https://www.semanticscholar.org/paper/A-Survey-of-Adversarial-Defenses-and-Robustness-in-Goyal-Doddapaneni/83cebf919635504786fc220d569284842b0f0a09
www.semanticscholar.org
서베이 논문은 너무 길어서 적당히 보고 넘어 가는 것으로...
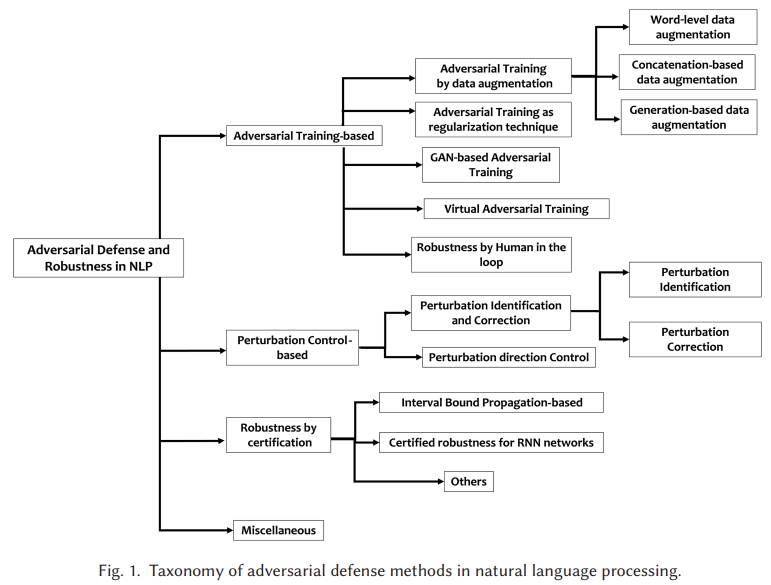
방어 방법에 대한 논문이었습니다
- 학습 - 데이터 증강, 정규화, GAN, VAT, HITL
- Control - 탐지 및 보정, 임베딩 방향 제어
- Certification - IBP, RNN 인증, Transformer 인증, Randomized sommthing
- 기타 - Bias 제거, Embedding 기반, Backdoor 방어
| 목표 | NLP 딥러닝 모델이 적대적 공격에 취약함을 인식하고, 다양한 방어 전략들을 체계적으로 정리 및 분류 |
| 핵심 문제 | - NLP 모델은 작은 입력 변화에도 민감 - discrete한 언어의 특성상 adversarial example 생성과 방어가 CV보다 복잡함 |
| 기여 (Contribution) | ✅ 방어 전략 중심 최초의 종합적 서베이 ✅ 새로운 4단계 분류 체계 제안 ✅ 전략별 세부 방법·성능·적용 과제 정리 ✅ 방어 성능 평가 지표 및 데이터셋/툴킷 총망라 |
| 방어 분류 체계 (Taxonomy) | ① Adversarial Training ② Perturbation Control ③ Certification ④ Miscellaneous |
| 주요 방법론 요약 | ① Adversarial Training: 공격 예제 학습으로 내성 강화 - 데이터 증강: TextBugger, AddSent - 정규화: FreeLB, InfoBERT - GAN: LexicalAT - VAT: ALUM, TAVAT - Human-in-the-Loop: ANLI, QuizBowl ② Perturbation Control: 탐지/수정/방향 제약 - 탐지: SEM, DNE, RS&V - 수정: ScRNN, BERT-Defense - 방향 제어: CBOW 방향 제한 ③ Certification: perturbation에 안전한 입력 범위 수학적으로 보장 - IBP 기반: Jia et al., SAFER - RNN 인증: POPQORN, Cert-RNN - Transformer 인증: DeepT, PROVER - Randomized Smoothing: RanMASK ④ 기타: Typo 방어(RobEn), 편향 제거, Backdoor 대응 |
| 적용 NLP 태스크 | - Text Classification (Sentiment, Topic, Hate 등) - NLI, QA, NER, Machine Translation - Dialogue Generation, Paraphrase Detection |
| 평가 지표 | Accuracy, Loss, BLEU, ASR, Certified Accuracy, CLEVER Score, Certified Radius 등 20+ 개 |
| 사용된 데이터셋 & 툴킷 | - Dataset: ANLI, PAWS, Adversarial SQuAD, TCAB 등 - Toolkit: TextAttack, OpenAttack, Quizbowl |
| 결론 (Insight) | - Adversarial Training이 효과적이지만 특정 공격에 과적합 - Certification은 이론적 강점 있으나 확장성 부족 - Perturbation Control은 해석력 높지만 자동화 어려움 - 다양한 전략 병합 및 태스크 전반의 일반화 필요 |
| 한계점 | - 방어 기법 대부분이 특정 공격에 국한 - 텍스트 분류 중심으로 연구 편향 - 대형 Transformer 적용 어려움 - 실제 자연스러운 perturbation 생성·탐지 어려움 |
https://www.semanticscholar.org/paper/Adversarial-Attacks-on-Deep-learning-Models-in-Zhang-Sheng/88338c58701f34503c7af77e34f19d9a5cd66313
www.semanticscholar.org
이건 공격 방법, 방어 방법 모두 나와있는 survey 논문입니다.

