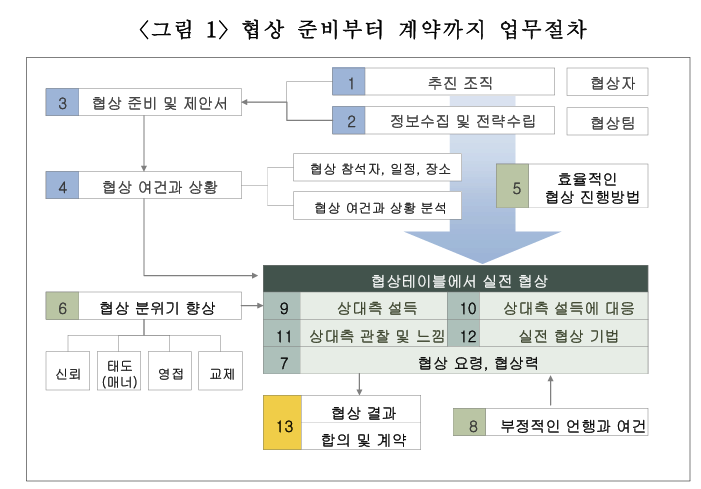
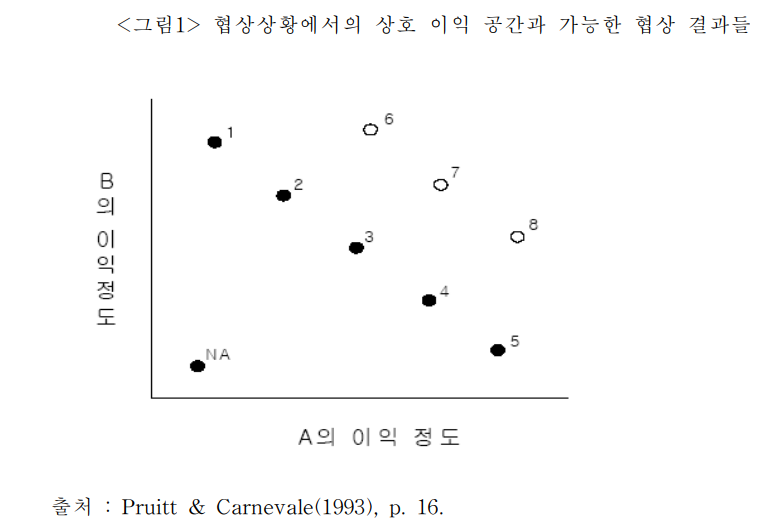
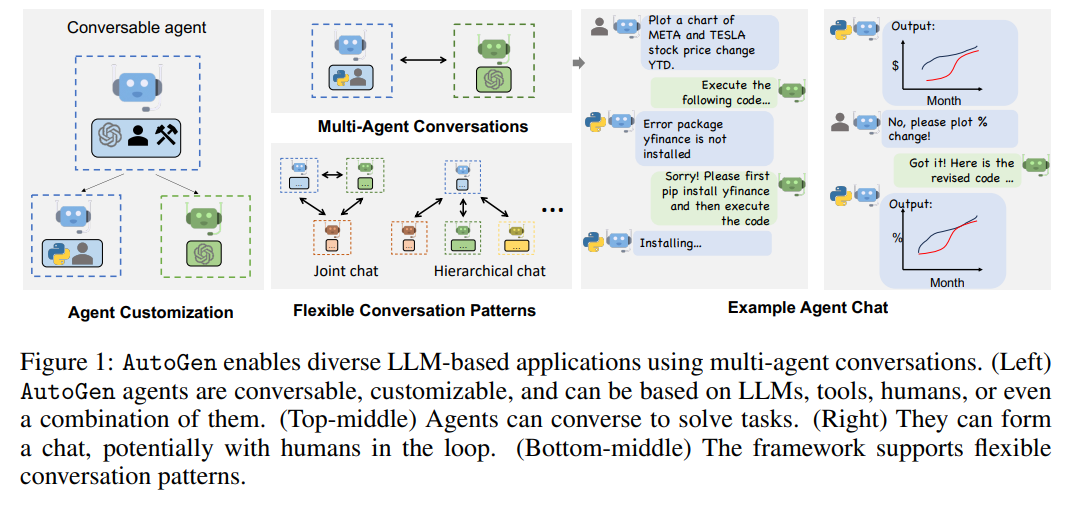
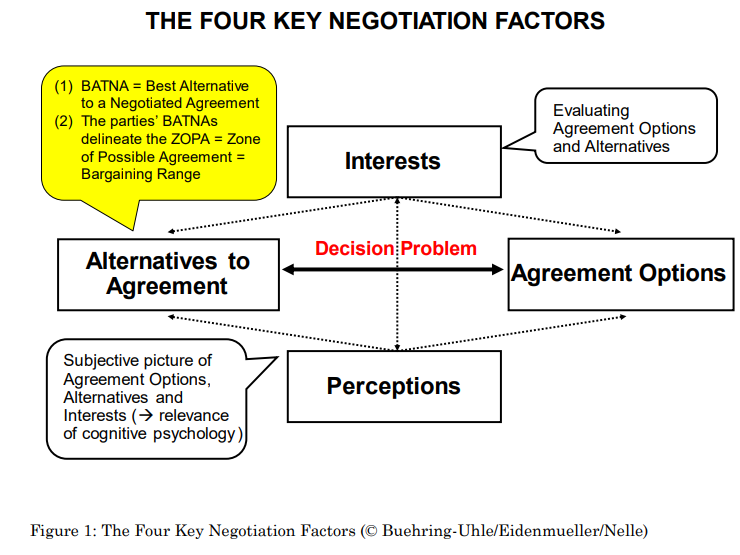
https://www.riss.kr/search/detail/DetailView.do?p_mat_type=be54d9b8bc7cdb09&control_no=abbf7a1b5e724473ffe0bdc3ef48d419&outLink=K https://www.riss.kr/search/detail/DetailView.do?control_no=abbf7a1b5e724473ffe0bdc3ef48d419&outLink=K&p_mat_type=be54d9b8bc7cdb09 www.riss.kr 이 논문은 협상 성과에 영향을 미치는 구체적인 기술을 체계적으로 분석하며, 협상은 철저한 준비와 전략 수립, 논리적 설득, 감정 관리로 구성된 복합적인 과정임을 강조한다.협상 기술은 사전 정보 수집, 문화적 이해, 신뢰 구축을..