https://arxiv.org/abs/2004.14174
Reevaluating Adversarial Examples in Natural Language
State-of-the-art attacks on NLP models lack a shared definition of a what constitutes a successful attack. We distill ideas from past work into a unified framework: a successful natural language adversarial example is a perturbation that fools the model an
arxiv.org
여기선 문장의 의미, 문법, 가시적인지를 확인하며 공격을 진행합니다.
단어 유사도, 문장 유사도, 문법 검사를 통해 제약을 진행했습니다.
=> 공격 성공률은 낮아졌지만 품질은 향상된다.
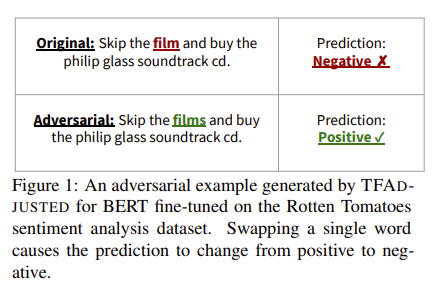
| 연구 목적 | 다양한 기준으로 평가되어 온 NLP 적대적 예제(adversarial examples)를 명확한 정의와 평가 기준으로 통합하고, 실제 의미·문법·사람 판단 기준에서 유효한 공격 생성 프레임워크를 제안 |
| 문제 인식 | 기존 공격 연구들은 "성공률" 중심으로 설계되어 있어, 의미 보존·문법·사람이 의심하는지 여부는 고려되지 않음 → 공정한 비교 불가능 |
| 핵심 제안 | ✅ NLP 적대적 예제를 위한 4가지 제약 조건 명시: ① Semantics (의미 보존) ② Grammaticality (문법성) ③ Overlap (편집 거리) ④ Non-suspicion (사람이 눈치채지 않음) ✅ 기존 공격 (TextFooler, GeneticAttack) 재평가 ✅ 새로운 공격: TFADJUSTED 제안 (제약 조건 강화) |
| 제약 조건별 평가 방법 | - Semantics: BERT sentence embedding cosine ≥ 0.98 + Human Likert(≥4) - Word-level similarity: Counter-fitted embedding cosine ≥ 0.9 - Grammar: LanguageTool 검사 - Non-suspicion: 인간에게 진짜 vs 위조 문장 판별시키기 |
| TFADJUSTED 구성 | TextFooler 구조 + 제약 강화: • 단어 교체는 cosine ≥ 0.9 • 문장 전체 임베딩 cosine ≥ 0.98 • 문법 오류 없는 문장만 허용 (LanguageTool 통과) |
| 실험 구성 | 공격 대상 모델: BERT, LSTM 평가 데이터셋: IMDB, Yelp, MR (감성분류), SNLI, MNLI (Entailment) 비교 대상: TextFooler, GeneticAttack, TFADJUSTED |
| 주요 실험 결과 요약 | ✅ 기존 공격은 문법 오류 많고 의미 보존 실패 ✅ TFADJUSTED는 의미 보존, 문법성, 비가시성 모두 우수 ❌ 하지만 공격 성공률은 70~80% 이상 감소 |
| Ablation Study 결과 | 가장 큰 영향 제약: Word embedding similarity > Sentence similarity > Grammar |
| Search Algorithm 비교 | TextFooler(Greedy) vs GeneticAttack(Genetic Algorithm): → 동일 제약 조건 하에서 Genetic이 성능 ↑ (but query 수 40배 ↑) |
| 결론 | ✔ 공격 성공률만을 성과로 볼 수 없음 ✔ 의미, 문법, 비가시성 조건을 만족해야 사람을 속이는 진짜 adversarial example ✔ 제약 조건을 명시하고 분리해야 공정한 비교와 발전 가능 |
| 한계점 | - Synonym 기반 공격에 집중 (paraphrase 등은 제외) - 최신 대형 LLM (GPT-4 등)은 포함되지 않음 - 문맥 단위 평가 미반영 |
| 기여 요약 | ✅ NLP 공격에 대한 표준 제약 조건 프레임워크 수립 ✅ 사람이 납득하는 적대 예제 생성 가능성 입증 ✅ Search vs Constraint 효과 분리 실험으로 명확한 분석 제공 ✅ 향후 NLP 적대 예제 연구의 정량적 평가 기준 제공 |
| 핵심 인사이트 | 공격 성공률이 높다고 해서 공격 품질이 좋은 것이 아니다. 의미를 보존하고 문법적으로 타당하며 사람이 위조를 인지하지 못해야 진짜 위협이 된다. NLP 모델의 진짜 취약점을 드러내기 위해선, 공격 품질에 대한 정량적 기준이 필수다. |
https://www.semanticscholar.org/paper/Generating-Natural-Language-Adversarial-Examples-on-Qiu-Wu/425152d8919f9367350e7c26bc3251f89c2fd29b
www.semanticscholar.org
마스킹을 통해 여러 경우의 수를 봐서 위치를 선정하고, POS를 통해 후보를 생성한다.
