BERT에서는 supervised learning과 unsupervised learning의 중간인 semi(self) supervised learning을 Pre-training 과정(실제 task 풀기 전 전반적인 지식 탐구)에 한다. Fine-tuning을 진행할 때 labeled dataset으로 supervised learning을 진행한다.



SpanBERT에선 NSP가 빠졌다. 마스킹을 span레벨로 진행하여 문맥을 조금 더 파악할 수 있게 되었다.
Longformer : BERT의 변형으로 긴 doc를 처리한다.
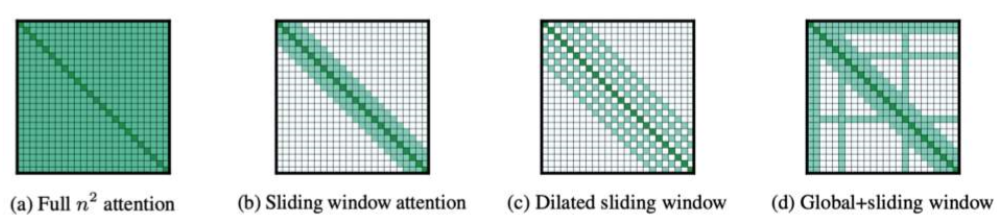
긴 doc에서 global로 attention을 진행하게 되면 연산량이 엄청나게 늘어난다 -> 특정 패턴을 주자
NLU는 NLG에 비해 그나마 쉽다.

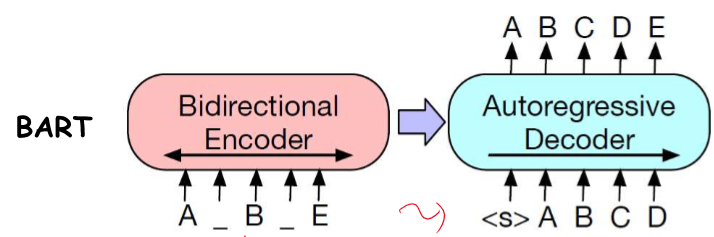
BART는 원본 문장을 생성한다.

다양한 방식으로 self supervised learning을 진행한다.
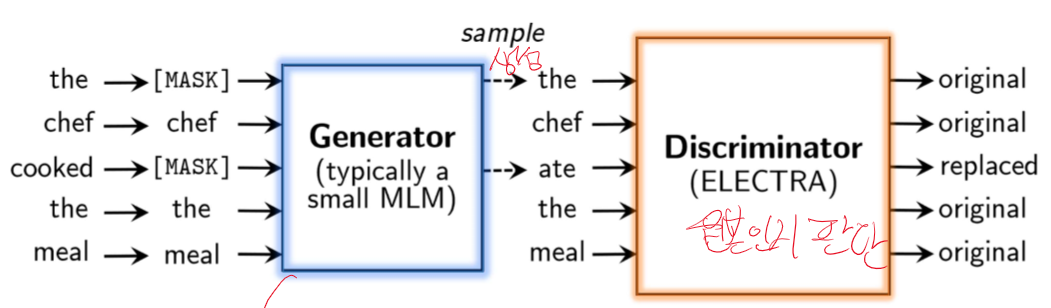
원본과 같이 생성하게 만드는 역할을 한다.

vision + NLP로 텍스트와 이미지를 동시에 집어넣어 Mask된 단어를 맞춘다.
NSP와 비슷하게 제일 첫번째는 문장과 사진이 일치하는지 확인하여 이미지 기반 택스트 이해, 택스트 기반 이미지 이해를 확인할 수 있다.

각자 알아서 이미지를 처리하고 합친다!

비전과 NLP 모델을 섞꼬 있다.

3가지 task모두 진행하는 BERT + fast R-CNN 모델이다.
Self-supervised Learning 개요
- Self-supervised Learning: 인간의 주석을 필요로 하지 않는 학습 방법으로, 데이터 내에서 스스로 레이블을 생성하여 학습합니다.
- 적용 분야: 자연어 처리(NLP), 컴퓨터 비전(CV), 그리고 멀티모달 학습(텍스트와 이미지의 결합) 등에서 널리 사용됩니다.
주요 모델 및 기법
1. RoBERTa
- RoBERTa의 개선 사항:
- Dynamic Masking: 정적 마스킹 대신 동적 마스킹을 사용하여 학습 효율성 향상.
