https://arxiv.org/abs/2210.03493
Automatic Chain of Thought Prompting in Large Language Models
Large language models (LLMs) can perform complex reasoning by generating intermediate reasoning steps. Providing these steps for prompting demonstrations is called chain-of-thought (CoT) prompting. CoT prompting has two major paradigms. One leverages a sim
arxiv.org
CoT의 성능은 입증되었지만 CoT의 예제 입력 방식은 상당히 귀찮은 일이다.
이를 해결하기 위해 예시를 자동적으로 생산하고, 클러스터링을 통해 다양한 예시를 전달하여 일반화 성능을 높이는 Auto-CoT 방식을 제안한다.
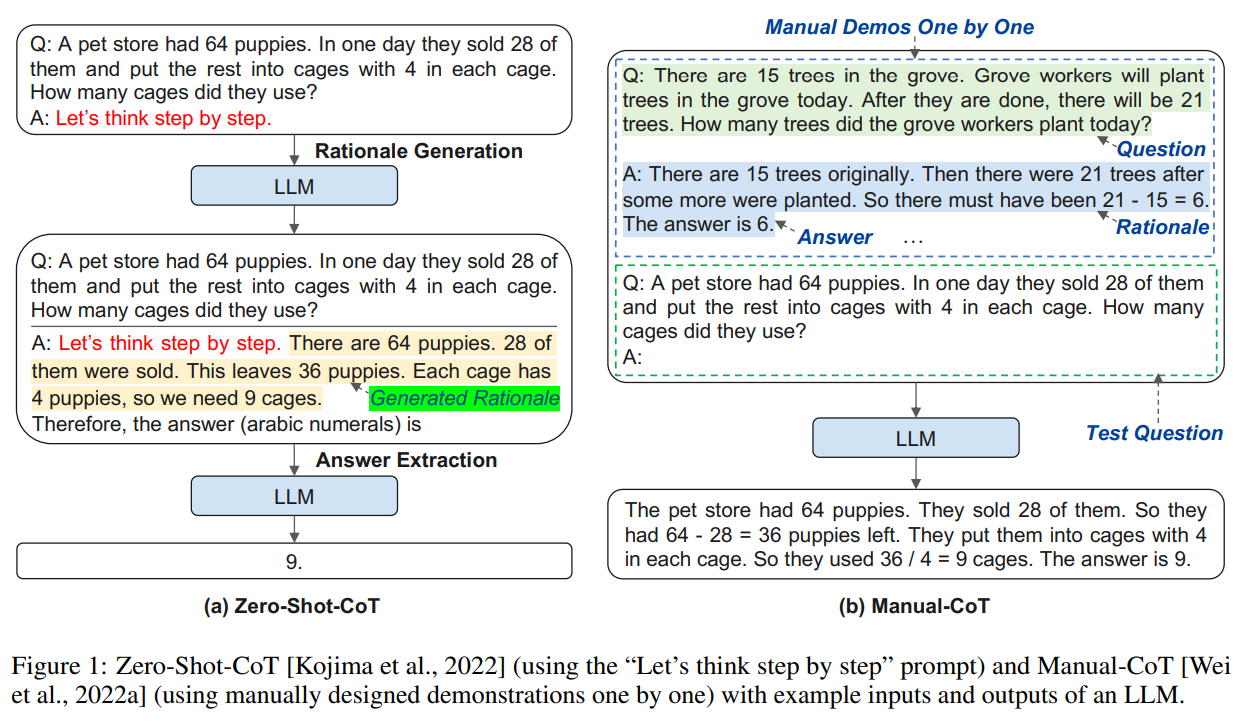
그나마 단순한 방법이 Let's think step by step을 붙인 Zero-shot-CoT이지만 성능에 한계가 존재한다.
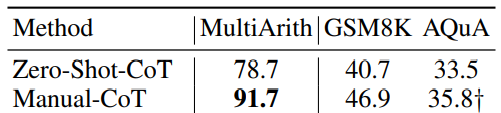
이러한 사유로 Auto-CoT를 진행한다.
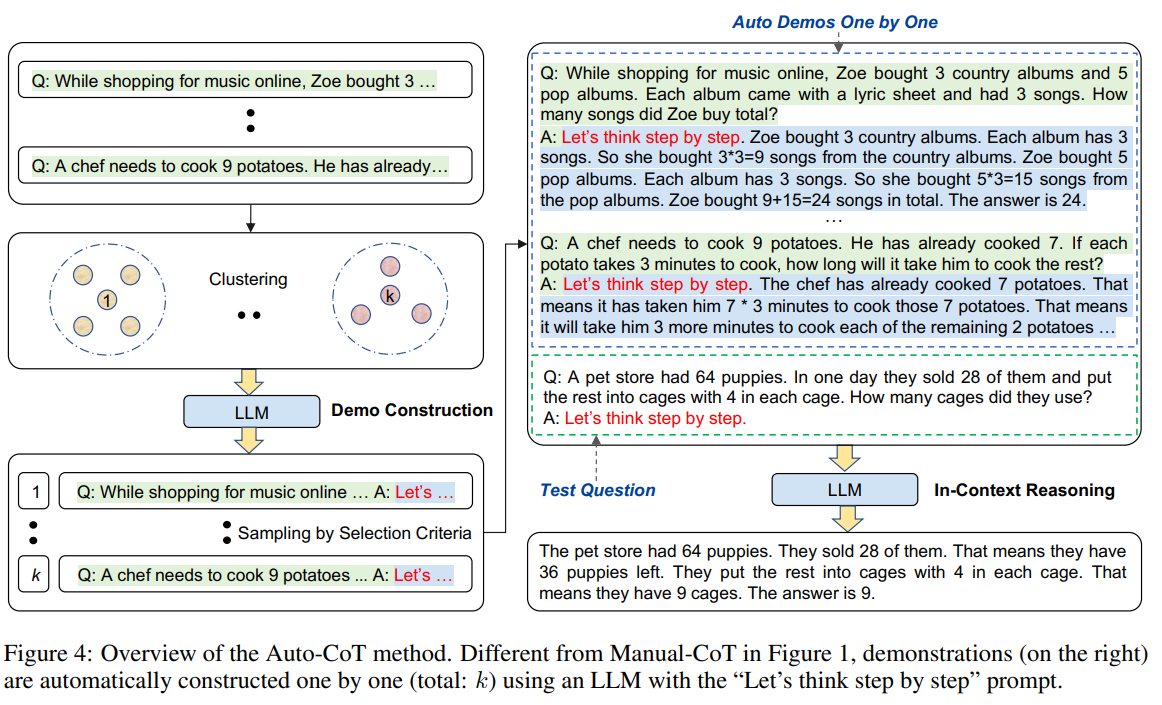
논문은 다양한 질문들에서 BERT의 Vector Representation 통해 k개로 클러스터링 합니다.
이제 그 클러스터 중심에 가장 가까운 질문들을 GPT통해 Zero-Shot-Cot를 진행하고, 까다로운 필터링 작업 후 Few-Shot-Cot로 활용됩니다.
