이 단어가 회사인지, 기관인지, 나라, 시설 등 다양한 개체, 대명사, 이름 중에 무엇인지 맞추는 작업이다. 위키에 페이지로 존재하는 명사로 생각하면 편하다.

이름이 너무 길거나, 모든 이름을 포함하지 않고(Zipf's Law), 동일한 이름을 가지는 경우 모델이 제대로 파악하지 못하는(Ambiguity) 경우가 생긴다.
규칙 기반 NER
1. 높은 정밀도 rule을 통해 애매하지 않은 mentions를 라벨한다. - recall을 확보해야 한다.
2. 감지된 entities의 label 전파
3. list를 활용하여 더 식별
4. 순차적 라벨링
이 부분은 규칙 기반 Named Entity Recognition (NER)에 대한 설명입니다. NER은 텍스트에서 특정 명명된 엔티티(사람, 조직, 장소, 날짜 등)를 식별하는 작업입니다. 아래는 이미지의 내용을 더 자세히 설명한 것입니다.
Iterative Approach (반복 접근법)
- Pass 1: High-Precision Rules
- 첫 번째 단계에서는 고정밀 규칙을 사용하여 명확한 언급을 라벨링합니다.
- 여기서 '고정밀 규칙'은 매우 신뢰할 수 있는 규칙을 의미합니다. 예를 들어, 특정 형식을 가진 날짜나 명확한 고유명사 등을 라벨링할 수 있습니다.
- 이 단계에서는 라벨링된 엔티티의 수가 적을 수 있지만, 높은 정확도를 유지합니다.
- Pass 2: Propagate Labels
- 두 번째 단계에서는 이전 단계에서 감지된 명명된 엔티티의 라벨을 전파합니다.
- 전파 대상은 해당 엔티티의 부분 문자열 또는 약어가 될 수 있습니다. 예를 들어, "Barack Obama"를 라벨링했다면, 이후 "Obama"라는 언급도 같은 엔티티로 라벨링할 수 있습니다.
- Pass 3: Application-Specific Name Lists
- 세 번째 단계에서는 애플리케이션 특정 이름 목록을 사용하여 추가적인 잠재적 이름을 식별합니다.
- 여기에는 특정 도메인에서 사용되는 이름 목록이 포함될 수 있습니다. 예를 들어, 생의학 텍스트에서는 유전자나 단백질 이름이 포함될 수 있습니다.
- Pass 4: Sequence Labeling Approach
- 네 번째 단계에서는 시퀀스 라벨링 접근 방식을 사용하여 NER을 수행합니다.
- 이 단계에서는 이미 라벨링된 엔티티를 높은 정확도의 앵커로 유지합니다.
- 시퀀스 라벨링 접근 방식은 텍스트 시퀀스 전체를 고려하여 엔티티를 라벨링합니다. 이는 기계 학습 모델을 사용하여 이전 단계에서 라벨링된 엔티티를 기준으로 추가 엔티티를 식별하는 데 도움이 됩니다.
기본 아이디어
- 이 접근 방식의 기본 아이디어는 라벨 전파와 높은 정확도의 항목을 앵커로 사용하는 것입니다.
- 이러한 아이디어는 NER 외에도 다른 작업에도 유용하게 적용될 수 있습니다.
이 반복 접근법은 처음에는 명확하고 신뢰할 수 있는 엔티티만을 라벨링한 후, 점차적으로 더 많은 엔티티를 식별하여 전체 텍스트에서 엔티티를 정확하게 식별하는 방법입니다. 각 단계는 이전 단계의 결과를 기반으로 하여 점진적으로 엔티티를 라벨링합니다. 이 방법은 규칙 기반 NER의 정확성과 포괄성을 높이는 데 도움이 됩니다.

F1 score(Precision과 recall을 모두 고려)가 평가지표로 사용된다.




일반적인 RNN모델로 pretraing을 처음 적용하였다.
