. 학습 및 평가 방식
GPT-3의 성능은 Fine-Tuning, Few-Shot, One-Shot, Zero-Shot 설정에서 평가되었습니다. 이들은 태스크-특화 데이터 의존도에 따라 구분됩니다.
2.1 Fine-Tuning (FT)
- 설명:
- 사전 학습된 모델의 가중치를 업데이트하여 특정 태스크에 맞게 조정.
- 장점:
- 특정 데이터셋에서 높은 성능을 보임.
- 단점:
- 새로운 태스크마다 대규모 데이터셋이 필요.
- 편향된 학습 데이터로 인해 일반화 성능이 낮아질 수 있음.
- 논문의 적용:
- GPT-3는 Fine-Tuning 없이 사용되었으나, Fine-Tuning은 향후 연구 방향으로 언급.
2.2 Few-Shot Learning (FS)
- 설명:
- 모델에 태스크의 예제 K개를 제공하며, 가중치 업데이트 없이 태스크를 수행.
- 예제는 컨텍스트 창(Context Window, 최대 2048 토큰)에 포함.
- 장점:
- 태스크-특화 데이터 의존도가 낮아짐.
- 모델이 예제를 통해 새로운 태스크를 학습.
- 단점:
- Fine-Tuned 모델보다는 성능이 낮음.
- 결과:
- 많은 태스크에서 Fine-Tuned 모델에 근접한 성능.
- 특히, TriviaQA, CoQA와 같은 QA 태스크에서 강력한 결과를 기록.
2.3 One-Shot Learning (1S)
- 설명:
- 한 개의 예제와 자연어 작업 설명만 제공.
- 장점:
- 인간의 태스크 수행 방식과 유사.
- 태스크 의도를 명확히 전달 가능.
- 결과:
- Few-Shot보다는 낮은 성능이지만, Zero-Shot보다는 우수한 결과.
2.4 Zero-Shot Learning (0S)
- 설명:
- 예제 없이 자연어 작업 설명만 제공.
- 장점:
- 태스크-특화 데이터 없이도 높은 유연성과 일반화 가능성.
- 단점:
- 태스크를 이해하지 못하거나 설명이 불명확하면 성능 저하.
- 결과:
- 일부 태스크에서 인간과 유사한 결과를 보였지만, 논리적 추론이 필요한 태스크에서는 성능이 낮음.
3. 모델 아키텍처
3.1 기본 구조
- GPT-3는 GPT-2 아키텍처를 기반으로 설계:
- Transformer 기반 Autoregressive 모델.
- Alternating Dense and Locally Banded Sparse Attention:
- Sparse Transformer와 유사한 희소 패턴으로 주목(attention)을 계산.
- Feedforward Layer:
- 모델의 각 피드포워드 계층 크기는 bottleneck 크기의 4배.
3.2 파라미터 세부 정보
- 모델은 8가지 크기(125M ~ 175B 파라미터)로 설계.
- 모든 모델은 nctx = 2048 토큰의 컨텍스트 윈도우를 가짐.
- GPU 클러스터를 통해 모델 병렬화와 효율적 학습 구현.
4. 학습 데이터
4.1 데이터셋 구성
- Common Crawl, WebText, Wikipedia, Books1/Books2 등 다양한 고품질 데이터셋 사용.
- 데이터셋 필터링 및 중복 제거:
- Common Crawl 데이터를 고품질 코퍼스와 유사한 문서만 선별.
- 문서 수준 중복 제거 및 데이터셋 간 중복 제거 수행.
4.2 데이터 처리
- 학습 데이터는 총 570GB, 약 3000억 개의 토큰으로 구성.
- 고품질 데이터셋은 더 자주 샘플링하여 학습 데이터의 다양성과 품질 향상.
4.3 데이터 오염 문제
- 테스트 데이터셋과 학습 데이터 간 중복을 최소화하려 했으나, 일부 중복이 발생.
- 이로 인한 성능 영향은 제한적이라고 평가.
5. 학습 과정
5.1 하이퍼파라미터
- 배치 크기와 학습률은 모델 크기에 따라 조정.
- V100 GPU 클러스터를 사용하여 모델 병렬화 및 학습 효율 극대화.