| 연구 목적 | NLP 딥러닝 모델의 적대적 공격 기법을 체계적으로 분류·분석하고, 공격 기법의 특성과 방어 전략을 종합적으로 정리 |
| 배경 문제 | 딥러닝 모델은 강력한 표현력을 가졌지만, 작은 입력 변화(적대적 예제)에 매우 취약함 → 특히 NLP에서는 discrete 특성과 의미 변화 위험성 때문에 공격·방어가 더 어려움 |
| 공격 정의 | 모델의 입력 에 작은 perturbation η를 더한 x′=x+η가 출력 f(x′)≠f(x)을 유도하도록 만드는 것 ※ 목표: 오분류 유도 (untargeted) 또는 특정 클래스 강제 예측 (targeted) |
| 공격 분류 체계 | ✅ 모델 접근: White-box / Black-box ✅ 목표 타입: Targeted / Untargeted ✅ 의미 단위: Character / Word / Sentence / Embedding ✅ 응용 분야: Text Classification, QA, Translation 등 ✅ 대상 모델: CNN, RNN, Transformer, Reinforcement 등 |
| 주요 공격 기법 | 🔹 FGSM, JSMA, C&W, HotFlip (white-box) 🔹 AddSent, DeepWordBug, Genetic, GAN-based, SCPNs (black-box) 🔹 Word-level 교체, 문법 오류 삽입, 의미 보존 paraphrasing 등 |
| 멀티모달 공격 | OCR, STR, Captioning, VQA, Speech-to-Text 등 이미지/음성 기반 NLP 작업에 대한 교차 모달 공격도 분석 |
| 방어 전략 | 🛡 Adversarial Training: 적대적 예제로 학습 데이터 증강 🛡 Regularization: embedding space에서 perturbation 규제 🛡 Knowledge Distillation: soft-label로 지식 전이 🛡 Robust Optimization: min-max 기반 강건 학습 |
| 핵심 결과 | ⚠ 대부분의 NLP DNN이 적대적 예제에 취약 ⚠ CV에 비해 NLP에서는 가시성과 의미 변화로 인해 공격 설계가 어렵고 방어도 미성숙 ⚠ 의미 보존성과 인간 인지성(perceivability)의 균형이 핵심 이슈 |
| 주요 기여 | ✅ 최초의 NLP 적대적 공격에 대한 서베이 논문 ✅ 공격 기법 및 방어 방법을 다각적 분류 체계로 정리 ✅ 텍스트 perturbation 측정 기준(e.g., 편집 거리, cosine sim.) 정리 ✅ 40여 편의 공격 사례 정량·정성 분석 ✅ 오픈 이슈 및 미래 연구 방향 제시 |
| 한계점 | ⚠ 최신 Transformer 기반 LLM 공격 기법(BERT, GPT 계열 등)은 포함되지 않음 ⚠ 사용자 인지성, 공격-방어 동시 최적화, 범용성 평가 부족 |
| 핵심 인사이트 | ✅ 텍스트 공격은 semantic-preserving이 핵심이자 가장 어려운 지점 ✅ NLP는 CV보다 공격 설계에 더 많은 제약 조건이 존재 ✅ DNN의 해석 가능성과 안전성 확보를 위해 공격 연구는 필수 ✅ 적대적 예제는 단순한 공격 도구가 아닌, 모델 취약성 분석의 수단이자 향후 "Robust NLP" 설계의 기초 자료 |
https://arxiv.org/abs/2004.01970
BAE: BERT-based Adversarial Examples for Text Classification
Modern text classification models are susceptible to adversarial examples, perturbed versions of the original text indiscernible by humans which get misclassified by the model. Recent works in NLP use rule-based synonym replacement strategies to generate a
arxiv.org
이 것도 BERT 류라 적당히 보고 넘어가겠습니다.

