머신러닝의 종류에는 지도, 비지도 강화학습이 있다.
지도학습은 학습셋에 데이터와 라벨이 묶여있다.
비지도 학습은 라벨이 존재하지 않고, 데이터의 패턴끼리 묶는다. 그러나 높은 성과를 기대하기 어렵다.
pre-training = 라벨되거나, 라벨되지 않은 대량의 데이터를 가지고 모델을 학습시킨다.
fine-tuning = 지식을 추가하기 위해 라벨된 데이터를 모델에 학습시킨다.
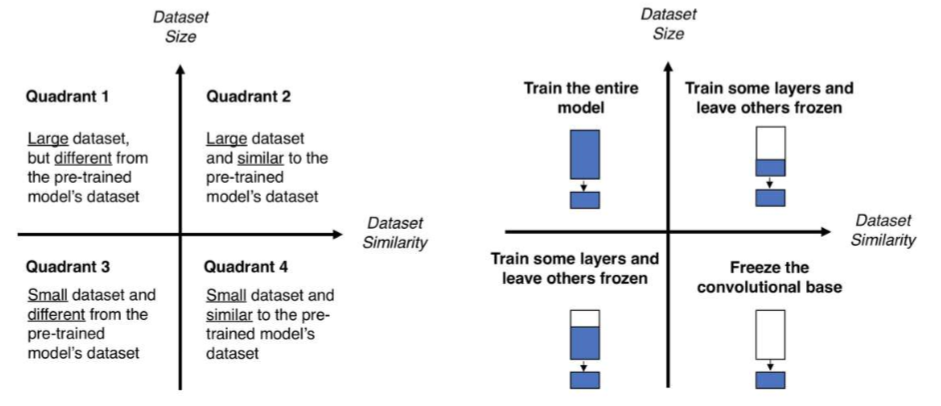
데이터 양, 유사도에 따라 fine-tuning할 때 weight의 변화를 조절한다.
Self supervised lenring은 unsupervised learning으로 pre training 진행할 때 라벨이 없는 데이터를 가지고 학습하는 것을 뜻한다. Pretext task를 진행한다.
RoBERTa
기존의 Static Masking(마스킹이 고정되어 있다.)에서 Dynamic Masking(epoch마다 마스킹 위치가 변한다.)로 변화하였다.
마스킹도 이전에 말했던 것처럼 80%는 마스킹, 10%는 랜덤 단어, 10%는 그대로 입니당
NSP(Next Sentence Prediction)의 Loss를 없애면서 downstream task를 향상시켰다.
배치사이즈와 데이터양을 증가시켜서 성능 향상!
ALBERT
파라미터 수를 줄여서 효율성을 향상시켰다.
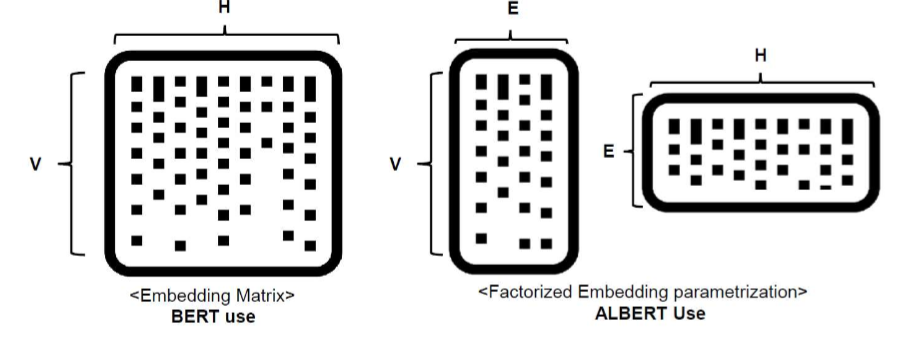
ALBERT (A Lite BERT)는 BERT의 경량화 버전으로, 메모리 사용량과 계산 비용을 줄이기 위해 몇 가지 중요한 개선 사항을 도입했습니다. 그 중 하나가 Factorized Embedding Parameterization입니다. 이를 이해하려면 BERT와의 차이점을 먼저 살펴보겠습니다.
