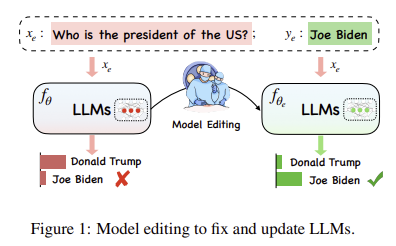
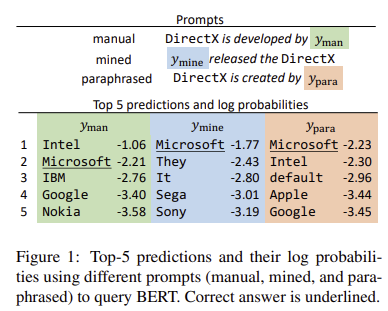
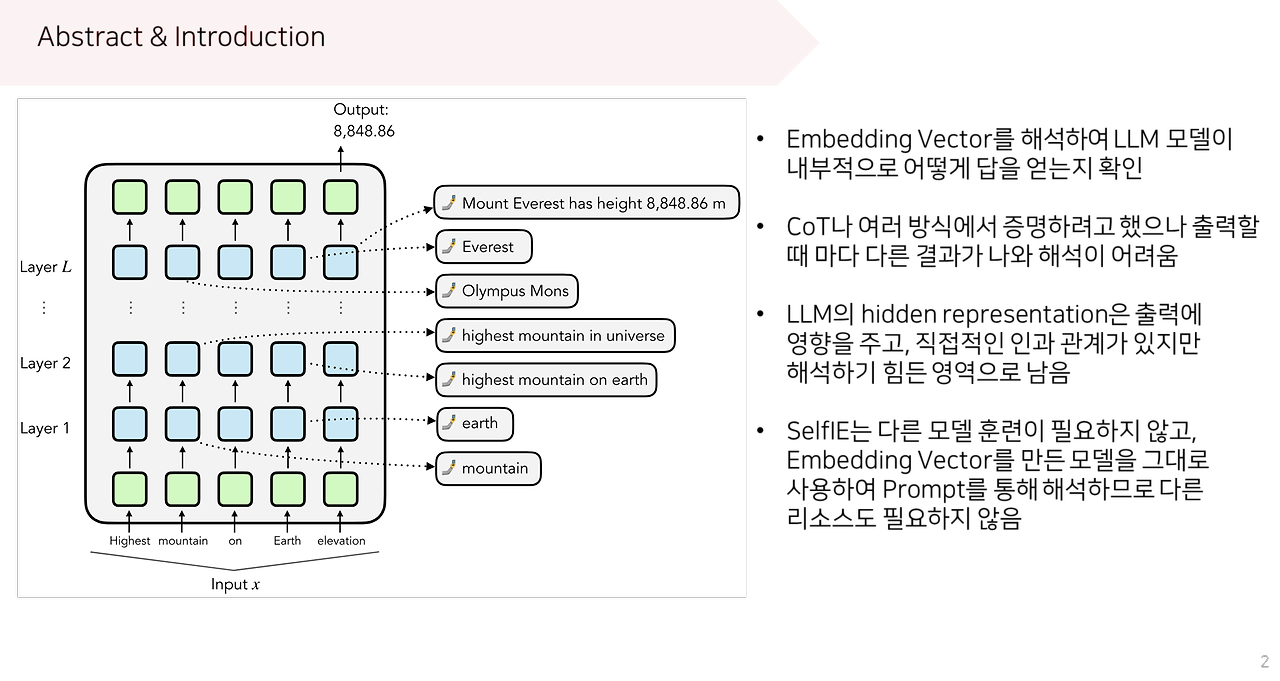
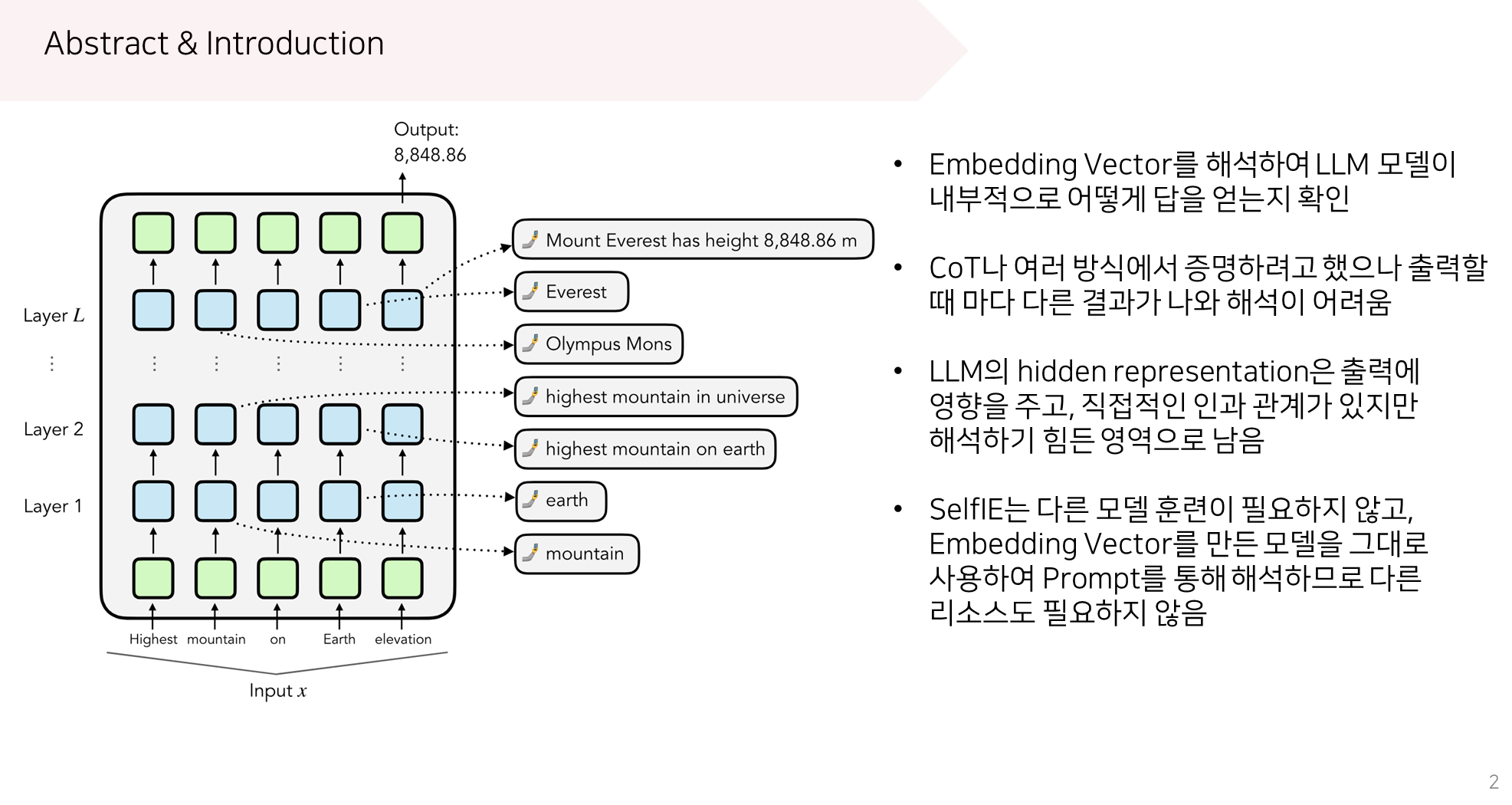
https://arxiv.org/abs/2305.13172 Editing Large Language Models: Problems, Methods, and OpportunitiesDespite the ability to train capable LLMs, the methodology for maintaining their relevancy and rectifying errors remains elusive. To this end, the past few years have witnessed a surge in techniques for editing LLMs, the objective of which is to efficientlarxiv.org 이 논문은 새로운 정보를 반영하지 못 하는 LLM의 단점을..