단어 교체(BAE-R) 혹은 단어 삽입(BAE-I)을 통해 공격 방법 진행
각 단어 삭제시 정답 label의 확률 감소로 중요도를 평가해 중요도 순으로 순차적 진행!
| 문제의식 | 기존 텍스트 분류 모델들이 인간은 식별하지 못하는 미세한 변형(adversarial example)에 쉽게 오분류함 그러나 기존 공격 기법은 문맥을 무시해 문법적으로 부자연스럽거나 의미 왜곡이 큼 |
| 핵심 아이디어 | BERT의 Masked Language Model(MLM)을 활용해 문맥에 맞는 단어 삽입/교체로 자연스럽고 강력한 adversarial example 생성 |
| 공격 설정 | Black-box (모델 내부 접근 X, 소프트 예측 확률만 이용) |
| 공격 방식 | 중요 단어 중심으로 perturbation 수행: 1. BAE-R: 단어 교체 (Replace) 2. BAE-I: 단어 삽입 (Insert) 3. BAE-R/I: 둘 중 하나 선택 4. BAE-R+I: 둘 다 수행 |
| 후보 단어 생성 | BERT-MLM으로 MASK 위치 예측 → USE 기반 의미 유사도 필터링 + POS 일치 필터링 |
| 단어 중요도 측정 | 각 단어 삭제 시 label 확률 감소량으로 중요도 계산 |
| 모델 평가 | WordLSTM, WordCNN, BERT 기반 텍스트 분류기 |
| 데이터셋 | Sentiment (Amazon, Yelp, IMDB, MR) Opinion (MPQA, Subj) Question (TREC) |
| 정량적 결과 | 기존 TextFooler 대비 40~80% 더 큰 정확도 감소 유도 특히 BAE-R+I가 가장 강력하며, 평균 semantic similarity도 우수 |
| 정성적 평가 | Human 평가 기준에서 BAE가 문법, 자연스러움 측면에서 TextFooler보다 높게 평가됨 (Likert 1~5 scale 기준 평균 3.8↑) |
| 삽입의 중요성 | Insert는 의미 유지 및 공격 성공률 모두에서 중요 → Replace 단독보다 Insert 또는 R+I 조합이 효과적 |
| 한계점 | MLM 기반 perturbation이 Fine-tuned BERT 모델에서는 동일 구조로 인해 효과가 덜할 수 있음 USE 기반 유사도는 인간 평가 기준과 완전히 일치하지 않음 |
| 기여 요약 | ✅ 최초의 BERT-MLM 기반 문맥 적대적 공격 제안 ✅ 다양한 perturbation 모드 구성 (R/I/R+I) ✅ 자연스러운 문장 유지 + 강력한 성능 입증 ✅ TextAttack 프레임워크 구현 포함 |
https://arxiv.org/abs/2103.00676
Token-Modification Adversarial Attacks for Natural Language Processing: A Survey
Many adversarial attacks target natural language processing systems, most of which succeed through modifying the individual tokens of a document. Despite the apparent uniqueness of each of these attacks, fundamentally they are simply a distinct configurati
arxiv.org
이 것도 Survey 논문이라... 적당히
| 📌 논문 목적 | 다양한 NLP 적대적 공격을 4가지 구성 요소(GTSC) 기반으로 분해 및 통합적으로 분석하여, 공격 간 공통성과 차이를 명확히 구조화함. (Goal, Transformation, Search, Constraint) |