BERT의 pretraing
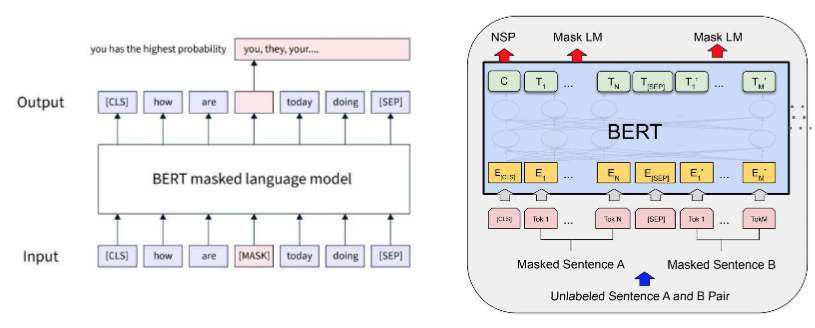
MLM (Masked Language Model) : input의 15%를 [mask] token으로 바꾸어 맞추기를 진행한다. semi-supervised로 이미 존재하는 데이터에서 정답을 만든다.

mask만 하는 것이 아니라 랜덤한 단어로 변경하기도 한다.

NSP (Next Sentence Prediction) : classification과 같은 느낌으로 이 두 문장이 이어지냐, 안 이어지냐를 맞춘다.

BERT에는 Segment Embedding이 추가된다.
CLS 토큰에서는 NSP 즉 classification이 진행된다.

Byte-Pair Encodeing(BPE)은 토큰화 방식으로 많은 모델에 사용되었다.
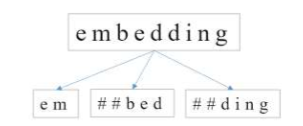
Byte Pair Encoding (BPE)와 WordPiece는 비슷한 목표를 가지고 있지만, 서로 다른 두 가지 서브워드 토큰화 방법입니다. 두 방법 모두 단어를 작은 서브워드 단위로 분할하여 희귀 단어를 더 작은 빈번한 조각으로 나타내는 데 사용됩니다. 이를 통해 언어 모델이 보다 효율적으로 단어의 의미를 학습할 수 있게 합니다.
Byte Pair Encoding (BPE)
- 원래 목적: 텍스트 데이터를 압축하기 위해 개발된 알고리즘입니다.
- 작동 방식: 가장 빈번하게 함께 등장하는 문자 쌍을 병합하여 새로운 서브워드를 생성합니다. 이 과정을 반복하여 주어진 예산(예: 최대 서브워드 개수) 내에서 모든 단어를 서브워드의 조합으로 나타냅니다.
- 특징:
- 병합 규칙이 순차적으로 적용됩니다.
- GPT, GPT-2, RoBERTa, BART, DeBERTa 등에서 사용됩니다.
- 장점:
- 자주 나타나는 서브워드를 효과적으로 캡처할 수 있습니다.
- 희귀 단어를 더 작은, 빈번한 서브워드로 분할하여 학습 효율성을 높입니다.
WordPiece
- 원래 목적: 기계 번역 시스템에서 희귀 단어 문제를 해결하기 위해 Google에서 개발되었습니다.
- 작동 방식: BPE와 유사하지만, 병합할 때마다 문자열의 가능도(likelihood)를 최대화하는 방식으로 서브워드를 생성합니다.
- 특징:
- BPE와 달리 병합 순서가 문자열의 가능도를 최대화하는 방향으로 결정됩니다.
- BERT, DistilBERT, ALBERT 등에서 사용됩니다.
- 장점:
- BPE보다 더 세밀한 서브워드 분할을 제공하여, 모델의 성능을 개선할 수 있습니다.
요약
- BPE와 WordPiece는 둘 다 서브워드 토큰화 기법입니다.
- BPE는 빈번한 문자 쌍을 병합하여 서브워드를 생성하며, 텍스트 압축 알고리즘에서 기원했습니다.
- WordPiece는 BPE와 유사한 방식으로 서브워드를 생성하지만, 문자열 가능도를 최대화하는 방식으로 병합 순서를 결정합니다.
- BPE는 GPT, GPT-2, RoBERTa와 같은 모델에서 사용되며, WordPiece는 BERT, DistilBERT, ALBERT 등에서 사용됩니다.
따라서, BPE는 WordPiece와 유사한 서브워드 토큰화 방법이지만, 두 방법은 서로 다른 알고리즘을 사용합니다.
BERT 또한 다양한 파인튜닝을 사용하여 여러 분야에 특화되었다.