이렇게 진행한 실험이 높은 성과를 가지고 왔다네요
자동 Chain-of-Thought (CoT) 방식: Auto-CoT의 혁신
Chain-of-Thought(CoT) 프롬프트는 대형 언어 모델(LLM)의 추론 능력을 극대화할 수 있는 강력한 방법으로 입증되었습니다. 그러나 기존 CoT 방식, 특히 수작업으로 설계된 Manual-CoT는 많은 시간과 리소스를 소모하며, 자동화되지 않은 점이 큰 단점으로 작용했습니다.
이를 해결하기 위해, 논문에서는 Auto-CoT를 제안합니다. Auto-CoT는 예제를 자동으로 생성하고, 클러스터링을 통해 다양한 예제를 제공하여 모델의 일반화 성능을 높이는 방법입니다.
기존 CoT 방식의 한계
- Manual-CoT:
사람이 직접 예제를 설계하고 입력해야 하므로 시간과 노력이 많이 필요합니다. 새로운 데이터셋이나 도메인에서는 이 작업을 반복해야 한다는 점도 큰 제약입니다. - Zero-Shot-CoT:
"Let's think step by step"과 같은 단순한 프롬프트로 모델이 추론 과정을 생성하도록 유도하지만, 복잡한 문제에서는 성능 한계가 명확합니다.
예제 없이 진행되기 때문에 특정 유형의 문제에서 오류가 자주 발생할 가능성이 큽니다.
Auto-CoT: 새로운 접근법
Auto-CoT의 핵심은 다음 두 가지 과정으로 요약됩니다.
- 질문 클러스터링:
- 질문 데이터셋을 BERT 기반 Vector Representation으로 변환합니다.
- 이를 통해 의미적으로 유사한 질문들을 k-means 클러스터링으로 그룹화하고, 각 클러스터에서 가장 중심에 가까운 질문(대표 질문)을 선택합니다.
- Zero-Shot-CoT 및 필터링:
- 선택된 대표 질문들에 대해 Zero-Shot-CoT를 사용해 reasoning chain(추론 과정)을 자동 생성합니다.
- 생성된 예제는 추가로 휴리스틱 필터링을 통해 너무 길거나, 잘못된 답변을 포함한 예제를 제거합니다.
- 최종적으로 다양한 클러스터에서 샘플링된 예제들을 조합하여 Few-Shot-CoT에 활용합니다.
Auto-CoT의 성과
이 논문에서 제안한 Auto-CoT 방식은 기존 CoT 방식과 비교해 뛰어난 성능을 보였습니다.
- 효율성:
Manual-CoT처럼 사람의 수작업이 필요하지 않아 리소스를 크게 절약합니다. - 일반화 성능 향상:
다양한 클러스터에서 샘플링한 예제를 활용하여 특정 문제 유형에 과적합되지 않고, 다양한 문제에 강건한 성능을 보입니다. - 실험 결과:
MultiArith와 같은 산술 추론 데이터셋에서 Auto-CoT는 Manual-CoT보다 높은 정확도를 기록했으며, 다른 데이터셋에서도 경쟁력 있는 성과를 달성했습니다.
결론
Auto-CoT는 CoT prompting을 자동화하며, 기존의 번거로운 수작업 과정을 대체할 수 있는 혁신적인 방법입니다.
다양한 질문 클러스터링과 자동 reasoning 생성을 통해 모델의 일반화 능력을 크게 향상시켰으며, 앞으로 다양한 도메인과 데이터셋에서 폭넓게 활용될 가능성을 열어줍니다.
| 연구 목적 | - Chain-of-Thought(CoT) 프롬프트를 자동화하여 수작업 없이 효율적이고 높은 성능을 달성. - 질문 클러스터링과 Zero-Shot-CoT 기반 reasoning 생성을 활용하여 다양한 문제 유형에 대응 가능하도록 설계. |
| 기존 한계점 | - Manual-CoT: 높은 성능을 보이지만, 수작업 부담이 큼. - Zero-Shot-CoT: 단순한 방식으로는 오류 포함 가능성이 크며, 성능 한계가 존재. - Few-Shot-CoT: 적은 데이터로는 일반화 능력 부족. |
| 제안 방법 (Auto-CoT) | 1. 질문 클러스터링: Sentence-BERT를 통해 질문을 임베딩한 후 k-means 클러스터링을 수행하여 다양한 유형의 질문 클러스터 생성. 2. Zero-Shot-CoT 기반 예제 생성: 각 클러스터에서 대표 질문을 선정, Zero-Shot-CoT 방식으로 reasoning 생성. 3. 휴리스틱 필터링: 긴 질문, 오류 포함된 reasoning 제거 후 최적의 예제 구성. |
| 주요 특징 | - 다양한 클러스터에서 예제를 샘플링하여 모델의 일반화 능력 향상. - 언어 모델로 reasoning을 자동 생성해 수작업 부담 최소화. - 잘못된 예제에 강건하며 스트리밍 환경에서도 성능 유지. |
| 실험 환경 | - 모델: GPT-3 (text-davinci-002), Codex (code-davinci-002). - 데이터셋: 10개 벤치마크 데이터셋 (Arithmetic, Commonsense, Symbolic Reasoning). - 비교 대상: Zero-Shot, Zero-Shot-CoT, Few-Shot, Manual-CoT. |
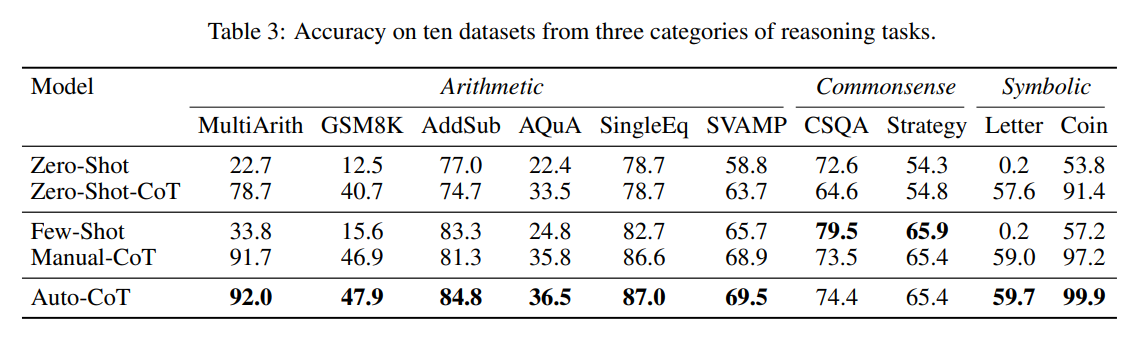
| 주요 결과 | 1. Table 3: Auto-CoT는 대부분의 데이터셋에서 Manual-CoT와 유사하거나 더 높은 성능 기록. 2. Figure 6: 잘못된 예제가 포함된 상황에서도 성능 감소 폭이 적음. 3. Figure 7: 스트리밍 환경에서도 Manual-CoT 수준의 성능 유지. |
| 주요 성과 | - MultiArith에서 Auto-CoT(92.0%) > Manual-CoT(91.7%). - Symbolic Reasoning(Coin Flip)에서 Auto-CoT(99.9%) > Manual-CoT(97.2%). - Codex 모델에서도 Auto-CoT가 높은 성능을 기록 (Table 4). |
| 강점 | - 효율성: Manual-CoT 없이도 높은 성능. - 다양성: 클러스터링을 통한 다양한 예제 반영. - 일반화: 다른 LLM(Codex)에서도 높은 성능 유지. - 강건성: 잘못된 예제나 스트리밍 환경에서도 성능 유지. |
| 한계점 | - 클러스터링과 Zero-Shot-CoT 기반 생성에 추가적인 계산 비용 소요. - Zero-Shot-CoT의 품질에 성능이 의존. - 도메인 특화 문제를 해결하기 위한 추가 연구 필요. - 클러스터 수 k 최적화 기준이 불명확. |
| 결론 및 기여 | - Auto-CoT는 CoT prompting을 자동화하며, Manual-CoT와 유사한 성능을 효율적으로 달성. - 다양한 문제 유형과 환경에서도 강건한 성능을 유지. - CoT prompting의 수작업 부담을 제거하며 LLM의 추론 능력을 혁신적으로 향상. |
1. 연구 배경 및 문제 정의
최근 대형 언어 모델(LLMs)은 복잡한 문제 해결을 위해 중간 추론 단계를 생성하는 Chain-of-Thought (CoT) prompting을 활용하여 우수한 성능을 보이고 있다. CoT prompting에는 크게 두 가지 접근 방식이 있다.