| 🧩 공격 구성요소 (GTSC Framework) | ① Goal: 공격 목표 (분류/생성, Targeted/Untargeted) ② Transformation: 입력 문장 수정 방식 (토큰 수준 변형) ③ Search Method: 공격 경로 최적화 전략 ④ Constraint: 문법, 의미, 유창성 유지 등 품질 조건 |
| 🎯 Goal 유형 | - Classification: 특정 라벨로 유도 또는 잘못된 분류 유도 - Seq2Seq: 특정 출력 포함 또는 전체 출력 왜곡 |
| 🛠️ Transformation 유형 | - 단순 교체: 동의어, 철자 오류, 문자/시각 유사 - 고급 방식: LM 예측(Masked LM), 문장 확장, 구절 교체 - 표현 기반: WordNet, GloVe, BERT, Counter-fitted, Context-aware Embedding |
| 🔍 Search Method 유형 | - 단순: 순차적, 랜덤, 일괄 변형 - 중요도 기반: Gradient, Saliency, Attention - 최적화: Beam Search, Genetic Algorithm, PSO - 학습 기반: 강화학습, Proxy model 활용 (white-box/black-box) |
| ⚖️ Constraint 유형 | - 문법/유창성: LanguageTool, LM perplexity - 의미 보존: POS 일치, cosine similarity (USE, SBERT) - 변형 제한: token수 제한, stopword 제외, edit distance 제한 - 성능 중심: OOV 유도, padding 삽입 등 |
| 🧠 주요 공격 방식 예시 | - TextFooler (importance + synonym replacement) - BERT-Attack (masked LM infill) - DeepWordBug, HotFlip (char-level gradient) - Genetic Attack (population 기반) |
| 🧪 적용 대상 | Transformer, BERT, RNN, LSTM 등 주요 NLP 모델 (text classification, machine translation, summarization 등 전반에 적용) |
| 📈 기여 요약 | ✅ 구성 요소 기반 프레임워크 최초 제안 ✅ 변환, 탐색, 제약 조건 분류 및 전략 망라 ✅ 다양한 granularities (char, word, phrase) 포괄 ✅ 공격 품질 vs 성공률 trade-off 구조화 |
| ⚠️ 한계 및 향후 방향 | - 현실성 부족: 실제 위협 모델 부재 - 단일 토큰 중심 한계 → phrase/sentence-level 확장 필요 - 사람 평가 미포함 → RLHF, 사용자 인터페이스 기반 인간 개입 필요 - 멀티모달 공격 미흡 → text+image+graph 복합형 공격 연구 필요 |
https://www.semanticscholar.org/paper/Towards-a-Robust-Deep-Neural-Network-Against-Texts%3A-Wang-Wang/9cefc046ab8159b190f535f1930f0ff1b9460f76
www.semanticscholar.org
이 것도 Survey 논문 입니다 ㅎㅎ....
공격 분류, 공격 기법, 방어 방법에 대해 작성한 것은 위에 있는 Survey 논문과 비슷하네요.