5.2 대규모 학습 최적화
- 모델 병렬화를 통해 GPU 메모리 부족 문제 해결.
- 고대역폭 클러스터를 활용하여 데이터 전송을 최소화.
6. 평가 방법
6.1 Few-Shot, One-Shot, Zero-Shot 평가
- Few-Shot: K개의 예제를 랜덤하게 추출하여 모델에 입력.
- One-Shot, Zero-Shot: 태스크에 맞는 자연어 지시어 추가.
6.2 태스크별 평가 방식
- QA, 번역, 자유형 생성 등 다양한 태스크에서 성능 측정.
- Multiple Choice:
- 정답의 확률을 계산해 가장 높은 선택지를 선택.
- Free-Form Completion:
- BLEU, F1, Exact Match 점수를 사용하여 결과 평가.
7. 결론
- GPT-3는 Fine-Tuning 없이도 Zero-Shot, One-Shot, Few-Shot 설정에서 강력한 성능을 보임.
- Few-Shot 학습은 특히 Fine-Tuned 모델에 근접하거나 이를 초월하는 성과를 보이며, 태스크-특화 데이터에 대한 의존도를 낮춤.
- 논문의 접근 방식은 모델 크기, 데이터 품질, In-Context Learning의 중요성을 강조하며, 미래의 연구에서 Prompt Engineering과 Fine-Tuning 결합 가능성을 제안합니다.
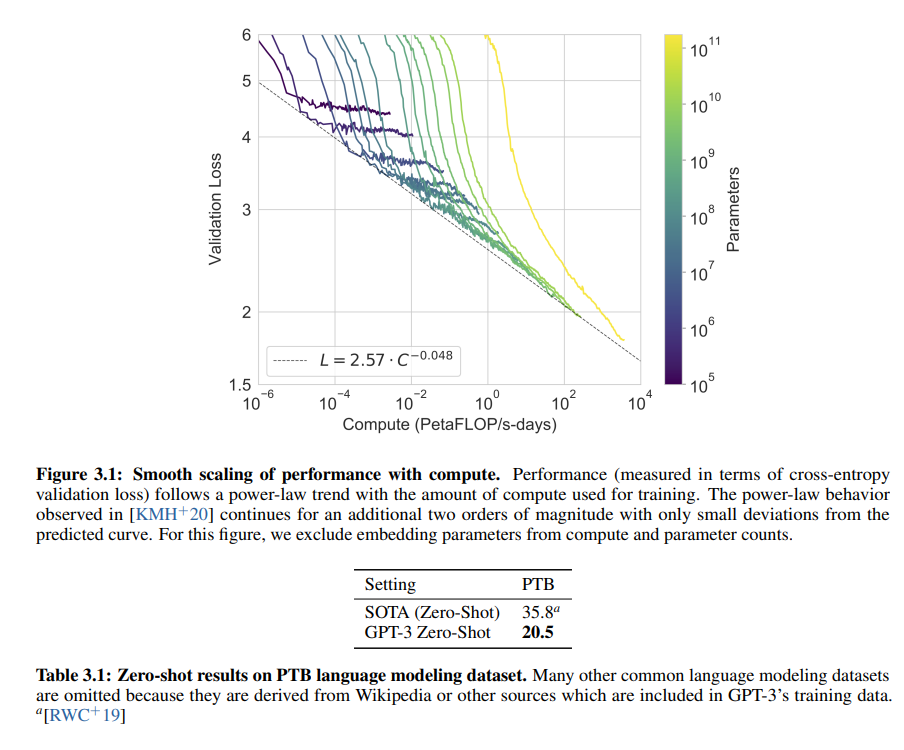
1. Figure 3.1: Compute와 Validation Loss의 관계
내용 요약
- x축: 학습에 사용된 연산량 (Petaflop/s-days).
- y축: Validation Loss (교차 엔트로피).
- 색상: 모델 크기(파라미터 수).
주요 관찰
- Validation Loss의 Power-Law 감소:
- 연산량이 증가할수록 Validation Loss가 전력 법칙(Power Law)에 따라 꾸준히 감소.