- Zero-Shot-CoT: “Let’s think step by step” 같은 간단한 프롬프트를 활용해 모델이 단계별로 사고하게 만드는 방법.
- Manual-CoT: 사람이 직접 문제와 추론 과정을 작성하여 예제로 제공하는 방법.
Manual-CoT 방식은 강력한 성능을 보이지만, 도메인별로 세밀한 예제를 수작업으로 작성해야 하는 부담이 크다. 이 연구에서는 수작업 없이 자동으로 CoT prompting을 생성하는 Auto-CoT 방법을 제안하여 이러한 문제를 해결하고자 한다.
2. 제안하는 Auto-CoT 방법
Auto-CoT는 자동으로 CoT 예제를 생성하는 방법으로, 다음의 두 가지 주요 단계를 포함한다.
- 질문 클러스터링 (Question Clustering)
- 데이터셋 내 질문들을 유사한 질문끼리 몇 개의 클러스터로 나눈다.
- Sentence-BERT를 이용해 질문을 임베딩한 후, k-means 알고리즘으로 클러스터링 수행.
- 각 클러스터의 중심과 가까운 대표 질문을 선정.
- 예제 샘플링 및 생성 (Demonstration Sampling)
- 각 클러스터에서 대표 질문을 선정하고, LLM을 이용해 Zero-Shot-CoT 방식으로 추론 과정을 생성.
- 너무 긴 질문이나 불필요한 복잡성을 가진 경우를 걸러내는 간단한 휴리스틱 필터링 적용.
- 이렇게 자동 생성된 예제들은 Manual-CoT 없이도 효과적인 prompting이 가능하도록 구성됨.
3. Auto-CoT의 주요 실험 결과
Auto-CoT의 성능을 검증하기 위해 다양한 논리적 추론 및 계산 문제 데이터셋에서 실험을 수행하였다.
- 10개의 벤치마크 데이터셋에서 테스트
- 산술적 추론 (Arithmetic Reasoning): MultiArith, GSM8K, AddSub 등
- 상식적 추론 (Commonsense Reasoning): CSQA, StrategyQA 등
- 기호적 추론 (Symbolic Reasoning): Last Letter Concatenation, Coin Flip 등
- Manual-CoT과의 비교 실험 결과
- Auto-CoT는 Manual-CoT과 동등하거나 더 나은 성능을 보여주었음.
- 특히 Manual-CoT 없이도 높은 성능을 유지하여, 수작업 없이도 효과적인 CoT prompting이 가능함을 증명.
- Zero-Shot-CoT보다 높은 성능
- Zero-Shot-CoT 방식은 오류가 많지만, Auto-CoT는 클러스터링을 통해 다양한 질문 유형을 반영하여 성능 향상.
- 대표적으로 MultiArith 데이터셋에서 Zero-Shot-CoT(78.7%)보다 높은 92.0%의 정확도를 기록.
- 다양성을 고려한 클러스터링의 효과
- 단순히 유사한 질문을 수집하는 Retrieval-Q-CoT 방식은 오히려 성능이 떨어짐.
- 반면, 질문을 다양한 클러스터에서 선정하면 성능이 향상됨.
- 즉, 다양한 유형의 질문을 예제로 포함하는 것이 CoT prompting에 중요한 요소임을 실험적으로 입증.
- 실시간 스트리밍 환경에서도 효과적 (Streaming Setting)
- 데이터가 점진적으로 들어오는 환경에서도 Auto-CoT는 점진적으로 학습된 Manual-CoT 수준의 성능을 유지.
4. Auto-CoT의 강점 및 향후 연구 방향
✅ 강점
- Manual-CoT 없이도 높은 성능을 달성
- 도메인별 수작업 부담을 제거
- 다양성을 고려한 샘플링 기법으로 모델 성능 향상
- Zero-Shot-CoT의 한계를 보완
🔍 한계 및 향후 연구 방향
- 현재는 질문을 클러스터링하는 과정이 필요하여 추가적인 계산량이 발생.
- 더 정교한 필터링 기법을 도입하여 자동 생성되는 예제의 품질을 높일 필요가 있음.
- 다양한 모델에서 일반화될 수 있는지 추가 연구 필요.
5. 결론
이 연구는 Auto-CoT를 활용하여 CoT prompting을 자동화할 수 있음을 실험적으로 검증하였다. Manual-CoT이 없이도 높은 성능을 유지할 수 있으며, 질문을 클러스터링하고 대표적인 질문을 선택하는 방식이 효과적이라는 점을 보여준다. 앞으로 더욱 정교한 자동화 기법이 개발된다면, CoT prompting을 활용한 대형 언어 모델의 추론 능력이 더욱 향상될 것으로 기대된다. 🚀
Auto-CoT는 수작업 없이 Chain-of-Thought(CoT) 예제를 자동으로 생성하여 LLM의 추론 능력을 향상시키는 방법이다.
이를 위해 크게 두 가지 핵심 과정이 있다.
- 질문 클러스터링 (Question Clustering)
- 예제 샘플링 및 생성 (Demonstration Sampling)
아래에서 각각의 과정에 대해 자세히 설명하겠다.
1. 질문 클러스터링 (Question Clustering)
Auto-CoT의 핵심 아이디어는 "다양한 유형의 질문을 포함하면 모델의 추론 능력이 향상된다"는 것이다.
따라서 단순히 유사한 질문을 가져오는 것이 아니라, 다양한 유형의 질문을 균형 있게 선택하는 과정이 필요하다.
이를 위해 Sentence-BERT를 활용하여 질문을 몇 개의 클러스터로 나눈 후, 각 클러스터에서 대표 질문을 선택하는 방식을 사용한다.