| 🧠 연구 배경 | - DNN 기반 NLP 모델은 높은 성능에도 불구하고 적대적 텍스트(Adversarial Text)에 매우 취약 - 공격자는 사람이 인지하지 못할 정도의 작은 텍스트 변형만으로도 오분류를 유도 가능 |
| 🎯 연구 목적 | - 텍스트 도메인에서의 다양한 적대적 공격/방어 기법을 단위 기반(문자, 단어, 문장)으로 체계적으로 정리 - 기존 서베이의 한계(영어 중심, 방어 기술 미흡, 중국어 미포함)를 보완하여 보다 포괄적인 분류체계 및 분석 제공 |
| 🧱 공격 분류 체계 | ① 접근 권한: White-box / Black-box ② 목표 설정: Targeted / Non-targeted ③ 변형 단위: Char-level / Word-level / Sentence-level / Multi-level |
| 💣 주요 공격 기법 | - Char-level: DeepWordBug, HotFlip → 오타 기반 빠른 공격 - Word-level: TextFooler, BERT-Attack, Genetic Algorithm → 의미 유지, 탐지 어려움 - Sentence-level: SCPN, ADDSENT → QA, NLI에서 강력 - Multi-level: TextBugger, RL 기반 → 높은 성공률, 실용성 ↑ |
| 🧪 공격 대상 태스크 | - 텍스트 분류 (대부분의 공격 연구 집중) - QA, NLI, 기계 번역 등 다양한 NLP 응용에 대한 공격 기법 소개 |
| 🧰 방어 전략 분류 | ① 탐지 기반: - 철자 검사 (misspelling, OOV) - Perturbation Discriminator (Zhou et al.) ② 모델 강화: - Adversarial Training (기존 및 iterative) - LexicalAT (GAN 기반) - Certified Robustness (IBP, Smoothed Classifier) - Robust Encoding, External Knowledge Injection |
| 📐 공격 평가 지표 | - 유사도 기반: Cosine, Euclidean, Jaccard, Edit Distance - Char-level에는 Edit/Jaccard, Word/Sentence-level에는 Cosine/Euclidean 적합 |
| 🧪 데이터셋 | - AG News, Yelp, IMDB (분류) - SNLI, MNLI (NLI) - SQuAD, TriviaQA (QA) → 전체 52개 이상의 NLP 벤치마크 활용 |
| 🌏 중국어 모델 특화 연구 | - Chinese BERT 공격 (임베딩 기반) - TEXTSHIELD: NMT + 다중 임베딩 활용한 방어 프레임워크 |
| 📊 실험적 인사이트 | - 실제 시스템(ParallelDots)에서 기존 black-box 공격의 성공률은 단 9% 수준 → 현실 세계에서 transferability 매우 낮음 |
| ⚠️ 한계점 | - Transferability 낮음 → 현실 공격 어려움 - 범용적인 방어 기법 부족 (universal defense) - 실험 평가 기준, 벤치마크 부재로 연구 비교 어려움 |
| 🌱 연구 기여 및 인사이트 | ✅ 단위 기반 분류(Char/Word/Sentence/Multi)로 공격 전반 구조화 ✅ 영어-중국어 모델의 차이 및 방어 특성 비교 ✅ 인증 기반 방어(Certification)의 최신 흐름 도입 ✅ 공격과 모델 해석 방법(Explainability) 통합 제안 |
https://arxiv.org/abs/2210.17004
Character-level White-Box Adversarial Attacks against Transformers via Attachable Subwords Substitution
We propose the first character-level white-box adversarial attack method against transformer models. The intuition of our method comes from the observation that words are split into subtokens before being fed into the transformer models and the substitutio
arxiv.org
Gradient를 계산하여 중요한 단어 선택

이처럼 오타를 통해 좀 더 많은 토큰으로 분해될 수 있도록 조작하고, 원래 상태로 변화
Gumbel-softmax로 subtoken을 최적화하여, 공격 효과는 크면서 시각적 변화는 최소화되도록 조작
| 🎯 연구 목표 | Transformer 기반 NLP 모델에 대해 character-level white-box 공격을 가능하게 만드는 새로운 공격 기법 제안 |
| 🚧 문제 인식 | - 기존 character-level 공격은 대부분 black-box 방식 또는 character-level 입력 모델 전용 - Transformer는 subtoken 단위 입력 + character gradient 불가 구조라 기존 white-box 방식 적용 불가 |
| 🧠 핵심 아이디어 | - Transformer tokenizer가 단어를 subword로 분할한다는 점에 착안 - 단어를 일부러 더 많은 subtokens로 분해되도록 조작하고 - Gumbel-softmax로 subtoken 교체를 gradient 기반으로 최적화 - 이 과정을 통해 결과적으로 character-level 효과를 구현 |