- Removing NSP Loss: Next Sentence Prediction(NSP) 손실 제거.
- Large Batch Training: 큰 배치 크기를 사용하여 최적화 속도 및 최종 성능 개선.
- More Data: 더 많은 데이터셋을 사용한 사전 학습.
- 데이터셋 및 배치 크기 비교:
- BERT: 16GB 데이터, 배치 크기 256, 1M 스텝
- RoBERTa: 160GB 데이터, 배치 크기 2K (125K 스텝), 배치 크기 8K (31K 스텝)
2. ALBERT
- ALBERT: BERT의 경량화 버전으로 파라미터 수를 줄이고 메모리 효율성을 높임.
- Factorized Embedding Parameterization: 임베딩 매트릭스를 두 단계로 분해하여 파라미터 수를 줄임.
- Sentence Order Prediction: 문장 순서 예측을 통해 모델의 능력을 향상시킴.
3. SpanBERT
- SpanBERT: 연속된 랜덤 스팬을 마스킹하고, 스팬 경계를 통해 전체 스팬을 예측하는 모델.
- 특징:
- NSP 목표 제거
- 텍스트 스팬의 샘플링과 마스킹
4. Longformer
- Longformer: 긴 문서의 사전 학습을 목표로 함.
- 주요 기법:
- Sliding Window Attention
- Dilated Sliding Window
- Global + Sliding Window
5. BART
- BART: 손상된 문서를 복원하는 데 사용되는 모델로, 양방향 인코더와 오토리그레시브 디코더를 결합.
- 주요 기법:
- Token Masking
- Token Deletion
- Sentence Permutation
- Text Infilling
- Document Rotation
6. ELECTRA
- ELECTRA: 생성된 토큰과 원본 토큰을 구분하는 방식으로 학습하는 모델.
7. VisualBERT
- VisualBERT: 텍스트와 이미지의 시각적 정보와 언어적 정보를 동시에 학습.
- 주요 기법:
- MASK 토큰을 사용하여 텍스트와 시각적 정보를 결합하여 예측.
- 텍스트와 이미지가 일치하는지 예측.
8. ViLBERT
- ViLBERT: 시각적 정보와 언어적 정보를 통합하여 학습하는 모델.
- 주요 기법:
- 이미지 영역의 15%와 단어를 마스킹하여 학습.
9. UNITER
- UNITER: BERT와 Fast R-CNN을 사용하여 시각적 정보와 언어적 정보를 통합하여 학습.
- 주요 기법:
- Masked Language Modeling (MLM)
- Image-Text Matching (ITM)
- Masked Region Modeling (MRM)
결론
- Self-supervised Learning은 레이블된 데이터 없이도 높은 성능을 달성할 수 있는 강력한 기법입니다.
- NLP, 컴퓨터 비전 및 멀티모달 학습 분야에서 다양한 모델들이 개발되고 있으며, 각 모델은 특정 문제를 해결하기 위한 독특한 기법을 사용합니다.
이 요약을 통해 Self-supervised Learning과 관련된 주요 개념, 모델, 기법 및 실험 결과를 이해할 수 있습니다. 각 모델의 특징과 개선 사항을 살펴보며, Self-supervised Learning이 다양한 학습 작업에서 어떻게 활용되는지를 배울 수 있습니다.
O, X 문제 (10문제)
- Self-supervised learning은 라벨이 없는 데이터를 이용하여 학습하는 방법이다. (O)
- 해설: Self-supervised learning은 라벨이 없는 데이터를 사용하여 모델을 학습하는 방법입니다.
- SpanBERT는 무작위 토큰을 마스킹하는 대신 연속적인 스팬을 마스킹한다. (O)
- 해설: SpanBERT는 연속적인 스팬을 마스킹하고, 경계 예측 목적을 사용합니다.
- RoBERTa는 BERT와 달리 Next Sentence Prediction(NSP) 손실을 사용한다. (X)
- 해설: RoBERTa는 NSP 손실을 제거했습니다.
- Longformer는 긴 문서를 전처리하기 위해 슬라이딩 윈도우 주의 메커니즘을 사용한다. (O)
- 해설: Longformer는 긴 문서를 효과적으로 처리하기 위해 슬라이딩 윈도우 주의를 사용합니다.