- Validation Loss는 다음 관계를 따름:

2. Table 3.1: PTB 데이터셋에서 Zero-Shot 성능
내용 요약
- PTB(Penn Treebank)는 전통적인 언어 모델링 벤치마크.
- SOTA(Zero-Shot): 35.8 (Cross-Entropy 기준).
- GPT-3 Zero-Shot: 20.5 (Cross-Entropy 기준).
주요 관찰
- GPT-3의 Zero-Shot 성능:
- GPT-3는 Zero-Shot 설정에서 PTB 데이터셋의 SOTA 성능(35.8)을 뛰어넘음.
- Fine-Tuning 없이도 GPT-3의 사전 학습된 일반화 능력이 뛰어남을 보여줌.
- 결론:
- GPT-3는 PTB 같은 언어 모델링 태스크에서도 Zero-Shot으로 강력한 성능을 발휘.
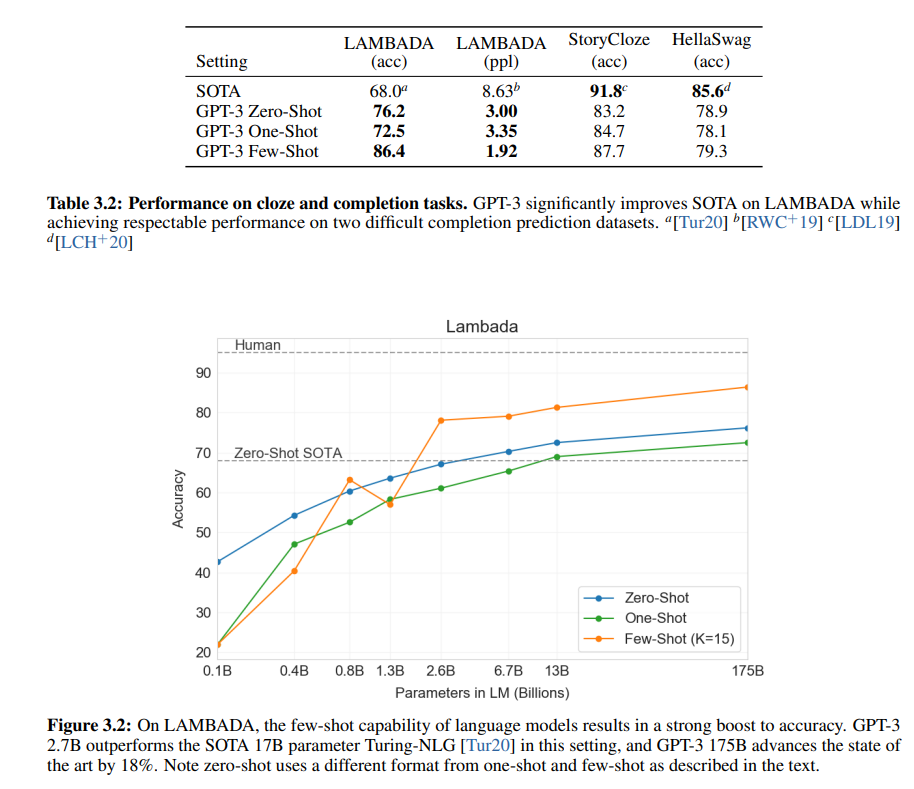
3. Table 3.2: LAMBADA, StoryCloze, HellaSwag 성능
내용 요약
- LAMBADA: 문맥을 기반으로 단어를 예측하는 태스크.
- StoryCloze: 이야기를 완성하는 태스크.
- HellaSwag: 논리적으로 다음 문장을 예측하는 태스크.
| Setting | LAMBADA (acc) | LAMBADA (ppl) | StoryCloze (acc) | HellaSwag (acc) |
| SOTA | 68.0 | 8.63 | 91.8 | 85.6 |
| GPT-3 Zero-Shot | 76.2 | 3.00 | 83.2 | 78.9 |
| GPT-3 One-Shot | 72.5 | 3.35 | 84.7 | 78.1 |
| GPT-3 Few-Shot | 86.4 | 1.92 | 87.7 | 79.3 |
주요 관찰
- LAMBADA 성능:
- Zero-Shot에서 GPT-3는 기존 SOTA(68.0)를 초과(76.2).
