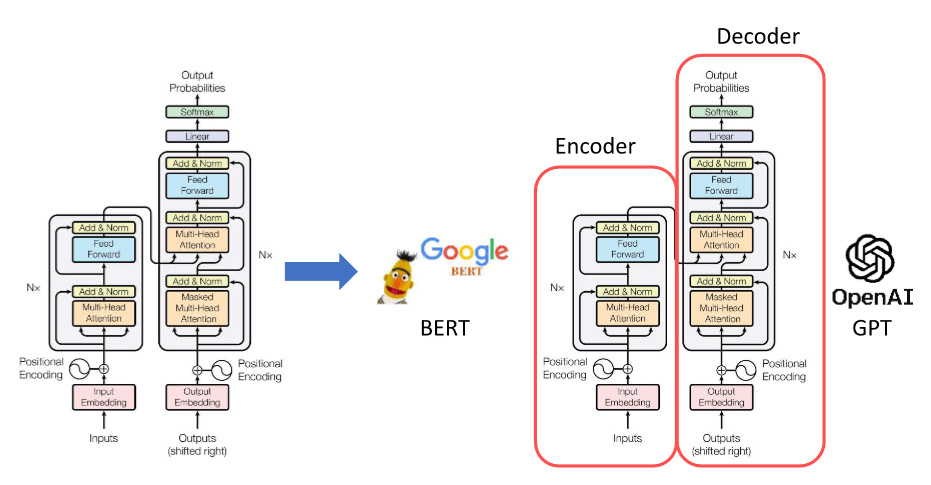
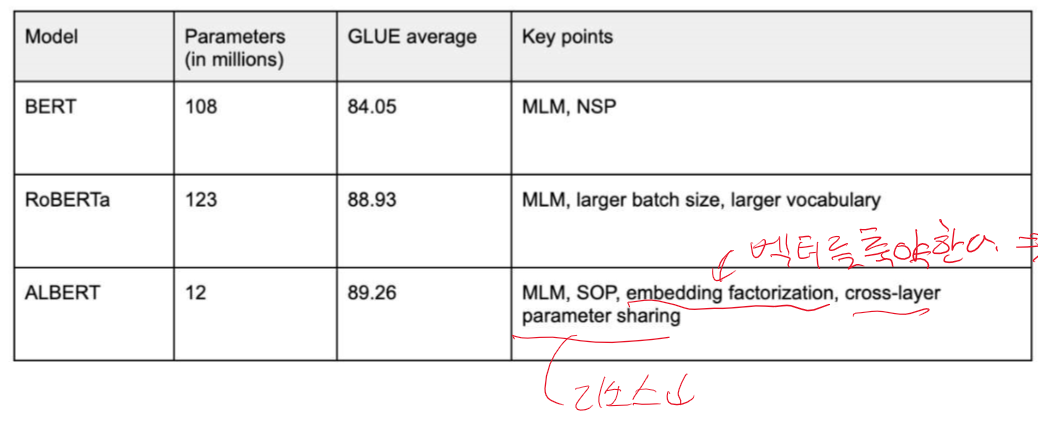
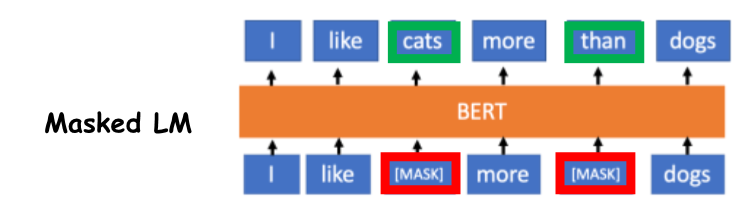
생성형 모델의 대부분은 Decoder 모델이다. input이 들어가면 차례대로 결과가 나오고, 질문에 대한 답을 생성하는데 목적이 있다. fine-tuning으로 말이 되는지 안되는지 supervised learning도 진행한다. 이러한 fine-tuning없이 모든 task를 잘하길 원했고, 스케일 up, 학습 up하여 좋은 데이터셋을 가지고 좋은 모델을 만들려고 지속적으로 시도하였다. GPT2는 시존 책 코퍼스가 아니라 웹 텍스트를 가져왔고, 데이터의 양도 많이 늘렸다.transformer layer도 12층에서 48층으로 늘리면서 토큰 수도 늘었다.117M -> 1.5B로 파라미터도 엄청나게 증가!Vocab size를 늘렸다 == 인코딩 방식을 세분화 하였다.input을 넣을 때 무슨 일을 할지 ..