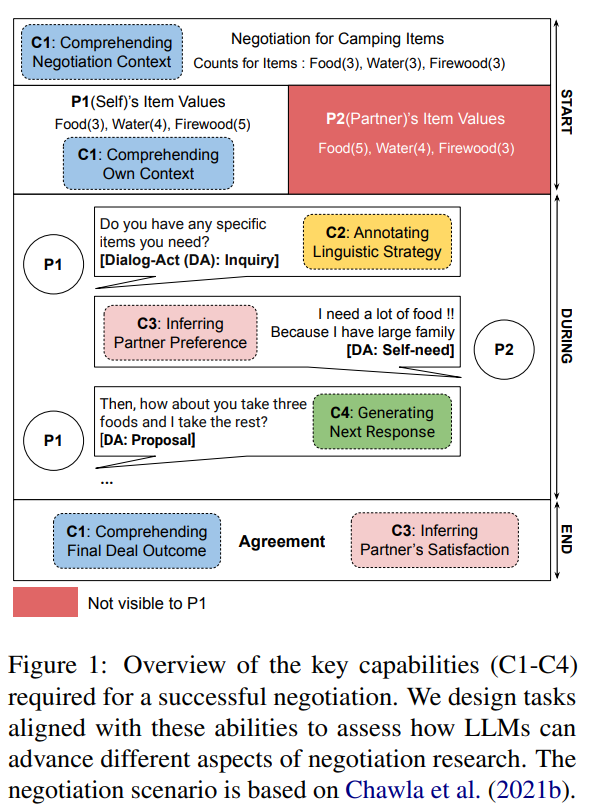
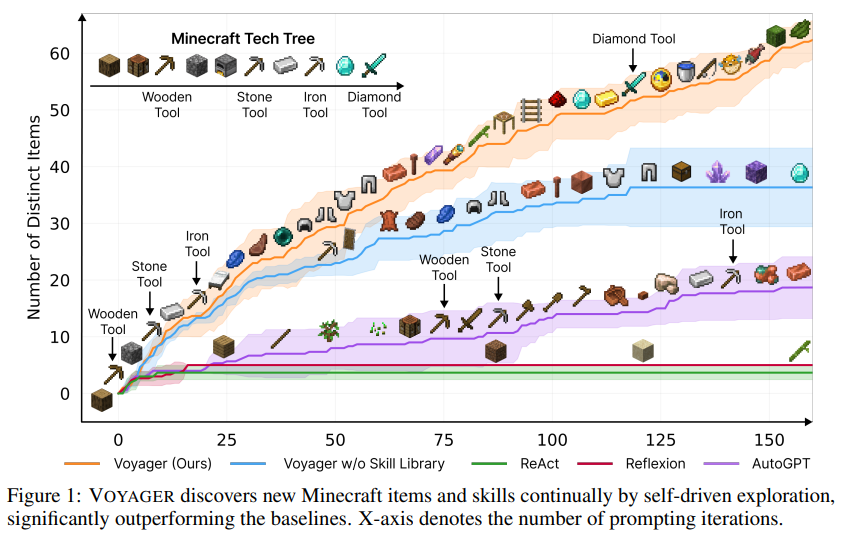
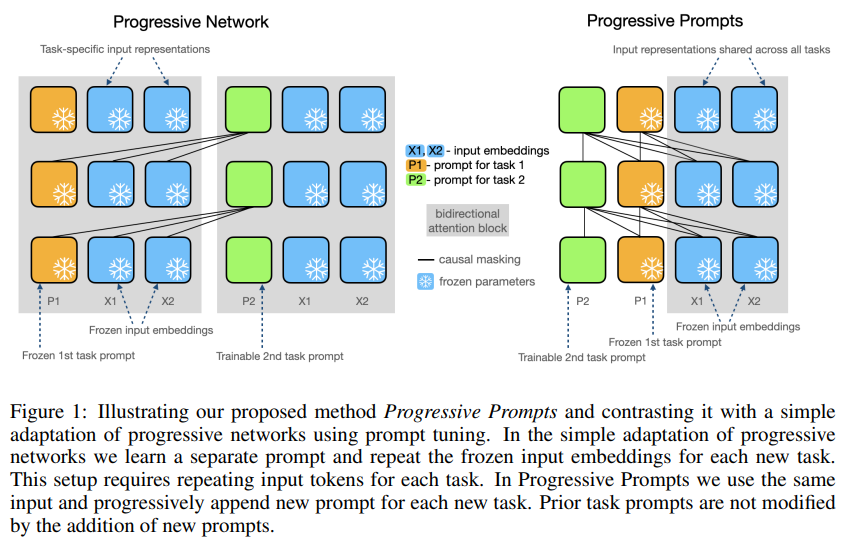
https://arxiv.org/abs/2310.05029 Walking Down the Memory Maze: Beyond Context Limit through Interactive ReadingLarge language models (LLMs) have advanced in large strides due to the effectiveness of the self-attention mechanism that processes and compares all tokens at once. However, this mechanism comes with a fundamental issue -- the predetermined context windowarxiv.org 이 논문은 트리 구조를 통해 짧게 요약해..