📌 질문 클러스터링 과정
- 질문을 벡터로 변환
- 데이터셋의 모든 질문을 Sentence-BERT를 사용해 임베딩 (vector representation)으로 변환.
- 이를 통해 의미적으로 유사한 질문들은 서로 가까운 벡터로 매핑됨.
- k-means 클러스터링 적용
- 변환된 질문 벡터를 k-means 알고리즘을 사용하여 k개의 클러스터로 그룹화.
- 이때 k는 몇 개의 대표 예제를 만들지에 따라 결정됨 (보통 k=8).
- 각 클러스터에서 대표 질문 선택
- 각 클러스터에서 중심에 가까운 질문을 대표 질문으로 선택.
- 중심 질문은 클러스터 내에서 가장 평균적인 질문을 의미하며, 이를 통해 다양한 유형의 질문을 반영할 수 있음.
- 질문 정렬 및 우선순위 결정
- 선택된 질문들을 다시 정렬하여 가장 일반적인 질문이 먼저 사용되도록 설정.
- 이 과정은 질문을 적절한 순서로 배열하여 모델이 더 나은 예제 학습을 할 수 있도록 돕는다.
🔎 클러스터링이 필요한 이유
Auto-CoT 이전의 방법들은 유사한 질문들을 가져오는 방식 (Retrieval-Q-CoT)을 사용했으나, 이는 성능이 오히려 감소하는 문제가 있었다.
그 이유는 유사한 질문들이 동일한 오류를 포함할 가능성이 높기 때문이다.
Auto-CoT는 다양한 질문 유형을 포함하는 방식으로 이러한 문제를 해결하여 모델이 다양한 문제 해결 패턴을 학습할 수 있도록 한다.
2. 예제 샘플링 및 생성 (Demonstration Sampling)
질문 클러스터링이 완료되면, 각 클러스터에서 대표 질문을 샘플링하여 LLM을 이용해 자동으로 CoT 예제를 생성한다.
📌 예제 샘플링 및 생성 과정
- 질문에 대한 CoT 생성
- 대표 질문을 선택한 후, Zero-Shot-CoT 방식으로 reasoning chain(추론 과정)을 자동 생성.
- 즉, "Let's think step by step" 프롬프트를 사용하여 모델이 스스로 단계별 reasoning을 생성하도록 유도.
- 단순한 휴리스틱 필터링 적용
- 너무 긴 질문, 너무 긴 추론 과정, 복잡한 질문을 제거하여 가장 직관적인 예제만 남김.
- 기준:
- 질문 길이: 60 단어 이하
- 추론 과정 (CoT) 단계 수: 5 단계 이하
- 답이 명확하게 추론 과정에 포함되어야 함
- 생성된 예제 구조
- 생성된 예제는 다음과 같은 형식을 가짐:
Q: 문제 문장 A: Let's think step by step. (자동 생성된 Chain-of-Thought reasoning) The answer is (최종 정답)
- 생성된 예제는 다음과 같은 형식을 가짐:
- 최종 예제 집합 구성
- 샘플링된 질문과 자동 생성된 CoT reasoning을 결합하여 최종적으로 8개의 CoT 예제 집합을 생성.
- 이를 통해 모델이 다양한 유형의 reasoning을 학습할 수 있도록 함.
🔎 왜 샘플링이 중요한가?
- Zero-Shot-CoT는 완벽하지 않음 → 생성된 reasoning에 오류 포함 가능
- 만약 유사한 질문만을 가져오면 동일한 오류를 반복할 확률이 높아짐
- 따라서 다양한 유형의 질문을 가져오면서 오류를 최소화하는 것이 중요
Auto-CoT는 이를 해결하기 위해 질문을 다양하게 샘플링하고, 일정 기준을 충족하는 예제만 사용하는 전략을 사용한다.
3. Auto-CoT의 동작 개요 (전체 프로세스 정리)
Auto-CoT는 다음과 같은 흐름으로 동작한다.
- 질문 클러스터링
- 질문을 Sentence-BERT로 임베딩한 후, k-means 클러스터링을 수행.
- 클러스터 내에서 가장 중심적인 질문을 대표 질문으로 선택.
- 예제 샘플링 및 CoT 생성
- 대표 질문을 샘플링한 후, Zero-Shot-CoT를 사용하여 reasoning chain을 자동 생성.
- 휴리스틱 필터링을 적용하여 너무 긴 질문이나 비효율적인 reasoning을 제거.
- 최종 예제 집합 구성
- 선택된 예제들을 8개 정도의 CoT 예제 세트로 구성하여 모델에 제공.
이 과정에서 중요한 점은 다양성을 확보하면서도 정확도를 유지하는 것이다.
4. 실험 결과 및 Auto-CoT의 성능 검증
Auto-CoT의 효과를 검증하기 위해 10개의 벤치마크 데이터셋에서 성능을 평가하였다.
🔎 실험 결과 요약
- Auto-CoT는 Manual-CoT과 동등하거나 더 높은 성능을 보였다.
- Zero-Shot-CoT보다 높은 정확도를 기록.
- 다양성을 고려한 클러스터링이 성능 향상에 중요한 역할을 함이 입증됨.
예를 들어, MultiArith 데이터셋에서 Zero-Shot-CoT(78.7%) 대비 Auto-CoT(92.0%)가 더 높은 정확도를 기록하였다.
5. 결론 및 Auto-CoT의 의의
Auto-CoT는 Manual-CoT 없이도 효과적인 CoT prompting을 자동으로 생성할 수 있는 방법이다.
✅ 주요 기여점
- Manual-CoT 없이 높은 성능을 유지하여, 사람의 개입 없이도 CoT prompting을 활용할 수 있도록 함.
- 다양한 질문을 샘플링하여 모델의 일반화 성능 향상.
- Zero-Shot-CoT의 한계를 보완하여 자동으로 더 나은 예제를 생성할 수 있도록 함.
🔍 향후 연구 방향
- 현재는 질문 클러스터링 과정이 추가적인 계산량을 필요로 함 → 더 효율적인 클러스터링 기법 연구 필요.
- Zero-Shot-CoT의 오류를 줄이기 위해 더 정교한 필터링 기법 개발.
- 다양한 LLM에 적용하여 일반화 가능성을 연구.
결론
Auto-CoT는 CoT prompting을 자동화하여 LLM의 reasoning 능력을 향상시키는 혁신적인 방법이다.
Manual-CoT이 없이도 높은 성능을 유지할 수 있으며, 다양한 질문을 균형 있게 선택하는 것이 성능 향상의 핵심 요인임을 입증했다.
이 연구는 향후 CoT prompting을 활용한 LLM의 추론 능력 향상 및 자동화된 학습 방식에 중요한 기여를 할 것으로 기대된다. 🚀


네, 정확합니다! Auto-CoT는 기존 Manual-CoT나 Zero-Shot-CoT의 한계를 극복하기 위해 설계된 방식으로, 수동 작업 없이 언어 모델의 reasoning을 자동으로 생성하여 CoT 예제로 사용하는 방법입니다. 이를 통해 효율성과 성능을 동시에 높이고자 합니다.