BERT의 임베딩
BERT에서 임베딩 매트릭스는 매우 큰 모델의 파라미터를 차지합니다. 일반적으로, BERT는 다음과 같은 세 가지 주요 임베딩을 사용합니다:
- Token Embedding: 각 단어를 고유한 벡터로 매핑합니다.
- Position Embedding: 각 위치를 나타내는 벡터를 더하여 순서 정보를 추가합니다.
- Segment Embedding: 문장의 구분을 나타내는 벡터를 추가합니다.
이 모든 임베딩은 큰 차원의 벡터를 사용하므로, 전체 모델의 파라미터 수가 매우 큽니다.
ALBERT의 Factorized Embedding Parameterization
ALBERT는 이 임베딩 매트릭스를 두 단계로 분해하여 파라미터 수를 줄입니다:
- Smaller Embedding Dimension: 큰 단어 집합 크기를 더 작은 임베딩 차원으로 매핑합니다.
- Projection Layer: 작은 임베딩 차원을 다시 모델의 히든 차원으로 매핑합니다.
구체적으로 설명하면, BERT에서 V는 어휘(vocabulary) 크기, H는 히든 레이어의 차원입니다. 따라서 BERT의 임베딩 매트릭스는 V x H 크기를 갖습니다. 하지만 ALBERT에서는 임베딩 매트릭스를 두 개의 매트릭스로 분해합니다:
- E는 중간 임베딩 차원입니다. 일반적으로 E < H입니다.
- 첫 번째 매트릭스는 V x E 크기를 갖고, 단어를 작은 임베딩 차원으로 매핑합니다.
- 두 번째 매트릭스는 E x H 크기를 갖고, 작은 임베딩 차원을 모델의 히든 차원으로 매핑합니다.
예시로 이해하기
- BERT에서는 각 단어를 H 차원의 벡터로 직접 매핑하므로 V x H 크기의 임베딩 매트릭스가 필요합니다.
- ALBERT에서는 각 단어를 먼저 E 차원의 벡터로 매핑한 후, 이를 다시 H 차원으로 투영합니다. 따라서 전체 임베딩 매트릭스는 V x E와 E x H로 나뉩니다.
이렇게 하면 전체 파라미터 수가 크게 줄어듭니다. 예를 들어, V = 30,000, H = 768, E = 128이라고 가정하면:
- BERT의 임베딩 매트릭스 크기: 30,000 x 768 = 23,040,000
- ALBERT의 임베딩 매트릭스 크기: 30,000 x 128 + 128 x 768 = 3,840,000 + 98,304 = 3,938,304
장점
- 파라미터 효율성: Factorized Embedding을 사용하면 전체 파라미터 수가 줄어들어 모델의 메모리 사용량과 계산 비용이 감소합니다.
- 일반화 성능: 작은 차원의 임베딩을 사용하여 모델이 더 잘 일반화할 수 있습니다.
결론적으로, Factorized Embedding Parameterization은 ALBERT가 BERT보다 경량화된 모델이 되도록 돕는 중요한 기술 중 하나입니다. 이는 큰 임베딩 매트릭스를 두 단계로 분해하여 파라미터 수를 줄이고, 메모리 사용량과 계산 비용을 크게 감소시킵니다.
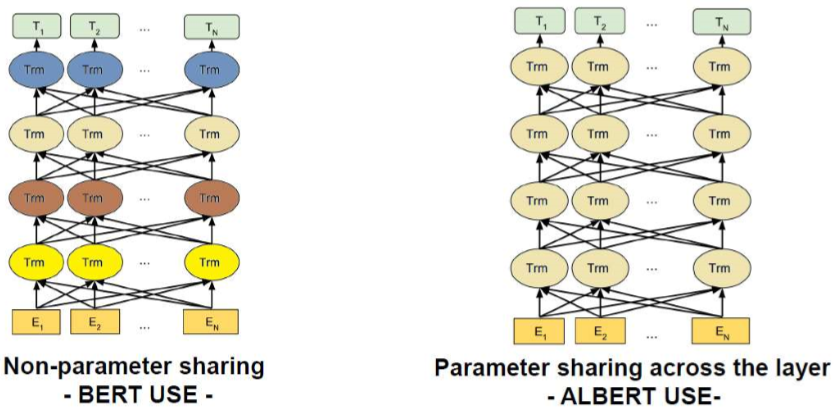
stacked tansformer가 파라미터를 공유한다.