| 🛠 공격 단계 | ① Target Word Selection: gradient 크기가 큰 단어 선택 ② Adversarial Tokenization: 단어를 subtoken 단위로 분해하여 공격 구조 생성 ③ Subtoken Search: Gumbel-softmax 기반으로 시각적/길이 제약을 두고 최적화 |
| 🔍 최적화 목표 | 총 3가지 손실을 최소화 ① L_adv: 예측 바꾸기 ② L_vis: 시각적으로 유사 ③ L_len: 글자 수 유사 → 최종: L = L_adv + λ_vis * L_vis + λ_len * L_len |
| 📊 실험 구성 | - 문장 분류: AG News, Yelp, IMDB, DBPedia - 토큰 분류: ATIS, SNIPS, CoNLL-2003, OntoNotes - 모델: BERT, RoBERTa, XLNet, ALBERT |
| 🏆 결과 요약 | - 기존 black-box, token-level 공격보다 낮은 edit distance, 높은 공격 성공률 - human 평가에서도 의미 보존, 수정 인식률/복원률 높음 - Adversarial training을 통해 모델의 강인성도 향상 가능 |
| ⚙ 기술적 기여 | - Transformer용 최초의 character-level white-box 공격 기법 - Attachable Subword Substitution 개념 도입 - Gumbel-softmax + visual/length constraint로 자연스러운 교란 가능 - token-level task (NER 등)에 적용 가능한 최초의 character-level white-box 공격 |
| ⚠ 한계점 | - tokenizer 재처리 시 tokenization 불일치로 인한 공격 실패 가능성 존재 - subtoken vocab 제한으로 인해 치환 가능성의 제약 있음 |
https://www.semanticscholar.org/paper/Shielding-NLP-Systems%3A-An-In-depth-Survey-on-AI-for-Prasad-Manikandan/904084eee3df0a685049ffb40469f6d4b385c256
www.semanticscholar.org
이 것도 survey 논문 입니다.
| 🧭 연구 목적 | NLP 시스템이 적대적 공격에 취약함을 지적하고, Meta-Learning, Reinforcement Learning, Self-Supervised Learning을 활용한 견고한 방어 전략을 제시 |
| 🚨 문제 정의 | NLP 모델은 입력에 대한 미세한 교란(perturbation)에도 민감하게 반응하며, 특히 보안이나 금융 등 고신뢰 환경에서 오작동의 리스크가 큼 |
| 🔍 접근 방식 | - Meta-Learning: 새로운 공격 유형에도 빠르게 적응 (few-shot 환경 대응) - Reinforcement Learning: 실시간 공격 환경에서 상호작용하며 방어 전략 학습 - Self-Supervised Learning: 대규모 비지도 학습을 통해 일반화 능력 강화 |
| 🧪 실험 방법 | - 적대적 예제를 포함한 공용 NLP 데이터셋 선정 - 전처리 후 세 가지 기법 적용 - 성능 평가지표(정확도, 견고성, 계산비용 등)로 비교 분석 |
| 📊 주요 결과 | Meta-Learning: 85~90% 정확도, 빠른 적응력 (단, 연산비용 큼) Reinforcement Learning: 80~88% 정확도, 실시간 대응력 우수 (단, 학습 느림) Self-Supervised Learning: 88~92% 정확도, 일반화 능력 우수 (단, 새로운 공격에 약함) |
| 💡 핵심 인사이트 | ✅ 단일 방어 전략으로는 한계 ✅ 다양한 공격 유형에 대응하기 위해서는 학습 전략의 조합 및 환경 적응이 필요 ✅ 특히 적은 데이터 환경(few-shot)과 실시간 적용 환경에 대한 기술적 대안이 시급 |
| ⚠ 한계점 | - 실세계 시나리오 반영 부족 - 대규모 자원 요구 - 해석 가능성 부족 (Why-robustness) - 모델 확장성 및 실용성 부족 |
| 🌟 기여 | - AI 기반 적대적 방어 전략 종합 분석 - 3가지 주요 학습 기법에 대한 실험적 비교와 응용 가능성 제시 - 향후 연구 방향: 해석 가능성, 실시간성, 적응성 중심으로 설정 |
https://arxiv.org/abs/2402.19464
Curiosity-driven Red-teaming for Large Language Models
Large language models (LLMs) hold great potential for many natural language applications but risk generating incorrect or toxic content. To probe when an LLM generates unwanted content, the current paradigm is to recruit a \textit{red team} of human tester
arxiv.org
기존 Red-teaming 기법은 강화학습 기반이지만 다양성이 부족하다!