Auto-CoT의 핵심 목표
- 리소스 절감: Manual-CoT 방식처럼 사람이 직접 추론 과정을 설계하는 작업을 없앰.
- 다양성 확보: 질문 유형과 접근법의 다양성을 반영하여 모델의 일반화 능력을 높임.
- Zero-Shot-CoT의 한계 극복: 단일 방식으로 생성된 reasoning의 오류 가능성을 줄이고, 정교한 예제를 제공.
Auto-CoT의 동작 원리
1. 질문 클러스터링 (Clustering Questions)
- 목적: 질문을 의미적으로 그룹화하여 다양한 유형의 질문을 대표하는 클러스터를 생성.
- 방법:
- Sentence-BERT로 질문을 임베딩(vector화)하여 의미적으로 유사한 질문을 벡터 공간에서 가까운 위치에 매핑.
- k-means 클러스터링을 수행하여 질문을 k개의 클러스터로 나눔.
- 각 클러스터의 중심에 가장 가까운 질문을 대표 질문으로 선택.
- 다양성 보장: 단일 클러스터에서 예제를 모두 선택하는 것이 아니라, 모든 클러스터에서 균형 있게 대표 질문을 선택하여 다양한 유형의 질문을 포함.
2. 예제 생성 및 샘플링 (Demo Construction & Sampling)
- 목적: Zero-Shot-CoT 방식으로 대표 질문에 대해 reasoning을 자동 생성하고, 이를 CoT 예제로 사용.
- 방법:
- 대표 질문에 대해 "Let's think step by step" 프롬프트를 사용하여 reasoning chain 생성.
- 생성된 예제를 대상으로 휴리스틱 필터링을 적용:
- 너무 긴 질문 및 추론 단계 제거.
- 추론 과정에 오류가 있는 경우 제거.
- 최대한 간결하고 명료한 reasoning을 선택.
- 이렇게 생성된 예제를 클러스터별로 하나씩 선택하여 최종적으로 다양한 질문 유형을 포함하는 CoT 세트를 구성.
- 장점: 단일 방식으로 예제를 생성하지 않고, 클러스터별로 예제를 균형 있게 샘플링하여 다양한 접근법을 모델이 학습할 수 있도록 보장.
Auto-CoT의 차별점
- 기존 Manual-CoT는 사람이 설계한 제한된 예제를 사용하며, 리소스 소모가 큼.
- 기존 Zero-Shot-CoT는 단일 방식의 reasoning을 제공하므로, 오류가 포함될 가능성이 높음.
- Auto-CoT는:
- 언어 모델을 사용해 reasoning을 자동 생성함으로써 수작업 부담을 제거.
- 클러스터링과 샘플링 과정을 통해 다양한 질문 유형과 접근법을 반영.
- 필터링을 통해 생성된 예제의 품질을 보장.
Auto-CoT의 실험적 성능
- 다양한 논리적, 산술적, 상식적 추론 문제에서 Auto-CoT는 Manual-CoT와 동등하거나 더 높은 성능을 기록.
- MultiArith 데이터셋에서:
- Zero-Shot-CoT: 78.7%
- Auto-CoT: 92.0%
결론
Auto-CoT는 다양성과 자동화를 통해 CoT prompting의 효율성과 성능을 향상시키는 방법입니다. 클러스터링을 통해 다양한 질문 유형을 반영하고, 언어 모델로 reasoning을 생성한 뒤 정교한 필터링을 적용하여 최종적으로 다양성과 품질을 모두 충족하는 CoT 세트를 구성합니다.
이 방법은 추후 다양한 도메인 및 모델에서의 일반화와 성능 향상에도 기여할 가능성이 큽니다.


실험 결과 분석 및 이유
Auto-CoT의 성능을 다양한 데이터셋에서 평가한 결과, Manual-CoT와 비교해 경쟁력 있는 성능을 보였으며 Zero-Shot-CoT 및 Few-Shot-CoT보다 더 나은 성과를 기록했습니다.
1. 실험 결과 요약
(1) Table 3: GPT-3를 활용한 10개 데이터셋 실험 결과
- Arithmetic Reasoning (MultiArith, GSM8K 등):
Auto-CoT는 대부분의 산술 데이터셋에서 Manual-CoT와 유사하거나 더 높은 성능을 기록.- 예: MultiArith에서 Auto-CoT(92.0%) > Manual-CoT(91.7%).
- 이는 Auto-CoT가 다양한 질문 유형을 반영해 모델의 추론 능력을 더욱 일반화한 결과로 볼 수 있음.
- Commonsense Reasoning (CSQA, StrategyQA):
CSQA와 StrategyQA 같은 상식 추론 문제에서도 Auto-CoT는 Manual-CoT와 비슷한 성능을 기록.- 이는 다양성 확보와 휴리스틱 필터링이 CoT 예제의 품질을 높였음을 보여줌.
- Symbolic Reasoning (Letter, Coin):
Coin Flip 문제에서 99.9%의 정확도를 기록하며 Manual-CoT(97.2%)보다 높은 성능을 보임.- 이는 Auto-CoT가 Symbolic Reasoning에 특히 강점을 가진다는 점을 시사.
(2) Table 4: Codex 모델을 활용한 실험 결과
- Codex 모델을 활용했을 때도 Auto-CoT는 Manual-CoT와 유사하거나 높은 성능을 기록.
- 예: GSM8K에서 Auto-CoT(62.8%) > Manual-CoT(59.4%).
- Codex와 같은 다른 언어 모델에서도 Auto-CoT가 적용 가능하며, 그 효과가 일반적임을 입증.
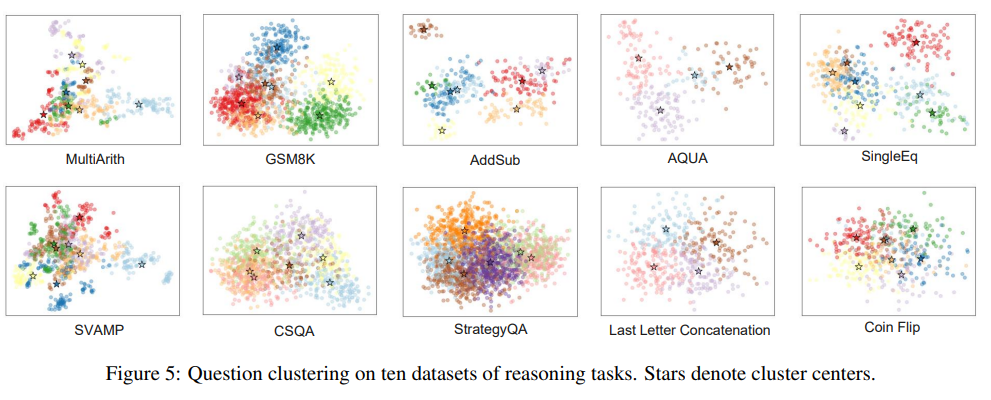
(3) Figure 5: 질문 클러스터링 시각화
- 10개 데이터셋의 질문 클러스터링 결과에서 클러스터 별로 패턴이 뚜렷함을 확인.