Named Entity Recognition (NER)
- 태스크: 특정 명명된 엔티티(사람, 조직, 장소, 날짜 등)의 언급을 식별하는 작업
- 태그: 여러 새로운 태그 정의
- B-PERS, B-DATE: 사람/날짜 언급의 시작
- I-PERS, I-DATE: 사람/날짜 언급의 내부
- 기타 도메인: 생물 의학 텍스트는 다른 유형(단백질, 유전자, 질병 등)을 요구
NER을 위한 특징
- 공통 이름 목록: 여러 엔티티에 대한 공통 이름 목록이 존재
- 지명, 성명, 유전자, 단백질, 질병, 회사 이름 등
- 제약 사항:
- Zipf의 법칙: 목록이 완전하지 않음
- 모호성: 동일 이름이 다른 엔티티를 지칭할 수 있음
규칙 기반 NER
- 교재 예제: 텍스트에 여러 번 패스를 하는 반복 접근 방식
- 1차: 높은 정밀도의 규칙을 사용하여 명확한 언급을 라벨링
- 2차: 이미 감지된 엔티티의 라벨을 전파
- 3차: 애플리케이션 특정 이름 목록을 사용하여 추가 엔티티 식별
- 4차: 시퀀스 라벨링 접근 방식을 사용하여 NER 수행
신경망 기반 NER
- 모델: CRF 출력 레이어가 있는 Sequence RNN (biLSTM 또는 Transformer)
- 입력: 단어 임베딩, 문자 임베딩 및 기타 특징
NER 성능 평가
- 평가 지표: 엔티티별로 평가되는 F1 점수 사용
이전의 사전 학습된 언어 표현 모델
- ELMo: Bi-LSTM 구조로 양방향으로 정보 처리
- ELMo vs BERT: ELMo는 임베딩을 단순히 연결하기 때문에 진정한 양방향성을 고려하기 어렵다
GPT vs BERT
- GPT: 단방향 self-attention 사용
- BERT: 양방향 모델로, 두 가지 학습 목표 설정
- Masked Language Model (MLM): 입력 시퀀스의 15% 단어를 마스크하여 예측
- Next Sentence Prediction (NSP): 문장 쌍이 순차적인지 여부를 예측
BERT의 입력 표현
- Wordpiece
임베딩: 단어 임베딩 대신 Wordpiece임베딩사용. 뭐야 돼 임베딩이야 토크나이저지 - 포지션 임베딩: Transformer와 유사한 위치 임베딩 사용
- [CLS] 토큰: 분류 작업에 사용되는 특별한 분류 토큰
- 세그먼트 임베딩: 두 개의 문장을 구분하는 임베딩 사용
Byte-Pair Encoding (BPE)
- BPE: 텍스트 압축 알고리즘으로 개발되었으며, GPT 모델을 사전 학습할 때 사용
- 다중 언어 적용: BERT는 약 30,000개의 Wordpiece 토큰 사용
BERT의 사전 학습 및 파인 튜닝
- 사전 학습: Book Corpus와 English Wikipedia를 사용
- 파인 튜닝: [CLS] 토큰에 소프트맥스 레이어를 붙여 분류 작업 수행
실험
- GLUE 데이터셋: 일반 언어 이해 평가
- SQuAD 데이터셋: 질문 응답 작업
- Ablation Study: 사전 학습, 모델 크기, 마스킹, 양방향 vs 단방향 비교
이 요약을 통해 Named Entity Recognition (NER) 및 BERT와 관련된 주요 개념, 방법론 및 실험 결과에 대해 이해할 수 있습니다. BERT의 사전 학습 및 파인 튜닝 방법론과 NER의 평가 방법, GPT와의 비교도 다루고 있습니다.
O, X 문제 (10문제)
- BERT는 양방향 자기 주의를 사용하여 문맥을 이해한다. (O)
- 해설: BERT는 양방향 자기 주의를 사용하여 문맥의 양쪽을 동시에 이해합니다.
- Named Entity Recognition(NER)은 단어 단위의 토큰을 예측하는 작업이다. (X)
- 해설: NER은 명명된 엔티티(예: 사람, 장소, 조직)를 식별하는 작업입니다.
- BERT의 사전 훈련에는 BookCorpus와 영어 위키피디아가 사용되었다. (O)
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사전 훈련 데이터셋으로 사용합니다.
- GPT는 BERT와 마찬가지로 양방향 자기 주의를 사용한다. (X)
- 해설: GPT는 단방향 자기 주의를 사용합니다.