- BART는 시퀀스-투-시퀀스 프리트레이닝을 위해 텍스트 스팬을 마스킹한다. (O)
- 해설: BART는 텍스트 스팬을 마스킹하고 원래 문서를 예측하는 방식으로 프리트레이닝을 합니다.
- VisualBERT는 텍스트와 이미지의 일치를 예측하는 pretext task를 수행한다. (O)
- 해설: VisualBERT는 텍스트와 이미지의 일치를 예측하는 작업을 수행합니다.
- ViLBERT는 이미지와 텍스트의 특징을 결합하기 위해 코-어텐션 트랜스포머를 사용한다. (O)
- 해설: ViLBERT는 코-어텐션 트랜스포머를 사용하여 이미지와 텍스트의 특징을 결합합니다.
- UNITER는 Masked Language Modeling(MLM)을 수행하지 않는다. (X)
- 해설: UNITER는 Masked Language Modeling(MLM)을 포함한 여러 self-supervised learning 작업을 수행합니다.
- SpanBERT는 NSP 목적을 유지한다. (X)
- 해설: SpanBERT는 NSP 목적을 제거했습니다.
- BART는 문장 순서 섞기와 같은 다양한 프리트레이닝 작업을 수행한다. (O)
- 해설: BART는 문장 순서 섞기, 토큰 삭제 등 다양한 프리트레이닝 작업을 수행합니다.
빈칸 문제 (10문제)
- Self-supervised learning은 __이 없는 데이터를 이용하여 학습하는 방법이다. (라벨)
- 해설: Self-supervised learning은 라벨이 없는 데이터를 사용하여 학습합니다.
- SpanBERT는 무작위 토큰 대신 연속적인 __을 마스킹한다. (스팬)
- 해설: SpanBERT는 연속적인 스팬을 마스킹합니다.
- RoBERTa는 BERT와 달리 __ 손실을 제거했다. (NSP)
- 해설: RoBERTa는 NSP 손실을 제거했습니다.
- Longformer는 긴 문서를 처리하기 위해 __ 윈도우 주의 메커니즘을 사용한다. (슬라이딩)
- 해설: Longformer는 슬라이딩 윈도우 주의 메커니즘을 사용합니다.
- BART는 시퀀스-투-시퀀스 프리트레이닝을 위해 텍스트 __을 마스킹한다. (스팬)
- 해설: BART는 텍스트 스팬을 마스킹합니다.
- VisualBERT는 텍스트와 __의 일치를 예측하는 pretext task를 수행한다. (이미지)
- 해설: VisualBERT는 텍스트와 이미지의 일치를 예측합니다.
- ViLBERT는 __을 사용하여 이미지와 텍스트의 특징을 결합한다. (코-어텐션 트랜스포머)
- 해설: ViLBERT는 코-어텐션 트랜스포머를 사용합니다.
- UNITER는 __ Language Modeling(MLM)을 수행한다. (Masked)
- 해설: UNITER는 Masked Language Modeling(MLM)을 수행합니다.
- SpanBERT는 NSP 목적을 __. (제거했다)
- 해설: SpanBERT는 NSP 목적을 제거했습니다.
- BART는 문장 __ 섞기와 같은 다양한 프리트레이닝 작업을 수행한다. (순서)
- 해설: BART는 문장 순서 섞기 등의 작업을 수행합니다.
서술형 문제 (10문제)
- Self-supervised learning의 장점과 단점을 설명하시오.
- 정답: 장점은 라벨이 없는 대규모 데이터를 활용할 수 있어 비용 효율적이고 다양한 응용에 적용 가능하다는 점입니다. 단점은 사전 학습 과제와 실제 과제 간의 차이가 성능에 영향을 미칠 수 있다는 점입니다.
- 해설: Self-supervised learning은 라벨링 비용을 절감하지만, 사전 학습과 실제 과제의 차이를 극복해야 합니다.
- SpanBERT의 주요 특징과 그 효과를 설명하시오.
- 정답: SpanBERT는 연속적인 스팬을 마스킹하고 경계 예측 목적을 사용하여 문맥 이해를 개선합니다.
- 해설: SpanBERT는 연속적인 스팬 마스킹을 통해 더 나은 문맥 표현을 제공합니다.