- 이는 Auto-CoT의 클러스터링 전략이 질문 유형별로 특화된 예제를 생성할 수 있는 기초가 된다는 점을 강조.
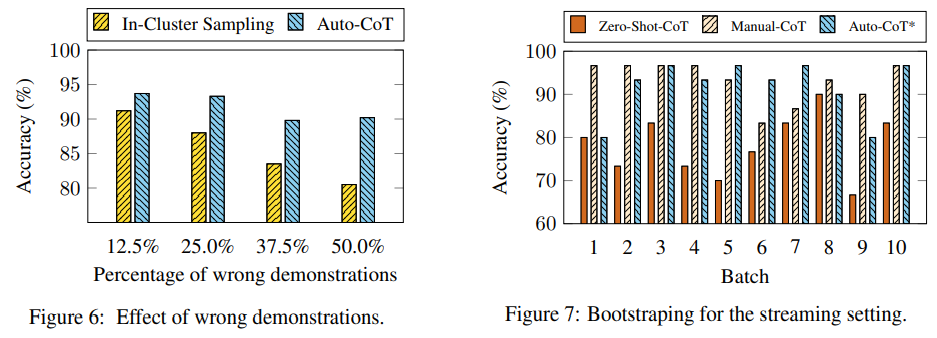
(4) Figure 6: 잘못된 예제의 영향
- In-Cluster Sampling(단일 클러스터 내 샘플링)보다 Auto-CoT는 잘못된 예제에 더 강건함.
- 잘못된 예제가 50% 포함되어도 성능 감소 폭이 적음.
- 이는 Auto-CoT가 다양한 클러스터에서 예제를 선택함으로써 오류의 영향을 완화했음을 보여줌.
(5) Figure 7: 스트리밍 환경 실험
- 스트리밍 환경에서도 Auto-CoT는 지속적으로 성능을 유지.
- Batch 1에서는 Zero-Shot-CoT와 동일했으나, 이후 Batch에서는 Manual-CoT에 근접한 성능을 달성.
2. 결과가 이렇게 나온 이유
✅ Auto-CoT의 강점
- 다양한 클러스터로부터 샘플링
- 질문을 클러스터링한 후, 각 클러스터에서 대표 질문을 선택하여 다양한 유형의 예제를 학습.
- 이는 모델이 특정 유형의 문제에 과적합되지 않고, 다양한 문제를 해결할 수 있는 일반화 능력을 키움.
- 언어 모델 기반 자동 reasoning 생성
- Manual-CoT와 달리 Auto-CoT는 언어 모델을 통해 reasoning을 자동 생성.
- 휴리스틱 필터링을 통해 생성된 reasoning의 품질을 유지하면서도 다양한 질문 유형을 반영.
- 강건한 성능
- 잘못된 예제나 제한된 데이터 환경에서도 Auto-CoT는 성능 감소 폭이 작음.
- 이는 다양성에 기반한 예제 샘플링과 휴리스틱 필터링의 조화로, 오류의 영향을 최소화했기 때문.
- 스트리밍 환경에서의 유연성
- 데이터가 점진적으로 들어오는 환경에서도 성능을 유지하며, 실시간 추론에 적합.
3. 타당성
Auto-CoT의 성능 및 접근 방식은 다음 이유로 타당하다고 평가할 수 있음:
- 효율성: Manual-CoT와 유사한 성능을 자동으로 달성하며, 수작업 리소스를 절약.
- 확장성: 다양한 데이터셋과 모델(Codex, GPT-3)에 적용 가능.
- 강건성: 잘못된 예제나 다양한 문제 유형에서도 성능이 유지됨.
4. 한계점
🔻 계산 비용
- 클러스터링과 Zero-Shot-CoT 기반 예제 생성을 위해 추가적인 계산 비용이 필요.
- 특히, 클러스터링 단계에서 질문 데이터셋이 큰 경우 효율성이 저하될 수 있음.
🔻 Zero-Shot-CoT의 품질 의존
- Auto-CoT는 Zero-Shot-CoT 방식으로 reasoning을 생성하기 때문에, Zero-Shot-CoT의 성능 한계가 Auto-CoT에도 영향을 미칠 수 있음.
🔻 도메인별 특화 부족
- 다양한 클러스터에서 샘플링을 한다고 해도, 특정 도메인에 특화된 문제를 해결하기에는 한계가 있을 수 있음.
🔻 클러스터 수 설정
- 클러스터 개수 kk의 설정이 성능에 영향을 미칠 수 있으나, 이에 대한 최적화 기준이 명확하지 않음.
5. 결론
Auto-CoT는 기존 Manual-CoT의 수작업 부담을 줄이고, Zero-Shot-CoT의 한계를 극복하며, 높은 성능을 달성할 수 있는 혁신적인 방법입니다. 다양성을 강조한 샘플링 전략과 자동 reasoning 생성이 주요 강점으로 작용했으며, 이를 통해 대부분의 데이터셋에서 Manual-CoT와 유사하거나 더 나은 성능을 보였습니다.
그러나 계산 비용과 특정 도메인 특화 문제, Zero-Shot-CoT 의존성과 같은 한계점도 존재하므로, 향후 연구에서는 효율성 최적화 및 품질 향상을 위한 개선이 필요합니다.
Auto-CoT는 Chain-of-Thought(CoT) prompting을 자동화한 혁신적인 접근법으로, 기존 연구들의 한계를 보완하면서도 새로운 방향성을 제시합니다. 이를 기반으로 다음과 같은 관련 연구와 논문들을 정리할 수 있습니다.
1. CoT prompting과 관련된 주요 연구
1.1 Chain-of-Thought(CoT) Prompting
- Kojima et al., 2022: "Large Language Models are Zero-Shot Reasoners"
- 주요 내용:
- "Let's think step by step"과 같은 간단한 프롬프트를 통해 대형 언어 모델(LLM)이 중간 추론 과정을 생성하도록 유도.
- Zero-Shot-CoT 방법론의 시초로, reasoning task에서 높은 성능을 보임.
- 한계:
- 단일 프롬프트 방식으로는 복잡한 문제에서 오류 발생 가능.
- 특정 도메인이나 데이터셋에 과적합될 위험 존재.
- Auto-CoT와의 관계:
- Zero-Shot-CoT를 기반으로 reasoning을 자동 생성하지만, Auto-CoT는 클러스터링과 다양한 샘플링을 통해 성능과 일반화를 강화.
- 주요 내용:
1.2 Few-Shot 및 Manual-CoT
- Wei et al., 2022a: "Chain of Thought Prompting Elicits Reasoning in Large Language Models"
- 주요 내용:
- Few-Shot-CoT 및 Manual-CoT 프롬프트를 설계해 다양한 reasoning task에서 성능을 개선.
- CoT를 활용한 reasoning이 LLM의 복잡한 문제 해결 능력을 강화함을 입증.
- 한계:
- 예제 설계에 수작업 리소스가 많이 필요.
- 도메인 확장이 어렵고, 새로운 데이터셋마다 다시 설계해야 함.