Supervised Learning / Unsupervised Learning
- Supervised Learning: 레이블이 있는 데이터를 사용하여 학습하는 기계 학습 패러다임. 높은 성능을 달성할 수 있지만 많은 레이블된 데이터가 필요함.
- Unsupervised Learning: 레이블이 없는 데이터를 사용하여 패턴을 학습하는 알고리즘. 레이블된 데이터를 만드는 노력이 필요 없지만 높은 성능을 달성하기 어려움.
Pre-training and Fine-tuning
- Pre-training: 대량의 비지도 데이터로 사전 학습을 수행하여 모델의 기초 능력을 구축함.
- Fine-tuning: 사전 학습된 모델을 특정 다운스트림 태스크에 맞추어 미세 조정함.
Supervised Pre-training
- Sequential Transfer Learning: 관련된 태스크의 레이블된 데이터를 활용하여 사전 학습을 수행함.
- Multi-task Learning: 여러 관련된 분류 작업을 활용하여 제한된 학습 데이터를 다루는 접근법.
Self-supervised Learning
- Self-supervised Learning: 인간이 주석을 달지 않은 레이블이 필요 없는 학습 유형. 사전 학습 태스크를 'pretext task'라 하고, 파인 튜닝 시 수행되는 태스크를 'downstream task'라 함.
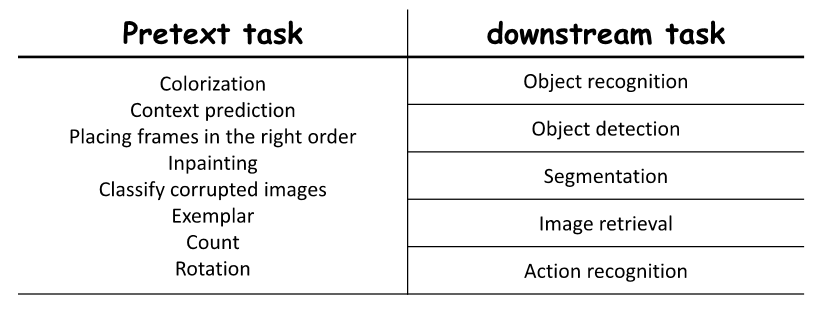
- Pretext Tasks in Computer Vision: 색상화, 컨텍스트 예측, 프레임 순서 정렬, 인페인팅 등 다양한 방법이 있음.
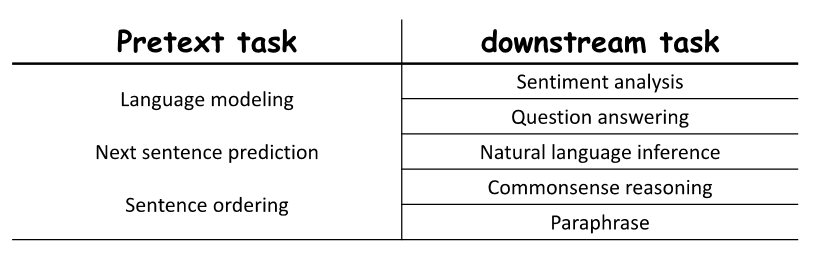
- Pretext Tasks in NLP: 언어 모델링, 다음 문장 예측, 문장 순서 정렬 등이 있음.
BERT 및 RoBERTa
- BERT: 사전 학습과 파인 튜닝을 통해 자연어 처리 작업에서 우수한 성능을 보임.