- Few-Shot에서는 86.4로 가장 높은 성능을 기록하며, 사람 수준에 가까운 결과.
- StoryCloze와 HellaSwag:
- Zero-Shot과 One-Shot에서는 기존 SOTA보다 낮은 성능.
- Few-Shot에서 약간의 성능 개선을 보였지만 여전히 SOTA에 미치지 못함.
- Perplexity (ppl):
- GPT-3는 LAMBADA에서 매우 낮은 perplexity(1.92)를 기록.
- 이는 모델이 문맥 기반 단어 예측에서 강력한 확률 예측 능력을 가짐을 의미.
4. Figure 3.2: LAMBADA에서 Zero-Shot, One-Shot, Few-Shot 성능
내용 요약
- x축: 모델 크기(파라미터 수).
- y축: LAMBADA 정확도(Accuracy).
- 색상: Zero-Shot(파란색), One-Shot(녹색), Few-Shot(주황색).
주요 관찰
- 모델 크기와 성능 관계:
- 모델 크기가 커질수록 정확도가 꾸준히 증가.
- 175B 모델에서 Few-Shot 정확도는 86.4로, 인간 성능에 근접.
- 학습 설정별 성능 차이:
- Zero-Shot: 비교적 낮은 정확도에서 시작.
- Few-Shot: K=15일 때 성능이 크게 향상.
- Human vs. GPT-3:
- Few-Shot(86.4)은 Zero-Shot SOTA(68.0)보다 18% 높음.
- 사람 수준의 정확도(90% 이상)에 근접.
5. 종합 결론
1) Compute와 모델 크기의 중요성 (Figure 3.1)
- 연산량과 모델 크기는 Validation Loss와 성능 향상에 중요한 영향을 미침.
- 대규모 모델은 동일한 연산량으로 더 높은 효율성을 발휘.
2) Zero-Shot의 잠재력 (Table 3.1)
- GPT-3는 Fine-Tuning 없이도 SOTA 성능을 초과하거나 근접한 결과를 달성.
3) Few-Shot의 강력한 성능 (Table 3.2, Figure 3.2)
- Few-Shot 학습은 특히 LAMBADA와 같은 문맥 기반 태스크에서 강력한 성능을 보임.
- 모델 크기와 학습 설정에 따라 성능이 급격히 향상되며, GPT-3 175B는 사람 수준에 가까운 결과를 보여줌.
이러한 결과는 대규모 언어 모델의 성능이 연산량, 데이터 품질, 학습 설정에 따라 크게 달라질 수 있음을 강조하며, Few-Shot 학습이 태스크-특화 데이터에 의존하지 않고도 강력한 결과를 제공할 수 있음을 입증합니다.
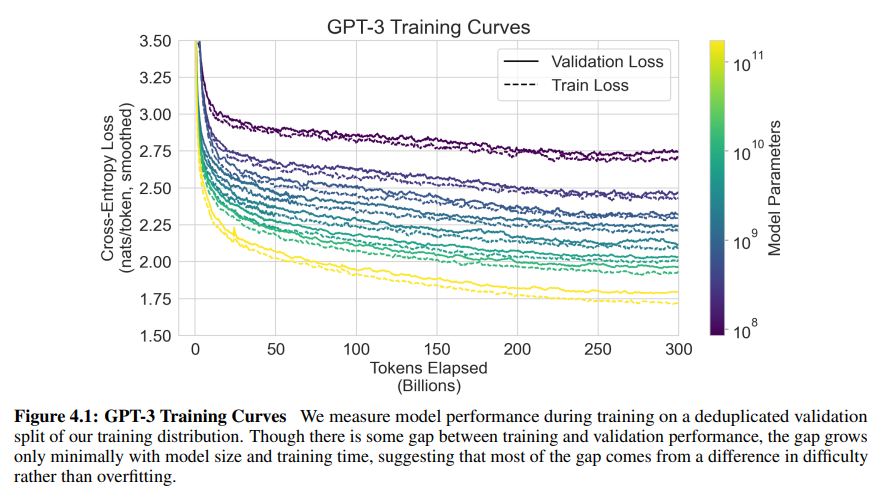
Figure 4.1: GPT-3 Training Curves
Figure 개요
- 목적: GPT-3의 학습 및 검증 손실(Train Loss, Validation Loss)을 시각화하여 모델 학습의 패턴과 안정성을 분석.