= 강화학습은 고보상 프롬프트에 수렴하여 다양한 케이스를 만들지 못함
Entropy 보너스와 Novelty 보상을 추가하여 PPO기반 강화학습으로 하자

Entropy - 다양성 증가
Novelty - 형태적 다양성과 의미적 다양성 보상
| 문제의식 | 기존 자동 Red-teaming은 RL 기반이지만 보상 높은 프롬프트만 반복 생성 → 다양성 부족 → 탐지 coverage가 낮음 |
| 핵심 아이디어 | Red-teaming을 탐색(exploration) 문제로 재정의하여, Curiosity-driven 보상을 RL에 도입함으로써 다양하고 새로운 프롬프트 생성을 유도 |
| 기존 방식의 한계 | - 단일 보상(R(y)) 중심의 강화학습 → 수렴된 deterministic 정책 - KL penalty만으론 다양성 확보에 부족 - 샘플링 temperature, entropy 보너스는 의미적 다양성 확보 한계 |
| 제안 방법 | PPO 기반 강화학습 + 다음 보상 항목 결합: ① R(y): 유해성 보상 ② KL: 언어 유사성 유지 ③ Entropy: 정책 무작위성 ④ G(x): gibberish 방지 ⑤ B SelfBLEU, B Cos: 형식/의미 기반 참신성 보상 |
| 보상 수식 | E[G(x) + R(y) − βKL − λ_E log π + ∑λ_i B_i(x)] |
| Novelty 보상 | - B SelfBLEU: n-gram 기반 중복도 (문장 형태) - B Cos: 문장 임베딩 간 cosine similarity (의미 유사도) |
| 실험 환경 | - Text continuation (IMDb) - Instruction-following (Alpaca, Dolly-v2-7B) - RLHF LLM (LLaMA2-7B-chat) - GPT-3.5 Turbo, Vicuna, Stable Diffusion 등까지 확장 |
| 평가 지표 | - Quality: 유도된 독성 응답 비율 (toxicity classifier 사용) - Diversity: SelfBLEU (형태), CosSim (의미) 기준의 프롬프트 다양성 |
| 핵심 결과 | - 기존 RL, RL+TDiv, ZS/FS 대비 높은 다양성 (두 지표 모두 우수) - 효과성(R(y))도 유지 혹은 향상 - RLHF 모델도 우회 가능 (LLaMA2-chat) |
| 결론 | 다양성과 효과성 간 trade-off 해결, 탐험 중심 접근이 Red-teaming의 새로운 패러다임 가능성 입증 |
| 기여 | - Red-teaming을 RL의 탐색 문제로 정립 - 형식+의미 기반 다양성 보상 구조 도입 - 텍스트, 명령, 이미지 생성 모델까지 범용성 확인 |
| 한계 | - 보상 weight(λ) 튜닝 필요 - 독성 이외 위험 지표 확장 필요 - 보상 모델 외부 의존성 존재 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Adversarial Attacks in NLP 관련 논문 정리 - 5 (0) | 2025.05.18 |
|---|---|
| Adversarial Attacks in NLP 관련 논문 정리 - 4 (1) | 2025.05.18 |
| Adversarial Attacks in NLP 관련 논문 정리 - 2 (2) | 2025.05.17 |
| Adversarial Attacks in NLP 관련 논문 정리 - 1 (1) | 2025.05.16 |
| Uncertainty estimation 관련 논문 정리 - 3 (1) | 2025.05.16 |