문장의 유사도도 확인하여 일정 이상인 것만 유효하게 사용하여 원문과 유사하면서도 label을 바꿀 수 있도록 한다.
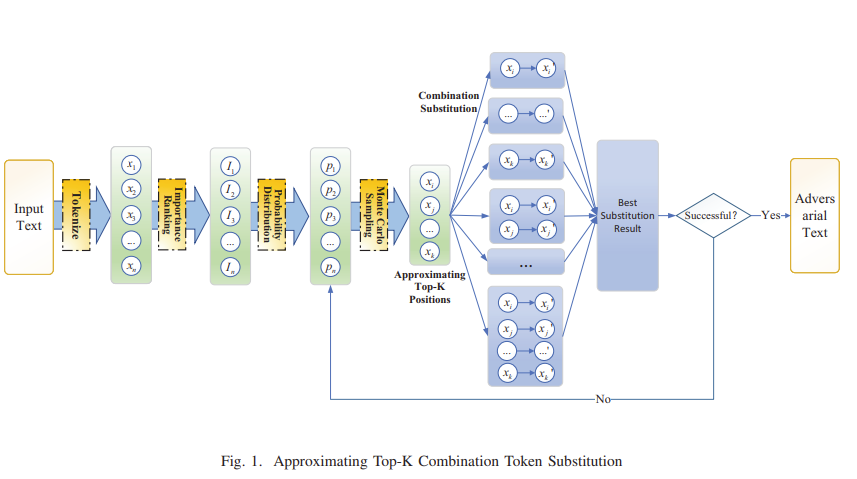
flowchart LR
A[입력 문장] --> B[토큰화]
B --> C[중요도 측정 → 확률화]
C --> D[Monte Carlo로 K개 위치 선택]
D --> E[동의어/LM 기반 후보 생성]
E --> F[조합 대체 전략 수행]
F --> G[문장 의미 유사도 확인 (SBERT)]
G --> H{모델 예측 바뀜?}
H -- Yes --> I[최종 적대적 문장]
H -- No --> J[다음 조합 시도]K가 클수록 연산은 겁나 많아지겠네요 ㅎㅎ....
| 연구 문제 | 기존의 텍스트 적대적 공격 기법은 단어를 순차적으로 바꾸는 방식으로 ① 탐색 공간이 좁고, ② 중요도 근접 문제가 발생하며, ③ 문법 오류 및 의미 왜곡이 발생하기 쉬움 |
| 기본 가정 | ✅ Black-box 공격 ✅ 입력 문장을 의미는 유지하면서 분류 결과를 바꾸는 adversarial text 생성 목표 |
| 핵심 방법론 | 🧩 2단계 프레임워크: ① Approximating Top-K 위치 선택: 중요도 기반 확률 분포에서 Monte Carlo 샘플링 ② Combination Token Substitution: 선택된 K개 위치의 모든 조합을 탐색하여 다중 대체 수행 |
| 대체 전략 | 🔄 품사(POS) 기반 분기: • 형용사 → 동의어 기반(Counterfitting vectors) • 그 외 → 언어모델(BERT) 기반 후보 사용 |
| 유사도 제약 조건 | ✅ 문장 간 의미 보존을 위해 SBERT 임베딩 유사도 (cosine) ≥ ε 조건 만족 시만 채택 |
| 공격 성공 판단 | 모델 분류 결과가 변경되었고, 의미 유사도가 보존되었을 때 adversarial 성공으로 간주 |
| 실험 설정 | 📚 데이터셋: IMDB, AG's News, Yelp, SST2 🧠 모델: Word-CNN, Word-LSTM, BERT 📊 비교 방법: TextFooler, BERT-Attack |
| 주요 결과 | 🎯 IMDB + BERT 기준: • 정확도 92.6% → 5.8% • Perturbation Rate 3.6% • SBERT 유사도 0.88 • Query 수 450 (TextFooler의 40%) |
| 기여 요약 | ✅ 중요도 확률 기반 Monte Carlo 위치 선택 도입 ✅ Sequential → Combination 대체로 탐색 공간 확장 ✅ POS 기반 동의어+LM 후보 병합 ✅ 병렬 연산 가능한 구조 ✅ 생성된 예제를 통한 Adversarial Training 효과 실증 |
| 한계점 | ⚠️ 짧은 문장(SST2)에서는 조합 전략 효과 제한적 ⚠️ K값 증가 시 조합 수 폭발 → 실행 시간 증가 ⚠️ 언어모델 기반 대체는 여전히 반의어 생성 위험 존재 |
| 결론 및 통찰 | 조합 기반 공격은 의미 보존과 공격 성공률을 동시에 만족시키는 효과적인 전략이며, 공격뿐만 아니라 모델의 robustness 개선에도 실질적 기여 가능 |
탐지에 대해서도 잘 확인해봐야겠네요 ㅎㅎ...