- RoBERTa가 NSP 손실을 제거한 이유와 그 효과를 설명하시오.
- 정답: RoBERTa는 NSP 손실이 성능에 부정적인 영향을 미친다고 판단하여 이를 제거했으며, 이로 인해 성능이 향상되었습니다.
- 해설: NSP 손실 제거는 모델 성능을 개선하는 데 도움이 됩니다.
- Longformer의 슬라이딩 윈도우 주의 메커니즘이 긴 문서 처리에 어떻게 도움이 되는지 설명하시오.
- 정답: 슬라이딩 윈도우 주의 메커니즘은 긴 문서에서 전체 문맥을 유지하면서도 효율적인 계산을 가능하게 합니다.
- 해설: 슬라이딩 윈도우는 긴 문서의 문맥을 효과적으로 처리할 수 있게 합니다.
- BART의 시퀀스-투-시퀀스 프리트레이닝 방법을 설명하시오.
- 정답: BART는 텍스트 스팬을 마스킹하고, 시퀀스-투-시퀀스 모델을 사용하여 원래 문서를 복원하는 방식으로 프리트레이닝을 수행합니다.
- 해설: BART는 마스킹된 텍스트를 복원하는 방식으로 학습됩니다.
- 강의 자료에는 Seq2Seq가 없어서 이런게 있었나 했는데 맞다네요
-
더보기
네, 이 문제는 BART의 시퀀스-투-시퀀스(Seq2seq) 프리트레이닝 방법을 설명하는 올바른 문제입니다. BART(Bidirectional and Auto-Regressive Transformers)는 시퀀스-투-시퀀스 모델을 사용하여 프리트레이닝을 수행합니다. 문제와 정답이 정확합니다.
BART의 프리트레이닝 방법
BART는 텍스트의 변형된 형태를 입력으로 받아 원래의 텍스트를 복원하는 방식으로 학습됩니다. 이는 시퀀스-투-시퀀스 모델 구조를 사용하며, 마스킹된 텍스트를 복원하는 과정이 포함됩니다.
주요 프리트레이닝 방법
- 텍스트 스팬 마스킹:
- 입력 텍스트에서 연속된 토큰(스팬)을 마스킹합니다.
- 마스킹된 텍스트는 모델의 입력으로 사용됩니다.
- 텍스트 변형:
- 텍스트 스팬 마스킹 외에도 여러 가지 텍스트 변형 방법이 사용됩니다.
- 예: 텍스트의 순서를 뒤섞거나(shuffling), 텍스트 일부를 삭제하거나(deletion), 문장을 역순으로 배치하는(reverse) 등 다양한 변형을 적용합니다.
- 시퀀스-투-시퀀스 모델:
- BART는 변형된 텍스트를 입력으로 받아 원래의 텍스트를 복원하는 시퀀스-투-시퀀스 모델로 학습됩니다.
- 인코더-디코더 구조를 사용하여 변형된 입력을 인코딩하고, 디코더는 원래 텍스트를 생성합니다.
예시
입력 텍스트: "The quick brown fox jumps over the lazy dog."
마스킹된 텍스트: "The quick [MASK] fox [MASK] over the lazy dog."
모델의 작업: 마스킹된 부분을 원래 텍스트로 복원하는 것.
문제와 해설
문제:
BART의 시퀀스-투-시퀀스 프리트레이닝 방법을 설명하시오.정답:
BART는 텍스트 스팬을 마스킹하고, 시퀀스-투-시퀀스 모델을 사용하여 원래 문서를 복원하는 방식으로 프리트레이닝을 수행합니다.해설:
BART는 마스킹된 텍스트를 복원하는 방식으로 학습됩니다.결론
문제와 정답은 정확합니다. BART는 시퀀스-투-시퀀스 프리트레이닝 방법을 사용하며, 변형된 텍스트를 원래 상태로 복원하는 방식으로 학습됩니다. 이를 통해 다양한 텍스트 변형에 대해 강건한 모델을 만들 수 있습니다.
- 텍스트 스팬 마스킹:
- VisualBERT의 pretext task와 그 효과를 설명하시오.
- 정답: VisualBERT는 텍스트와 이미지의 일치를 예측하는 pretext task를 수행하여 멀티모달 이해 능력을 향상시킵니다.
