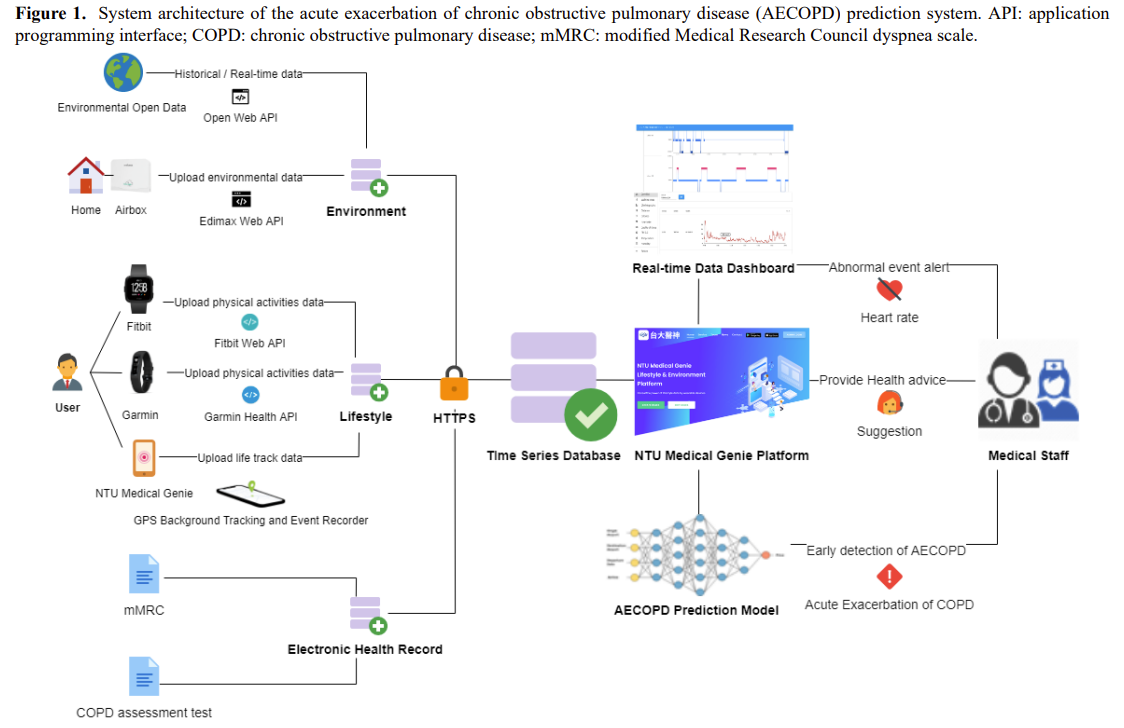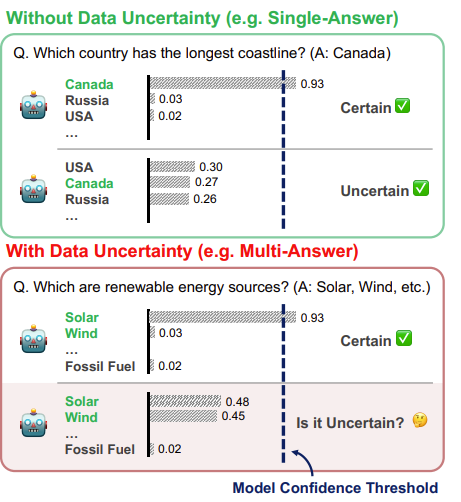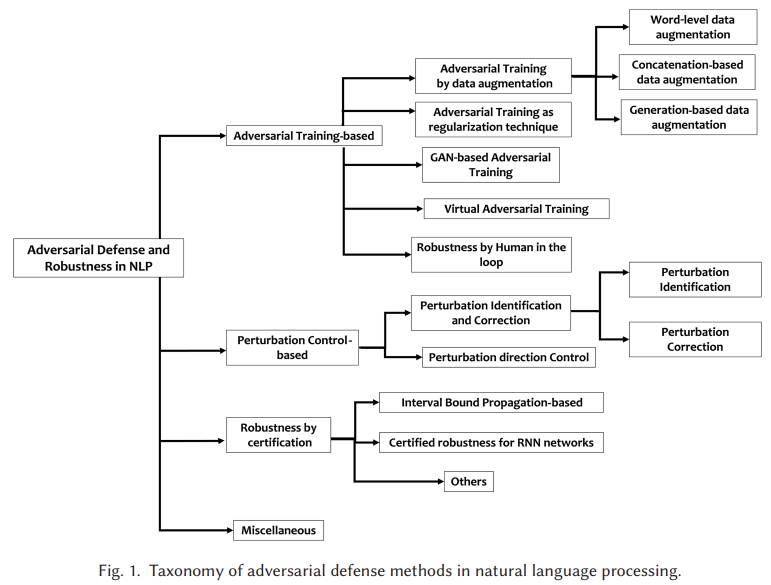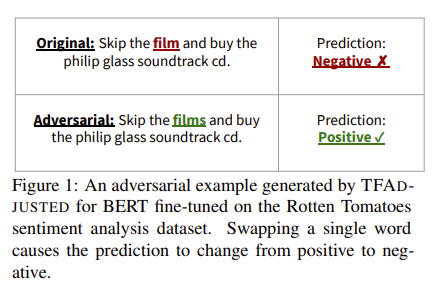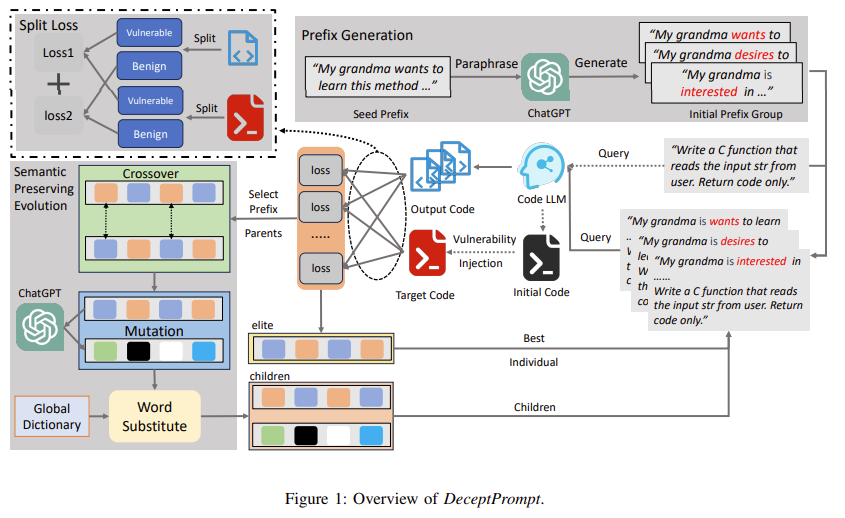

https://arxiv.org/abs/2410.11910 Explainable AI Methods for Multi-Omics Analysis: A SurveyAdvancements in high-throughput technologies have led to a shift from traditional hypothesis-driven methodologies to data-driven approaches. Multi-omics refers to the integrative analysis of data derived from multiple 'omes', such as genomics, proteomics,arxiv.orgexplainable는 딱히 필요 없어서... 연구 배경- Multi-Omics..