- RoBERTa: BERT의 개선된 버전으로, 동적 마스킹, NSP 손실 제거, 큰 배치 크기 사용, 더 많은 데이터셋을 사용한 사전 학습 등이 포함됨.
RoBERTa의 주요 개선 사항
- Dynamic Masking: 정적 마스킹 대신 동적 마스킹을 사용하여 학습 효율성 향상.
- Removing NSP Loss: NSP 손실을 제거하여 다운스트림 작업 성능 향상.
- Training with Large Batches: 큰 배치 크기를 사용하여 최적화 속도 및 최종 성능 개선.
- Using More Dataset in Pre-training: 더 많은 데이터셋을 사용하여 모델의 일반화 능력 향상.
ALBERT
- ALBERT: BERT의 효율적인 버전으로, 파라미터 수를 줄이고 메모리 효율성을 높임.
- Factorized Embedding Parameterization: 임베딩 파라미터를 분해하여 모델 크기 축소.
- Sentence Order Prediction: 문장 순서 예측을 통해 모델의 능력을 향상시킴.
Denoising Entity Auto-encoder
- ERNIE: 텍스트와 지식 그래프의 정보를 통합하여 언어 표현을 향상시킴.
Choosing a Pretext Task
- Pretext Task 선택: 다운스트림 작업 데이터의 이해가 중요함. 사람과 모델 모두에게 유용한 작업을 선택해야 함.
이 요약을 통해 Self-supervised Learning, BERT, RoBERTa, ALBERT 등과 관련된 주요 개념, 방법론 및 실험 결과에 대해 이해할 수 있습니다. 각 모델의 특징과 개선 사항을 살펴보며, Self-supervised Learning이 NLP와 컴퓨터 비전에서 어떻게 활용되는지를 배울 수 있습니다.
O, X 문제 (10문제)
- Self-supervised learning은 사람이 주석을 달지 않은 데이터로 학습하는 유형의 학습이다. (O)
- 해설: Self-supervised learning은 사람이 주석을 달지 않은 데이터로 학습하는 유형의 학습입니다.
- Self-supervised learning에서 사전 학습 과제는 '다운스트림 과제'라고 한다. (X)
- 해설: Self-supervised learning에서 사전 학습 과제는 'pretext task'라고 합니다.
- BERT와 같은 모델은 Self-supervised learning의 한 예이다. (O)
- 해설: BERT는 Self-supervised learning 기법을 사용하여 사전 학습됩니다.
- Self-supervised learning은 고성능을 달성하기 위해 많은 레이블이 필요하다. (X)
- 해설: Self-supervised learning은 레이블이 필요하지 않지만 높은 성능을 달성할 수 있습니다.
- RoBERTa는 BERT와 달리 Next Sentence Prediction (NSP) 손실을 제거했다. (O)
- 해설: RoBERTa는 BERT와 달리 NSP 손실을 제거했습니다.
- Supervised learning은 라벨이 없는 데이터를 학습하는 기법이다. (X)
- 해설: Supervised learning은 라벨이 있는 데이터를 학습하는 기법입니다.
- Self-supervised learning은 컴퓨터 비전과 자연어 처리 모두에 적용될 수 있다. (O)
- 해설: Self-supervised learning은 컴퓨터 비전과 자연어 처리 모두에 적용될 수 있습니다.
- Self-supervised learning의 사전 학습 과제는 주로 사람의 도움 없이 자동으로 생성된다. (O)
- 해설: Self-supervised learning의 사전 학습 과제는 자동으로 생성됩니다.
- BERT의 사전 학습 데이터셋에는 BookCorpus와 영어 위키피디아가 포함된다. (O)
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사전 학습 데이터셋으로 사용합니다.
- RoBERTa는 BERT보다 더 적은 데이터셋을 사용하여 사전 학습된다. (X)
- 해설: RoBERTa는 BERT보다 더 많은 데이터셋을 사용하여 사전 학습됩니다.