- Auto-CoT와의 관계:
- Manual-CoT의 수작업 문제를 해결하며, 다양한 데이터셋에서 자동으로 CoT 예제를 생성.
- 주요 내용:
2. LLM의 자동화 및 최적화 연구
2.1 Automatic Prompt Optimization
- Gao et al., 2021: "Making Pre-trained Language Models Better Few-shot Learners"
- 주요 내용:
- 프롬프트를 수작업으로 설계하지 않고, 자동으로 최적화하는 "LM-BFF" 방법론 제안.
- Few-shot 학습에서 프롬프트의 효과를 극대화.
- Auto-CoT와의 관계:
- Auto-CoT는 프롬프트 최적화가 아닌, 자동 reasoning 생성과 다양성에 초점을 맞춤.
- 그러나 자동화된 접근법이라는 점에서 공통점을 가짐.
- 주요 내용:
2.2 Retrieval-Augmented Generation (RAG)
- Lewis et al., 2020: "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
- 주요 내용:
- 외부 검색(retrieval) 시스템과 생성 모델을 결합해 지식 집약적 문제 해결.
- 모델의 reasoning이 아닌, 정보를 검색하여 성능을 높이는 방식.
- Auto-CoT와의 관계:
- Auto-CoT는 외부 지식 검색이 아니라, 모델의 reasoning 자체를 개선하는 방식.
- 주요 내용:
3. 질문 클러스터링 및 다양성 활용 연구
3.1 질문 클러스터링
- Sentence-BERT (Reimers and Gurevych, 2019): "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks"
- 주요 내용:
- 질문 임베딩을 통해 문장 간 유사도를 계산하는 효율적인 방식.
- 다양한 NLP 태스크에서 활용 가능.
- Auto-CoT와의 관계:
- 질문 클러스터링에 Sentence-BERT를 사용하여 질문 유형을 그룹화하고 대표 질문을 선정.
- 주요 내용:
3.2 Diversity-Aware Sampling
- Zhao et al., 2021: "Calibrate Before Use: Improving Few-Shot Performance of Language Models"
- 주요 내용:
- Few-shot 학습에서 다양한 예제를 사용하는 샘플링 전략 제안.
- 단일 유형의 데이터에 과적합되는 문제를 방지.
- Auto-CoT와의 관계:
- Auto-CoT는 다양한 클러스터에서 질문을 선택해 모델의 추론 능력을 강화.
- 주요 내용:
4. 잘못된 예제와 강건성 관련 연구
4.1 Wrong Demonstrations의 영향
- Min et al., 2022: "Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?"
- 주요 내용:
- Few-shot 학습에서 잘못된 예제가 포함되면 성능에 부정적 영향을 미칠 수 있음을 분석.
- 그러나, 적절한 예제의 다양성이 이 영향을 완화 가능.
- Auto-CoT와의 관계:
- Auto-CoT는 다양한 클러스터에서 샘플링하여 잘못된 예제의 영향을 줄임.
- 주요 내용:
4.2 Robustness in Language Models
- Hendrycks et al., 2021: "Measuring Massive Multitask Language Understanding"
- 주요 내용:
- LLM의 강건성(robustness)을 평가하는 MMLU 벤치마크 소개.
- 다양한 태스크와 데이터셋에서 모델의 성능 분석.
- Auto-CoT와의 관계:
- Auto-CoT는 다양한 데이터셋에서 높은 성능을 유지하며, 모델의 강건성을 강화하는 방법론.
- 주요 내용:
5. Auto-CoT와 유사한 자동화 접근 연구
5.1 Self-Generated Prompts
- Schick and Schütze, 2021: "It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners"
- 주요 내용:
- 언어 모델이 스스로 예제를 생성하여 Few-shot 성능을 개선할 수 있음을 보임.
- Auto-CoT와의 관계:
- Auto-CoT는 모델이 reasoning chain을 생성하는 방식으로 스스로 예제를 구성.
- 주요 내용:
5.2 Program-Synthesis-Based Reasoning
- Chen et al., 2021: "Evaluating Large Language Models Trained on Code"
- 주요 내용:
- 코드 생성 모델(Codex)을 사용해 복잡한 reasoning task를 해결.
- CoT 방식과 유사하게 코드 실행으로 reasoning 능력을 강화.
- Auto-CoT와의 관계:
- Auto-CoT도 Codex 모델을 활용해 효과를 입증했으며, reasoning의 자동화를 중점으로 삼음.
- 주요 내용:
6. 향후 연구 방향
- 계산 비용 최적화: Auto-CoT의 클러스터링과 Zero-Shot-CoT 생성 비용을 줄이기 위한 연구 필요.
- 도메인 특화 모델 개발: 특정 도메인에서의 CoT prompting 성능을 강화하는 방법론 연구.
- LLM의 추론 능력 개선: Auto-CoT를 기반으로 reasoning chain 품질을 지속적으로 개선할 방법 모색.
- 스트리밍 환경 최적화: 실시간 데이터 스트리밍 환경에서 Auto-CoT의 성능을 더욱 강화.
Auto-CoT는 CoT prompting의 자동화를 선도하며, 관련 연구와 결합하여 NLP와 AI의 다양한 응용 분야에서 새로운 가능성을 열어갈 것으로 기대됩니다.

Figure 2 및 Retrieval-Q-CoT에 대한 정리
1. 문제 정의
- Retrieval-Q-CoT는 테스트 질문과 유사한 질문을 검색(retrieval)하여 CoT 예제로 사용하는 방법입니다. 이 방식은 Manual-CoT처럼 높은 성능을 기대할 수 있지만, Zero-Shot-CoT로 생성된 잘못된 reasoning chain이 포함될 경우, 유사성에 의한 오도(Misleading by Similarity) 문제가 발생할 수 있습니다.
- 핵심 문제: 유사한 질문에서 잘못된 reasoning chain이 모델의 추론 방향을 오도하여 잘못된 답변을 반복하게 만듦.
2. 실험 설정
- 데이터셋: MultiArith(600개 질문).
- 오류 탐지:
- Zero-Shot-CoT로 600개 질문에 대해 reasoning을 생성한 후, 잘못된 답변을 생성한 128개 질문(21.3%)을 수집하여 Q로 정의.
- Q에 대해 Retrieval-Q-CoT와 Random-Q-CoT를 적용한 후, 각 방법이 해결하지 못한 질문(잘못된 답변 생성)을 "unresolved questions"로 정의.
- Unresolving Rate:
- Unresolving Rate=Unresolved Questions / 128 (질문 개수)
- 값이 높을수록 Zero-Shot-CoT와 동일한 오류를 반복할 가능성이 높음을 의미.
3. 주요 결과
- Retrieval-Q-CoT: Unresolving Rate = 46.9%
- 테스트 질문과 유사한 질문을 선택했으나, Zero-Shot-CoT의 잘못된 reasoning chain이 반복됨.
- 유사성에 의한 오도가 발생하여 성능 저하.
- Random-Q-CoT: Unresolving Rate = 25.8%
- 테스트 질문과 유사하지 않은 질문을 무작위로 샘플링하여 사용.
- 더 다양한 예제가 포함되어 유사성에 의한 오도 문제를 피함.