- BERT의 학습 목표 중 하나는 마스크된 언어 모델(Masked Language Model, MLM)이다. (O)
- 해설: BERT는 입력 시퀀스의 일부 단어를 마스킹하고, 이 마스킹된 단어를 예측하는 작업을 포함합니다.
- BERT의 입력 토큰은 WordPiece 모델을 사용하여 표현된다. (O)
- 해설: BERT는 WordPiece 토큰을 사용하여 단어를 표현합니다.
- F1 점수는 NER 모델의 성능을 평가하는 주요 지표이다. (O)
- 해설: F1 점수는 NER 모델의 성능을 평가하는 데 사용됩니다.
- BERT는 문장 간의 관계를 이해하기 위해 다음 문장 예측(NSP) 작업을 포함한다. (O)
- 해설: BERT는 다음 문장 예측 작업을 통해 문장 간의 관계를 학습합니다.
- 규칙 기반 NER은 여러 번의 텍스트 패스를 통해 명명된 엔티티를 식별한다. (O)
- 해설: 규칙 기반 NER은 여러 번의 텍스트 패스를 통해 엔티티를 식별합니다.
- BERT는 트랜스포머 디코더를 사용하여 문장을 이해한다. (X)
- 해설: BERT는 트랜스포머 인코더를 사용합니다.
빈칸 문제 (10문제)
- Named Entity Recognition(NER)은 __, __, __, __ 등의 엔티티를 식별하는 작업이다. (사람, 조직, 장소, 날짜)
- 해설: NER은 사람, 조직, 장소, 날짜 등의 엔티티를 식별합니다.
- BERT는 입력 시퀀스의 일부 단어를 __으로 마스킹하고, 이를 예측하는 작업을 수행한다. ([MASK] 토큰)
- 해설: BERT는 [MASK] 토큰으로 단어를 마스킹합니다.
- BERT의 사전 훈련 데이터셋으로 사용된 두 가지 주요 소스는 __와 __이다. (BookCorpus, 영어 위키피디아)
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사용합니다.
- F1 점수는 NER 모델의 __와 __의 조화를 평가하는 지표이다. (정밀도, 재현율)
- 해설: F1 점수는 정밀도와 재현율의 조화를 평가합니다.
- BERT는 문장 간의 관계를 이해하기 위해 __ 작업을 포함한다. (다음 문장 예측)
- 해설: BERT는 다음 문장 예측 작업을 포함합니다.
- 읭 예측이 아니라 맞는지 확인하는거 아닌가..? 번역 상 애매한 걸로 합시다... NSP!
-
더보기
네, 이 문제는 맞습니다. BERT는 문장 간의 관계를 이해하기 위해 다음 문장 예측(Next Sentence Prediction, NSP) 작업을 포함합니다. 이 작업은 BERT의 사전 학습(Pre-training) 단계에서 중요한 구성 요소 중 하나입니다.
BERT의 다음 문장 예측(Next Sentence Prediction, NSP)
BERT(Bidirectional Encoder Representations from Transformers)는 다음 두 가지 주요 목표를 가지고 사전 학습됩니다:
- 마스킹 언어 모델(Masked Language Model, MLM): 문장에서 일부 토큰을 마스킹하고, 이 마스킹된 토큰들을 예측합니다.
- 다음 문장 예측(Next Sentence Prediction, NSP): 두 개의 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지 여부를 예측합니다.
다음 문장 예측(NSP)의 역할
NSP 작업은 BERT가 문장 간의 관계를 학습하도록 돕습니다. 이는 문장 간의 연속성과 문맥을 이해하는 데 중요한 역할을 합니다.
NSP의 학습 과정
- 입력 데이터: 두 개의 문장 쌍이 입력으로 주어집니다. 입력 문장 쌍은 실제 연속된 문장일 수도 있고, 무작위로 선택된 비연속 문장일 수도 있습니다.
- 목표: 모델은 두 번째 문장이 첫 번째 문장의 다음 문장인지 여부를 예측합니다.
- 레이블: 연속된 문장은 True(1)로, 비연속 문장은 False(0)로 레이블링됩니다.
BERT의 사전 학습 단계
- 마스킹 언어 모델(MLM):
- 입력 문장의 일부 토큰을 무작위로 마스킹하고, 모델이 이 마스킹된 토큰을 예측하도록 학습합니다.
