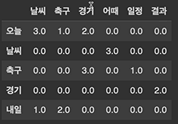
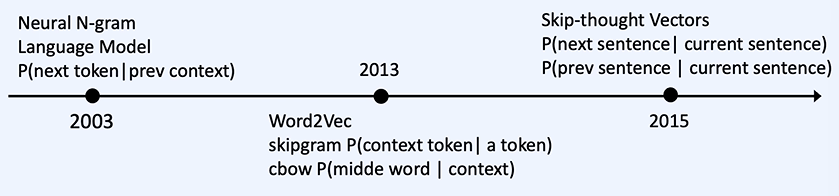
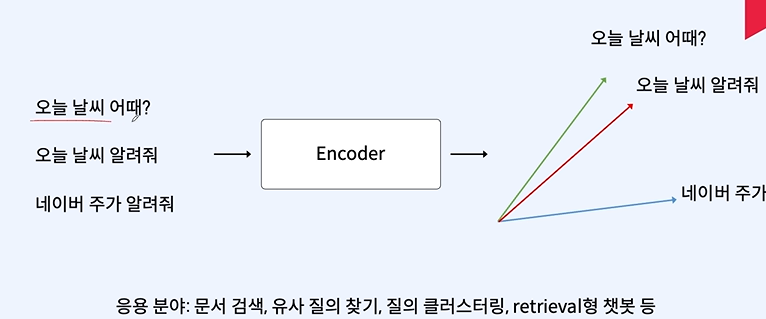
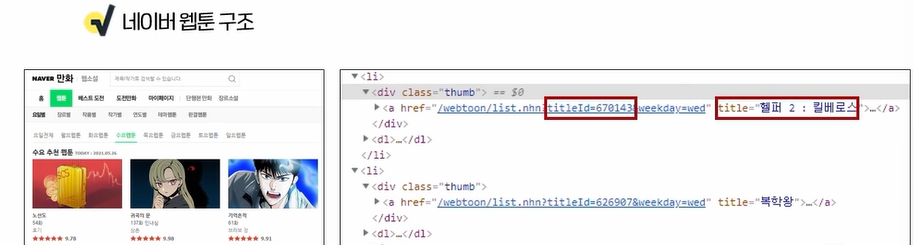
목표 - 다양한 자연어 처리 Task들에 대한 목적과 수행 방법을 이해할 수 있다. text classification - 긍정 부정 분류 정보 추출 문장 변환 및 생성 품사 분류 및 관계 토픽, 키워드 추출 챗봇 자연어 추론 어뷰징 디텍션 - 위험한 말들을 분류(선정성, 공격성 등) 유사도 - 얼마나 유사한 번역, 요약, 생성(이루다) 추출요약 - 기계적 방식으로 요약 -> 원문에서 중요한 문장을 뽑기 추상요약 - 문장을 사람이 요약하듯 요약 -> 문장 전체를 원문에 없는 문장으로 만들기 사람이 작성한 것 같은 텍스트!!!!!! chat GPT나 이루다가 여기에 포함 엔티티는 명사와는 다르다. 개체명 인식 -> 엔티티 구별 둘 이상의 엔티티에서 발생한다. 종속 관계가 나온다! 추상 요약과 추출 요약 중..