- x축: 학습에 사용된 토큰 수 (Tokens Elapsed, 단위: 억 개).
- y축: Cross-Entropy Loss (nats/token).
- 색상: 모델 크기 (파라미터 수, 10^8에서 10^{11}까지).
- 선 스타일:
- 실선: Validation Loss (검증 손실).
- 점선: Train Loss (훈련 손실).
주요 관찰
1. Train Loss와 Validation Loss 간의 차이
- Validation Loss는 Train Loss보다 항상 높게 나타남.
- 이는 훈련 데이터와 검증 데이터의 난이도 차이 때문으로 해석.
- 오버피팅(Overfitting)의 흔적은 크지 않음.
- 학습 데이터에 비해 검증 데이터는 모델이 더 어려워하는 경향이 있음.
2. 모델 크기와 Loss 감소
- 모델 크기(파라미터 수)가 증가할수록 Train Loss와 Validation Loss 모두 낮아짐.
- 더 큰 모델(GPT-3 175B)은 더 복잡한 패턴과 구조를 학습할 수 있음.
- 작은 모델은 동일한 학습 데이터에서 더 높은 Loss를 기록.
3. Loss 감소 속도
- 학습 초기(0~50B 토큰) 동안 Loss가 급격히 감소.
- 이는 초기 학습 단계에서 모델이 빠르게 패턴을 학습한다는 것을 의미.
- 학습 후반부(200B~300B 토큰)에서는 Loss 감소 속도가 완만해짐.
- 모델이 데이터의 대부분을 학습했음을 나타냄.
4. Train Loss와 Validation Loss의 안정성
- 학습 후반부에서도 Loss 값은 안정적으로 유지됨.
- 이는 대규모 모델 학습이 잘 정규화되었음을 보여줌.
- 과적합의 징후가 거의 없음.
Figure의 의미와 결론
1. 학습 데이터 품질과 난이도
- Train Loss와 Validation Loss 간의 차이는 학습 데이터와 검증 데이터의 난이도 차이로 해석됨.
- 검증 데이터는 모델이 더 어려워하는 구성을 포함.
2. 모델 크기의 중요성
- 더 큰 모델(GPT-3 175B)은 동일한 학습 데이터에서 더 낮은 Loss를 기록.
- 이는 대규모 모델이 더 많은 학습 데이터와 복잡한 구조를 학습할 수 있음을 시사.
3. 학습의 효율성과 안정성
- 학습 초기에는 급격한 성능 향상이 이루어지며, 후반부에는 Loss 값이 안정화.
- 이는 모델이 학습을 효율적으로 진행했으며, 오버피팅 없이 안정적으로 학습했음을 보여줌.
GPT-3 학습 방식의 강점
- 대규모 데이터와 모델 크기의 조합:
- 더 큰 모델은 더 복잡한 데이터를 효과적으로 학습.
- 모델 크기가 클수록 Train Loss와 Validation Loss 모두 낮아짐.
- 효율적인 학습 곡선:
- 초기 학습에서 빠르게 성능이 향상되며, 후반부에 안정적으로 수렴.
- 이는 학습률 및 하이퍼파라미터 조정이 잘 이루어졌음을 보여줌.
- 일관된 성능:
- 과적합 없이 학습과 검증 성능의 차이를 안정적으로 유지.
결론
Figure 4.1은 GPT-3 학습 과정의 효율성과 안정성을 강조합니다.
- Train Loss와 Validation Loss 간의 차이가 적고 안정적이며, 이는 학습 과정에서 과적합 문제가 거의 없음을 시사합니다.
- 모델 크기와 학습 데이터의 크기가 성능 향상에 직접적으로 기여하며, 더 큰 모델이 더 효과적으로 학습함을 보여줍니다.
이 결과는 대규모 언어 모델의 학습 전략이 성공적으로 설계되었음을 입증합니다.