- 다음 문장 예측(NSP):
- 두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음 문장인지를 예측하도록 모델을 학습합니다.
문제와 해설
BERT는 문장 간의 관계를 이해하기 위해 __ 작업을 포함한다. (다음 문장 예측) 해설: BERT는 다음 문장 예측 작업을 포함합니다.이 문제와 해설은 정확합니다. BERT는 문장 간의 관계를 이해하기 위해 다음 문장 예측(NSP) 작업을 포함합니다. 이는 BERT의 사전 학습 단계에서 중요한 구성 요소로, 문맥과 연속성을 학습하는 데 도움을 줍니다.
- BERT는 __ 모델을 사용하여 단어를 서브워드 단위로 분할하여 표현한다. (WordPiece)
- 해설: BERT는 WordPiece 모델을 사용합니다.
- BERT의 입력 토큰에는 문장 구분을 위한 __ 토큰이 포함된다. ([SEP])
- 해설: BERT의 입력 토큰에는 [SEP] 토큰이 포함됩니다.
- 규칙 기반 NER의 첫 번째 패스는 __ 규칙을 사용하여 모호하지 않은 엔티티를 라벨링한다. (정밀도가 높은)
- 해설: 첫 번째 패스는 정밀도가 높은 규칙을 사용합니다.
- NER 모델의 성능을 평가하는 주요 지표는 __ 점수이다. (F1)
- 해설: F1 점수는 NER 모델의 성능 평가에 사용됩니다.
- BERT는 문장의 처음에 __ 토큰을 사용하여 분류 작업을 수행한다. ([CLS])
- 해설: BERT는 [CLS] 토큰을 사용하여 분류 작업을 수행합니다.
서술형 문제 (10문제)
- Named Entity Recognition(NER)이 중요한 이유를 설명하시오.
- 정답: NER은 사람, 조직, 장소 등의 엔티티를 자동으로 식별하여 정보 검색, 질문 응답, 문서 요약 등 다양한 자연어 처리 응용에 필수적인 역할을 합니다.
- 해설: NER은 중요한 정보를 식별하고 이를 구조화된 데이터로 변환하여 다양한 응용에서 중요한 역할을 합니다.
- BERT의 사전 훈련과 미세 조정 절차를 설명하시오.
- 정답: BERT는 대규모 텍스트 데이터로 사전 훈련을 수행한 후, 특정 작업에 맞게 미세 조정을 통해 최적화됩니다. 사전 훈련에는 마스크된 언어 모델과 다음 문장 예측이 포함됩니다.
- 해설: 사전 훈련 단계에서 BERT는 대규모 데이터셋으로 언어 모델을 학습하며, 미세 조정 단계에서는 특정 NLP 작업에 맞게 모델을 최적화합니다.
- F1 점수가 NER 모델 평가에 중요한 이유를 설명하시오.
- 정답: F1 점수는 정밀도와 재현율의 조화 평균으로, NER 모델의 정확성과 완전성을 동시에 평가할 수 있는 지표입니다.
- 해설: 정밀도와 재현율을 균형 있게 평가하는 F1 점수는 NER 모델의 전반적인 성능을 잘 반영합니다.
- BERT와 GPT의 주요 차이점을 설명하시오.
- 정답: BERT는 양방향 트랜스포머 인코더를 사용하여 문맥의 양쪽을 모두 이해하며, GPT는 단방향 트랜스포머 디코더를 사용하여 앞쪽 문맥만을 이해합니다.
- 해설: BERT는 양방향 문맥을 고려하는 반면, GPT는 단방향 문맥을 사용하여 다음 단어를 예측합니다.
- BERT의 입력 형식을 설명하시오.
- 정답: BERT의 입력 형식은 WordPiece 토큰으로 분할된 단어와 위치 임베딩, 문장 구분을 위한 [SEP] 토큰, 분류를 위한 [CLS] 토큰을 포함합니다.
- 해설: BERT는 복합적인 입력 형식을 사용하여 다양한 NLP 작업에 적합하게 설계되었습니다.
- NER에서 BIO 태그 체계의 역할을 설명하시오.
- 정답: BIO 태그 체계는 엔티티의 시작(B), 내부(I), 외부(O)를 태그로 표시하여 문장 내 엔티티의 위치와 범위를 명확히 합니다.