빈칸 문제 (10문제)
- Self-supervised learning은 사람이 주석을 달지 않은 데이터로 __하는 유형의 학습이다. (학습)
- 해설: Self-supervised learning은 주석이 없는 데이터를 사용하여 학습합니다.
- Self-supervised learning에서 사전 학습 과제는 '__ task'라고 한다. (pretext)
- 해설: 사전 학습 과제는 'pretext task'라고 합니다.
- BERT와 같은 모델은 __ learning의 한 예이다. (Self-supervised)
- 해설: BERT는 Self-supervised learning 기법을 사용합니다.
- RoBERTa는 BERT와 달리 __ 손실을 제거했다. (Next Sentence Prediction, NSP)
- 해설: RoBERTa는 NSP 손실을 제거했습니다.
- Supervised learning은 __가 있는 데이터를 학습하는 기법이다. (라벨)
- 해설: Supervised learning은 라벨이 있는 데이터를 학습합니다.
- Self-supervised learning은 __ 비전과 자연어 처리 모두에 적용될 수 있다. (컴퓨터)
- 해설: Self-supervised learning은 컴퓨터 비전과 자연어 처리에 모두 적용됩니다.
- Self-supervised learning의 사전 학습 과제는 주로 사람의 도움 없이 __으로 생성된다. (자동)
- 해설: 사전 학습 과제는 자동으로 생성됩니다.
- BERT의 사전 학습 데이터셋에는 __와 영어 위키피디아가 포함된다. (BookCorpus)
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사용합니다.
- RoBERTa는 BERT보다 더 __ 데이터셋을 사용하여 사전 학습된다. (많은)
- 해설: RoBERTa는 더 많은 데이터셋을 사용합니다.
- Self-supervised learning에서 사전 학습 과제는 __ task라고 한다. (pretext)
- 해설: 사전 학습 과제는 'pretext task'라고 합니다.
서술형 문제 (10문제)
- Self-supervised learning이 중요한 이유를 설명하시오.
- 정답: Self-supervised learning은 라벨이 없는 대규모 데이터셋을 활용하여 모델을 학습할 수 있으며, 이는 레이블링 비용과 시간을 절약할 수 있습니다.
- 해설: Self-supervised learning은 많은 레이블이 필요하지 않아 비용 효율적이며, 다양한 응용 분야에서 높은 성능을 발휘할 수 있습니다.
- BERT와 RoBERTa의 주요 차이점을 설명하시오.
- 정답: BERT는 Next Sentence Prediction(NSP) 손실을 사용하지만, RoBERTa는 이를 제거하고 더 큰 데이터셋과 대규모 배치를 사용하여 학습합니다.
- 해설: RoBERTa는 BERT의 단점을 보완하여 더 많은 데이터와 큰 배치 크기를 사용하여 더 나은 성능을 제공합니다.
- Self-supervised learning에서 'pretext task'와 'downstream task'의 개념을 설명하시오.
- 정답: 'pretext task'는 사전 학습 단계에서 사용되는 과제이며, 'downstream task'는 사전 학습 후 미세 조정 단계에서 해결해야 할 실제 과제입니다.
- 해설: 'pretext task'는 모델이 사전 학습에서 해결하는 과제이고, 'downstream task'는 사전 학습된 모델이 실제 응용에서 해결해야 하는 과제입니다.
- Self-supervised learning이 컴퓨터 비전에서 어떻게 사용되는지 예를 들어 설명하시오.
- 정답: 컴퓨터 비전에서 Self-supervised learning은 이미지 색채화, 프레임 순서 맞추기, 이미지 완성 등의 pretext task를 사용하여 모델을 사전 학습합니다.
- 해설: Self-supervised learning은 다양한 이미지 기반 pretext task를 통해 모델을 사전 학습하고, 이를 통해 객체 인식, 객체 탐지 등의 downstream task를 수행합니다.
- BERT의 사전 학습과 Self-supervised learning의 관계를 설명하시오.
- 정답: BERT는 Self-supervised learning 기법을 사용하여 대규모 텍스트 데이터셋으로 사전 학습되며, 이를 통해 다양한 자연어 처리 과제에 높은 성능을 발휘합니다.
