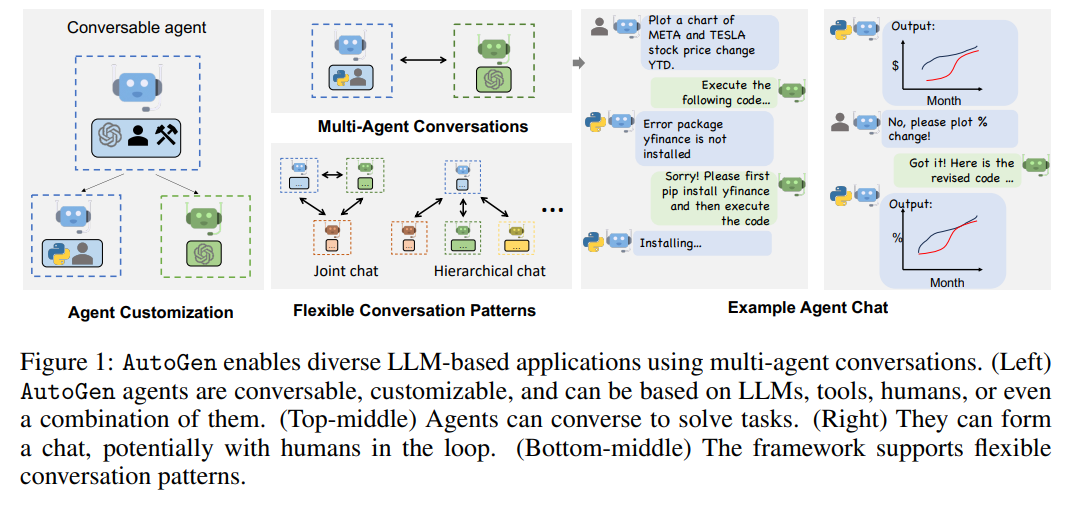
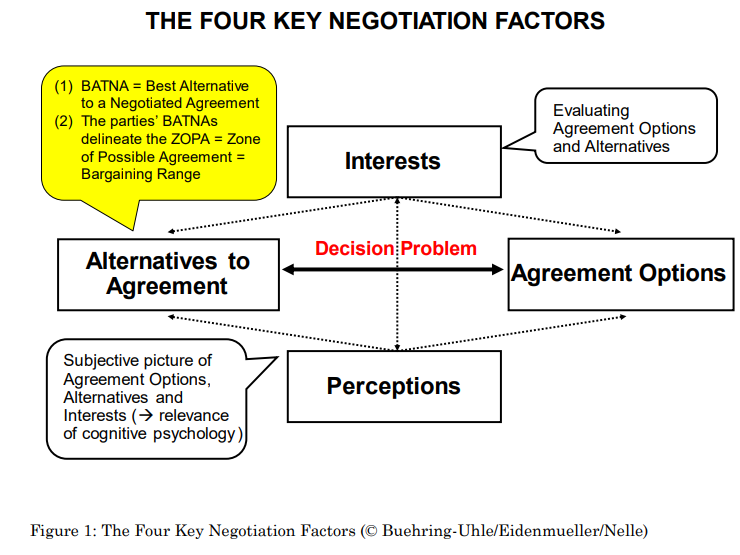
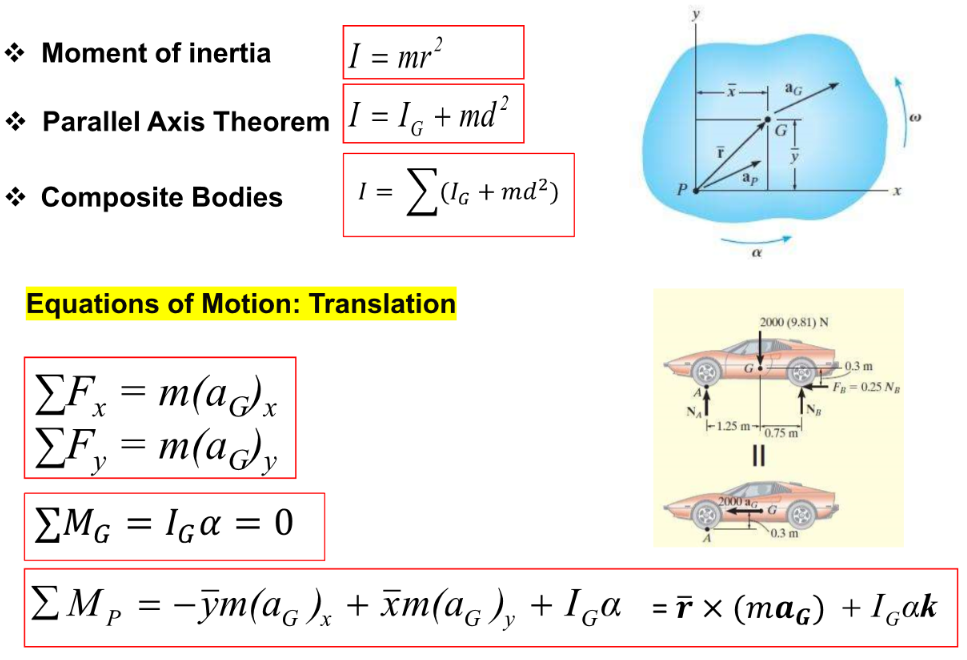
https://arxiv.org/abs/2305.10142 Improving Language Model Negotiation with Self-Play and In-Context Learning from AI FeedbackWe study whether multiple large language models (LLMs) can autonomously improve each other in a negotiation game by playing, reflecting, and criticizing. We are interested in this question because if LLMs were able to improve each other, it would imply thearxiv.org 음 여기선 이..