- 해설: 텍스트와 이미지 일치 예측은 멀티모달 데이터를 효과적으로 학습하게 합니다.
- ViLBERT의 코-어텐션 트랜스포머가 이미지와 텍스트 통합에 어떻게 기여하는지 설명하시오.
- 정답: 코-어텐션 트랜스포머는 이미지와 텍스트 간의 상호작용을 모델링하여 더 나은 통합 표현을 제공합니다.
- 해설: 코-어텐션 트랜스포머는 이미지와 텍스트의 조화를 이루게 합니다.
- UNITER가 수행하는 세 가지 self-supervised learning 작업을 설명하시오.
- 정답: UNITER는 Masked Language Modeling(MLM), Image-Text Matching(ITM), Masked Region Modeling(MRM)을 수행합니다.
- 해설: UNITER는 다양한 self-supervised learning 작업을 통해 멀티모달 표현을 학습합니다.
- SpanBERT의 스팬 마스킹 기법이 문맥 이해에 어떻게 도움이 되는지 설명하시오.
- 정답: 스팬 마스킹은 문장 내 연속된 단어들을 마스킹하여 모델이 더 넓은 문맥을 이해할 수 있도록 돕습니다.
- 해설: 스팬 마스킹은 더 나은 문맥 이해를 제공합니다.
- BART의 다양한 프리트레이닝 작업이 모델 성능에 미치는 영향을 설명하시오.
- 정답: BART의 다양한 프리트레이닝 작업은 모델이 다양한 유형의 변형된 데이터를 복원하도록 학습시켜 더 강력한 일반화 능력을 갖추게 합니다.
- 해설: 다양한 프리트레이닝 작업은 모델의 적응력을 높입니다.
단답형 문제 (10문제)
- Self-supervised learning이란?
- 정답: 라벨이 없는 데이터를 이용하여 학습하는 방법
- 해설: Self-supervised learning은 라벨이 없는 데이터를 사용하여 모델을 학습합니다.
- SpanBERT는 무작위 __ 대신 연속적인 스팬을 마스킹한다.
- 정답: 토큰
- 해설: SpanBERT는 무작위 토큰 대신 연속적인 스팬을 마스킹합니다.
- RoBERTa는 BERT와 달리 어떤 손실을 제거했는가?
- 정답: NSP
- 해설: RoBERTa는 NSP 손실을 제거했습니다.
- Longformer는 긴 문서를 처리하기 위해 어떤 주의 메커니즘을 사용하는가?
- 정답: 슬라이딩 윈도우
- 해설: Longformer는 슬라이딩 윈도우 주의 메커니즘을 사용합니다.
- BART는 시퀀스-투-시퀀스 프리트레이닝을 위해 무엇을 마스킹하는가?
- 정답: 텍스트 스팬
- 해설: BART는 텍스트 스팬을 마스킹합니다.
- VisualBERT는 텍스트와 __의 일치를 예측하는 pretext task를 수행한다.
- 정답: 이미지
- 해설: VisualBERT는 텍스트와 이미지의 일치를 예측합니다.
- ViLBERT는 __ 트랜스포머를 사용하여 이미지와 텍스트의 특징을 결합한다.
- 정답: 코-어텐션
- 해설: ViLBERT는 코-어텐션 트랜스포머를 사용합니다.
- UNITER는 Masked __ Modeling(MLM)을 수행한다.
- 정답: Language
- 해설: UNITER는 Masked Language Modeling(MLM)을 수행합니다.
- SpanBERT는 NSP 목적을 __.
- 정답: 제거했다
- 해설: SpanBERT는 NSP 목적을 제거했습니다.
- BART는 문장 __ 섞기와 같은 다양한 프리트레이닝 작업을 수행한다.
- 정답: 순서
- 해설: BART는 문장 순서 섞기 등의 작업을 수행합니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 16강 - Prompt Engineering (0) | 2024.06.05 |
|---|---|
| 자연어 처리 15강 - Large Language Model (0) | 2024.06.05 |
| 자연어 처리 13강 - Self Supervised Learning 1 (1) | 2024.06.04 |
| 자연어 처리 12강 - Question Answering + BERT (0) | 2024.06.04 |
| 자연어 처리 11강 - Named Entity Recognition (NER) + BERT (2) | 2024.06.03 |