- 해설: BERT는 Self-supervised learning을 통해 사전 학습된 후, 특정 과제에 맞게 미세 조정됩니다.
- RoBERTa가 NSP 손실을 제거한 이유와 그 효과를 설명하시오.
- 정답: RoBERTa는 NSP 손실이 downstream task 성능에 부정적인 영향을 미친다고 판단하여 이를 제거했으며, 이로 인해 모델 성능이 향상되었습니다.
- 해설: NSP 손실 제거는 모델이 더 나은 성능을 발휘할 수 있도록 도와줍니다.
- 이거 정답이 살짝 애매해서... NSP는 두 문장을 무조건 던져줘야 되기 때문에 한 문장만 넣어도 해결할 수 있도록 하면 downstream task에 도움이 된다고 알았는데....
-
더보기
네, 질문과 정답이 다소 애매할 수 있습니다. RoBERTa가 NSP 손실을 제거한 이유와 그 효과를 좀 더 명확하고 구체적으로 설명하는 것이 좋습니다.
개선된 문제와 정답
문제:
RoBERTa가 NSP 손실을 제거한 이유와 그 효과를 설명하시오.개선된 정답:
정답: RoBERTa는 NSP 손실이 사전 학습 과정에서 모델의 복잡성을 증가시키고 효율성을 감소시킨다고 판단하여 이를 제거했습니다. 대신, 더 많은 양의 데이터와 더 긴 학습 시간을 활용하여 모델을 학습시켰습니다. 이로 인해 RoBERTa는 다양한 다운스트림 작업에서 BERT보다 우수한 성능을 보였습니다. 해설: NSP 손실 제거는 모델의 학습을 단순화하고, 더 많은 데이터와 더 긴 학습 시간으로 보완함으로써, 문맥 이해 능력을 향상시켰습니다. 이는 결국 다운스트림 작업에서 더 나은 성능을 발휘하게 했습니다.상세 설명
- NSP 손실 제거의 이유:
- 모델의 단순화: NSP 손실을 제거함으로써 모델의 복잡성을 줄이고, 학습 과정이 더 단순화되었습니다.
- 효율성 향상: NSP 없이 더 많은 데이터와 더 긴 학습 시간을 통해 모델을 학습시켜, 모델이 더 많은 문맥을 이해할 수 있도록 했습니다.
- NSP의 제한점: NSP가 모든 다운스트림 작업에서 항상 긍정적인 효과를 보이는 것은 아닙니다. NSP는 문장 간의 관계를 학습하는 데 도움이 되지만, 단일 문장의 문맥 이해를 방해할 수 있습니다.
- 효과:
- 더 나은 성능: NSP를 제거하고 대규모 데이터와 긴 학습 시간을 통해 학습한 RoBERTa는 다양한 다운스트림 작업에서 BERT보다 더 나은 성능을 보였습니다.
- 문맥 이해 향상: NSP를 제거함으로써 모델이 단일 문장의 문맥을 더 잘 이해할 수 있게 되었으며, 이는 다양한 언어 이해 작업에서 유리하게 작용했습니다.
결론
NSP 손실 제거는 RoBERTa의 학습을 단순화하고 효율성을 향상시키기 위한 결정이었습니다. 이를 대규모 데이터와 긴 학습 시간으로 보완하여, 결과적으로 RoBERTa는 다양한 다운스트림 작업에서 BERT보다 우수한 성능을 발휘하게 되었습니다. 문제와 정답을 명확히 하기 위해서는 이러한 세부 사항을 포함하는 것이 좋습니다.
- NSP 손실 제거의 이유:
- Self-supervised learning이 자연어 처리에서 어떻게 사용되는지 설명하시오.
- 정답: 자연어 처리에서 Self-supervised learning은 언어 모델링, 다음 문장 예측 등의 pretext task를 사용하여 모델을 사전 학습합니다.
- 해설: 언어 모델링과 다음 문장 예측은 모델이 언어의 문맥을 이해하는 데 도움을 줍니다.