- 해설: BIO 태그는 엔티티 식별을 체계적으로 수행할 수 있도록 돕습니다.
- BERT의 마스크된 언어 모델(Masked Language Model, MLM) 작업을 설명하시오.
- 정답: MLM 작업에서는 입력 시퀀스의 일부 단어를 [MASK] 토큰으로 대체하고, 모델이 이 마스킹된 단어를 예측하도록 학습합니다.
- 해설: MLM은 BERT가 단어의 문맥을 학습하는 데 중요한 역할을 합니다.
- 규칙 기반 NER의 한계점과 이를 보완하는 방법을 설명하시오.
- 정답: 규칙 기반 NER은 정밀도가 높은 반면, 커버리지가 낮아 새로운 엔티티를 식별하는 데 한계가 있습니다. 이를 보완하기 위해 사전 학습된 언어 모델과 같은 기계 학습 방법을 사용할 수 있습니다.
- 해설: 기계 학습 방법은 규칙 기반 접근법의 한계를 보완하여 더 높은 커버리지와 유연성을 제공합니다.
- BERT의 다음 문장 예측(Next Sentence Prediction, NSP) 작업의 목적을 설명하시오.
- 정답: NSP 작업의 목적은 두 문장이 연속되는지 여부를 예측하여 문장 간의 관계를 이해하는 데 도움을 주는 것입니다.
- 해설: NSP는 문장 간의 일관성과 연결성을 학습하여 다양한 NLP 작업에서 유용합니다.
- BERT가 NER 작업을 수행하는 방법을 설명하시오.
- 정답: BERT는 입력 시퀀스를 처리하여 각 토큰의 벡터 표현을 생성하고, 이를 기반으로 각 토큰이 특정 엔티티에 속하는지 여부를 예측합니다.
- 해설: BERT는 각 토큰에 대한 예측을 통해 NER 작업을 수행합니다.
단답형 문제 (10문제)
- Named Entity Recognition(NER)이란?
- 정답: 사람, 조직, 장소 등의 엔티티를 식별하는 작업
- 해설: NER은 문장에서 명명된 엔티티를 자동으로 식별하는 작업입니다.
- BERT의 사전 훈련 데이터셋은?
- 정답: BookCorpus와 영어 위키피디아
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사용하여 사전 훈련되었습니다.
- BERT의 입력 토큰은 무엇을 사용하는가?
- 정답: WordPiece 모델
- 해설: BERT는 WordPiece 모델을 사용하여 단어를 서브워드 단위로 분할합니다.
- BERT의 주요 학습 목표는?
- 정답: 마스크된 언어 모델(Masked Language Model)과 다음 문장 예측(Next Sentence Prediction)
- 해설: BERT는 두 가지 주요 학습 목표를 가지고 있습니다.
- NER 모델의 주요 평가 지표는?
- 정답: F1 점수
- 해설: F1 점수는 NER 모델의 성능을 평가하는 데 사용됩니다.
- BERT의 입력 형식에서 문장 구분 토큰은?
- 정답: [SEP]
- 해설: [SEP] 토큰은 문장을 구분하는 데 사용됩니다.
- BERT의 첫 번째 입력 토큰은?
- 정답: [CLS]
- 해설: [CLS] 토큰은 분류 작업을 위한 첫 번째 입력 토큰입니다.
- 규칙 기반 NER의 첫 번째 패스는 어떤 규칙을 사용하는가?
- 정답: 정밀도가 높은 규칙
- 해설: 첫 번째 패스는 정밀도가 높은 규칙을 사용하여 모호하지 않은 엔티티를 라벨링합니다.
- BERT는 어떤 구조를 사용하여 문맥을 이해하는가?
- 정답: 양방향 트랜스포머 인코더
- 해설: BERT는 양방향 트랜스포머 인코더를 사용합니다.
- BERT의 사전 훈련 작업에는 몇 퍼센트의 단어가 마스킹되는가?
- 정답: 15%
- 해설: BERT는 입력 시퀀스의 15%의 단어를 마스킹합니다.
O, X 문제 (10문제)
- BERT는 트랜스포머 인코더 구조를 사용한다. (O)
- 해설: BERT는 트랜스포머 인코더 구조를 사용하여 문맥을 이해합니다.
- Named Entity Recognition(NER)은 문서 내 모든 단어를 태그하는 작업이다. (X)
- 해설: NER은 문서 내 모든 단어가 아닌 명명된 엔티티(사람, 장소, 조직 등)를 식별합니다.