- 결론:
- 유사한 질문을 선택할수록 잘못된 reasoning chain의 영향력이 커져 오류를 반복할 가능성이 높아짐.
4. 사례 분석
- Retrieval-Q-CoT의 실패 사례:
- 질문: "남은 부분(rest)을 요리하는 데 얼마나 걸릴까?"
- 유사 질문: "총 요리 시간을 계산하라."
- Zero-Shot-CoT는 유사 질문에서 "총 요리 시간(total)"이라는 개념을 잘못 학습.
- 이로 인해 Retrieval-Q-CoT도 "rest"를 "total"로 혼동해 잘못된 답변 생성.
- Random-Q-CoT의 성공 사례:
- 유사한 질문이 아닌, 무작위로 선택된 다양한 질문으로 인해 특정 오류가 반복되지 않음.
- "rest"의 의미를 제대로 이해하고 정답 도출.
5. 결론
- Retrieval-Q-CoT의 한계:
- 유사한 질문을 사용하는 것이 오히려 모델의 reasoning을 잘못된 방향으로 오도할 수 있음.
- 잘못된 예제(reasoning chain)가 포함될 경우, 성능 저하를 초래.
- Random-Q-CoT의 장점:
- 더 다양한 예제를 포함하여 모델이 잘못된 reasoning chain의 영향을 덜 받음.
- Auto-CoT의 강점:
- Retrieval-Q-CoT와 달리, 다양한 질문 클러스터에서 예제를 선택하여 유사성에 의한 오도 문제를 최소화.
- 더 정교한 필터링과 클러스터링 전략으로 잘못된 예제의 영향을 줄임.
Figure 2의 시사점은 Retrieval-Q-CoT의 성능 저하 원인을 "유사성에 의한 오도"로 정의하며, Auto-CoT가 이를 효과적으로 해결할 수 있는 방법을 제시한다는 점입니다.
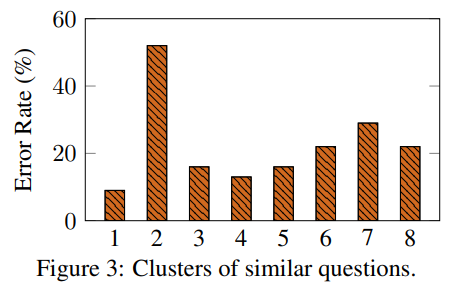

Figure 3 및 관련 내용 요약: Errors Frequently Fall into the Same Cluster
1. 문제 정의
- Zero-Shot-CoT의 오류 패턴 분석:
테스트 질문을 클러스터로 나누고 각 클러스터에서 Zero-Shot-CoT가 자주 실패하는 질문 비율(오류율)을 계산하여, 특정 클러스터에서 오류가 집중되는지 분석. - 핵심 질문:
- Zero-Shot-CoT가 특정 유형의 질문에서 자주 실패하는 경향이 있는가?
- 유사 질문 기반 방법(Retrieval-Q-CoT)이 이러한 오류를 반복할 가능성이 있는가?
2. 실험 설정
- 질문 클러스터링:
- 600개의 테스트 질문을 k-means 알고리즘으로 k=8개의 클러스터로 나눔.
- Sentence-BERT를 사용해 질문 임베딩 후 클러스터링 수행.
- 오류율 계산:
- 각 클러스터에서 Zero-Shot-CoT가 생성한 잘못된 답변의 비율(오류율)을 계산:
- Error Rate=Wrong Answers in Cluster / Total Questions in Cluster
- 각 클러스터에서 Zero-Shot-CoT가 생성한 잘못된 답변의 비율(오류율)을 계산:
3. 주요 결과
- Figure 3:
- Cluster 2는 52.3%의 높은 오류율을 기록, 이는 Zero-Shot-CoT가 특정 유형의 문제에서 자주 실패함을 나타냄.
- 다른 클러스터에서는 오류율이 상대적으로 낮아, 오류가 특정 유형의 질문에 집중되는 경향이 있음을 확인.
- Frequent-Error Cluster:
- Cluster 2와 같은 frequent-error cluster는 Zero-Shot-CoT의 고유한 한계를 반영:
- 특정 패턴의 질문에 대해 필요한 추론 기술이 부족.
- 이는 해당 클러스터 질문의 reasoning chain에서 공통적인 실수를 유발.
- Cluster 2와 같은 frequent-error cluster는 Zero-Shot-CoT의 고유한 한계를 반영:
4. Retrieval-Q-CoT의 한계
- 유사성 기반 방법의 문제:
- Retrieval-Q-CoT는 테스트 질문과 유사한 질문을 선택하므로, 오류율이 높은 frequent-error cluster에서 질문을 선택할 가능성이 높음.
- 이로 인해 잘못된 reasoning chain이 반복되고, 오류를 더욱 증폭시킬 위험이 있음.
- Figure 2와 연결:
- Retrieval-Q-CoT의 높은 "Unresolving Rate"(46.9%)는 frequent-error cluster의 질문이 자주 선택되면서 발생한 결과로 해석 가능.
- 유사성이 높은 질문들에서 동일한 실수를 반복하는 것이 주요 원인.
5. 사례 분석(Table 2)
- Frequent-Error Cluster에서의 실수 반복:
- 질문: "남은 부분(rest)을 요리하는 데 얼마나 걸릴까?"
- Zero-Shot-CoT의 reasoning chain은 "총 시간(total)"을 계산하는 실수를 범함.
- Retrieval-Q-CoT는 유사 질문을 선택해 동일한 실수를 반복.
- 반면, Random-Q-CoT는 유사 질문이 아닌 다양한 질문을 사용하여 오류를 피함.
6. 결론
- Zero-Shot-CoT의 한계:
- 특정 클러스터에서 높은 오류율이 발생하며, 이는 Zero-Shot-CoT가 특정 유형의 문제를 해결하기 위한 기술 부족을 반영.
- 생성된 reasoning chain의 완성도가 낮아 오류를 반복적으로 유발.
- Retrieval-Q-CoT의 취약성:
- 유사 질문을 선택하는 방식은 frequent-error cluster에서 질문을 반복적으로 선택하여, Zero-Shot-CoT의 실수를 증폭.
- Random-Q-CoT의 강점:
- 다양한 질문을 사용하여 특정 클러스터의 오류로부터 영향을 덜 받음.
- Auto-CoT의 개선 방향:
- 클러스터링을 기반으로 다양한 유형의 질문을 포함하며, 특정 클러스터에 집중되지 않도록 설계.
- Zero-Shot-CoT의 reasoning chain 품질을 높이는 추가적 필터링 및 개선 필요.
Figure 3의 시사점
- 특정 질문 유형에 대한 오류가 반복되는 현상은 Zero-Shot-CoT의 고유 한계를 보여줌.
- Retrieval-Q-CoT의 유사성 기반 접근법은 이러한 문제를 해결하지 못하며, 오히려 악화시킬 수 있음.
- Auto-CoT는 이 문제를 해결하기 위해 클러스터 간의 다양성을 보장하며, Zero-Shot-CoT의 단점을 보완하는 전략을 사용.