- Self-supervised learning의 장점과 단점을 설명하시오.
- 정답: 장점은 라벨이 없는 대규모 데이터를 활용할 수 있어 비용 효율적이고 다양한 응용에 적용 가능하다는 점입니다. 단점은 사전 학습 과제와 실제 과제 간의 차이가 성능에 영향을 미칠 수 있다는 점입니다.
- 해설: Self-supervised learning은 라벨링 비용을 절감하지만, 사전 학습 과제와 실제 과제 간의 차이를 극복해야 합니다.
- RoBERTa의 대규모 배치 사용이 모델 성능에 미치는 영향을 설명하시오.
- 정답: 대규모 배치를 사용하면 최적화 속도가 빨라지고 최종 성능이 향상됩니다.
- 해설: 대규모 배치는 모델의 학습 효율성을 높이고, 더 나은 성능을 제공합니다.
- Self-supervised learning이 컴퓨터 비전과 자연어 처리 외에 다른 분야에서 어떻게 사용될 수 있는지 예를 들어 설명하시오.
- 정답: Self-supervised learning은 음성 인식, 추천 시스템, 로봇 학습 등 다양한 분야에서 활용될 수 있습니다.
- 해설: Self-supervised learning은 다양한 분야에서 레이블이 없는 데이터를 활용하여 높은 성능을 발휘할 수 있습니다.
단답형 문제 (10문제)
- Self-supervised learning이란?
- 정답: 사람이 주석을 달지 않은 데이터로 학습하는 유형의 학습
- 해설: Self-supervised learning은 라벨이 없는 데이터를 사용하여 학습합니다.
- Self-supervised learning에서 사전 학습 과제는?
- 정답: pretext task
- 해설: 사전 학습 과제는 pretext task입니다.
- BERT와 RoBERTa의 주요 차이점은?
- 정답: RoBERTa는 NSP 손실을 제거하고 더 큰 데이터셋과 배치를 사용
- 해설: RoBERTa는 NSP 손실을 제거하고 더 많은 데이터를 사용하여 학습됩니다.
- BERT의 사전 학습 데이터셋은?
- 정답: BookCorpus와 영어 위키피디아
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사용합니다.
- Self-supervised learning의 장점은?
- 정답: 라벨이 없는 데이터를 사용하여 비용 효율적임
- 해설: 라벨이 필요 없어 비용이 절감됩니다.
- RoBERTa가 NSP 손실을 제거한 이유는?
- 정답: NSP 손실이 downstream task 성능에 부정적인 영향을 미치기 때문
- 해설: NSP 손실 제거는 성능 향상을 위해서입니다.
- Self-supervised learning이 자연어 처리에서 사용되는 예는?
- 정답: 언어 모델링, 다음 문장 예측
- 해설: 언어 모델링과 다음 문장 예측은 자연어 처리에서 사용됩니다.
- RoBERTa의 대규모 배치 사용의 효과는?
- 정답: 최적화 속도가 빨라지고 최종 성능이 향상됨
- 해설: 대규모 배치는 학습 효율성을 높입니다.
- Self-supervised learning의 단점은?
- 정답: 사전 학습 과제와 실제 과제 간의 차이가 성능에 영향을 미침
- 해설: 사전 학습과 실제 과제의 차이가 문제입니다.
- Self-supervised learning이 적용될 수 있는 다른 분야는?
- 정답: 음성 인식, 추천 시스템, 로봇 학습
- 해설: 다양한 분야에서 활용될 수 있습니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 15강 - Large Language Model (0) | 2024.06.05 |
|---|---|
| 자연어 처리 14강 - Self supervised Learning 2 (0) | 2024.06.05 |
| 자연어 처리 12강 - Question Answering + BERT (0) | 2024.06.04 |
| 자연어 처리 11강 - Named Entity Recognition (NER) + BERT (2) | 2024.06.03 |
| 자연어 처리 10강 - Language Modeling with GPT (0) | 2024.06.03 |