- BERT의 학습 목표 중 하나는 다음 단어 예측이다. (X)
- 해설: BERT는 다음 단어 예측이 아닌 마스크된 언어 모델과 다음 문장 예측 작업을 포함합니다.
- BERT는 입력 시퀀스의 15%를 무작위로 선택하여 마스킹한다. (O)
- 해설: BERT는 입력 시퀀스의 15%를 마스킹하여 예측합니다.
- BERT의 사전 훈련에는 위키피디아가 사용되지 않는다. (X)
- 해설: BERT의 사전 훈련 데이터셋으로 영어 위키피디아가 사용됩니다.
- NER에서 BIO 태그 체계는 엔티티의 시작, 내부, 외부를 태그로 표시한다. (O)
- 해설: BIO 태그 체계는 엔티티의 위치와 범위를 표시합니다.
- F1 점수는 NER 모델의 성능을 평가하는 데 사용되지 않는다. (X)
- 해설: F1 점수는 NER 모델의 성능을 평가하는 주요 지표입니다.
- BERT는 단어 임베딩 대신 서브워드 임베딩을 사용한다. (O)
- 해설: BERT는 WordPiece 모델을 사용하여 서브워드 단위로 단어를 표현합니다.
- 규칙 기반 NER은 사전 정의된 규칙을 사용하여 엔티티를 식별한다. (O)
- 해설: 규칙 기반 NER은 사전 정의된 규칙을 사용합니다.
- BERT의 다음 문장 예측 작업은 두 문장이 논리적으로 연결되는지를 예측한다. (O)
- 해설: BERT의 NSP 작업은 두 문장이 연결되는지 여부를 예측합니다.
빈칸 문제 (10문제)
- BERT는 __ 구조를 사용하여 문맥을 양방향으로 이해한다. (트랜스포머 인코더)
- 해설: BERT는 트랜스포머 인코더 구조를 사용합니다.
- NER은 __, __, __ 등을 식별하는 작업이다. (사람, 장소, 조직)
- 해설: NER은 사람, 장소, 조직 등의 엔티티를 식별합니다.
- BERT의 주요 학습 목표 중 하나는 __ 언어 모델이다. (마스크된)
- 해설: BERT는 마스크된 언어 모델 작업을 포함합니다.
- BERT는 입력 시퀀스의 __%를 마스킹하여 예측한다. (15)
- 해설: BERT는 입력 시퀀스의 15%를 마스킹합니다.
- BERT의 사전 훈련 데이터셋으로 사용된 주요 소스는 __와 __이다. (BookCorpus, 영어 위키피디아)
- 해설: BERT는 BookCorpus와 영어 위키피디아를 사용합니다.
- NER에서 F1 점수는 __와 __의 조화를 평가하는 지표이다. (정밀도, 재현율)
- 해설: F1 점수는 정밀도와 재현율의 조화를 평가합니다.
- BERT는 __ 모델을 사용하여 단어를 서브워드 단위로 분할한다. (WordPiece)
- 해설: BERT는 WordPiece 모델을 사용합니다.
- BERT의 입력 토큰에는 문장 구분을 위한 __ 토큰이 포함된다. ([SEP])
- 해설: [SEP] 토큰은 문장 구분을 위한 토큰입니다.
- 규칙 기반 NER의 첫 번째 패스는 __ 규칙을 사용하여 모호하지 않은 엔티티를 라벨링한다. (정밀도가 높은)
- 해설: 첫 번째 패스는 정밀도가 높은 규칙을 사용합니다.
- BERT의 첫 번째 입력 토큰은 __ 토큰이다. ([CLS])
- 해설: [CLS] 토큰은 BERT의 첫 번째 입력 토큰입니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 13강 - Self Supervised Learning 1 (1) | 2024.06.04 |
|---|---|
| 자연어 처리 12강 - Question Answering + BERT (0) | 2024.06.04 |
| 자연어 처리 10강 - Language Modeling with GPT (0) | 2024.06.03 |
| NLP Python - BERT for Question Answering, Tokenizer, Evaluate(f1 score) (32) | 2024.05.22 |
| 한->영 번역기 만들기 python 실습 - seq2seq, LSTM, GRU, BLEU score (0) | 2024.05.05 |