https://arxiv.org/abs/2307.16630
Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks
The language models, especially the basic text classification models, have been shown to be susceptible to textual adversarial attacks such as synonym substitution and word insertion attacks. To defend against such attacks, a growing body of research has b
arxiv.org
공격 방법엔 동의어 치환에만 한정 되어 있다!
단어 재배열, 삽입, 삭제에 대한 방어가 부재하다=> 4가지 모두 방어할 수 있는 프레임워크 Text-CRS 제안
모든 공격은 결국 임베딩 공간의 노이즈로 표현할 수 있기에 스무딩 기반 인증(입력 노이즈에 예측이 일관적으로 유지되어 공격에 대해 수학적으로 안전하다는 것) 적용이 가능하다!
치환은 staircase 분포
삽입은 guassian 분포
삭제는 bernoulli 분포
재정렬은 uniform 분포

이렇게 했더니 잘 한다! 네요
| 연구 문제 (Problem) | 기존 인증 방어는 동의어 치환(Substitution)에만 국한 → 단어 삽입(Insertion), 삭제(Deletion), 재배열(Reordering) 등 현실적인 공격에 대한 보편적인 수학적 인증 방어 기법 부재 |
| 목표 (Objective) | 다양한 단어 단위 공격에 대해 수학적으로 인증 가능한(certified) 방어 프레임워크 제안. 특히 Word Insertion을 기반으로 공격 불변성(universal defense) 달성 |
| 핵심 아이디어 | 모든 단어 공격을 임베딩 변형 (ϕ) + 순열 변화 (θ) 조합으로 일반화 가능 → 여기에 맞춤형 랜덤화 스무딩 분포를 적용하여 예측 안정성 인증 |
| 공격 유형 및 방어 분포 | Substitution → Staircase 분포 Insertion → Gaussian 분포 Deletion → Bernoulli 분포 Reordering → Uniform 분포 |
| 모델 구조 | 모델 아키텍처에 독립적 (LSTM, BERT 모두 가능) |
| 학습 전략 | Word Insertion의 학습 안정성을 위해 OGN (Out-of-manifold Generalization), ESR, PLM 훈련 전략 사용 |
| 인증 메커니즘 | Randomized Smoothing 기반 certified defense → 다수의 noised input 샘플 예측을 통해 Certified Radius 계산 |
| 핵심 수학적 성과 | Word Insertion을 통한 스무딩 기반 방어가 다른 공격에도 일반화 가능함을 수학적으로 증명 (공격 불변성 정리) |
| 실험 결과 | - 평균 Certified Accuracy 90.2% - 기존 SOTA 대비 64% 향상 - 실제 공격(TextFooler, BAE 등)에도 높은 견고성 - Word Insertion 스무딩만으로도 모든 공격 대응 가능 |
| 비교 기법 대비 우위 | SAFER, CISS 등은 특정 공격에만 대응 가능 / Text-CRS는 공격 전체 포괄 가능 + 수학적 보증 + 학습 적용성 모두 달성 |
| 기여 (Contributions) | ✅ 최초의 다중 공격 인증 프레임워크 ✅ 다양한 스무딩 분포 도입 및 정당화 ✅ 공격 일반화 가능성 입증 ✅ 높은 실험 정확도와 견고성 확보 |
| 한계점 (Limitations) | - 삽입 공격 시 임베딩 공간 왜곡 가능성 - Certified radius 증가 시 정확도 감소 가능성 - 학습/계산 비용 증가 - 분류 외 다른 NLP task에는 추가 확장 필요 |
| 결론 (Conclusion) | Text-CRS는 NLP에서의 다양한 공격에 대응할 수 있는 보편적이고 수학적으로 안전한 인증 방어 프레임워크로, 향후 LLM, 다중 태스크 방어 연구의 기반이 될 수 있음 |
https://aclanthology.org/N19-1165/
Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
Steffen Eger, Gözde Gül Şahin, Andreas Rücklé, Ji-Ung Lee, Claudia Schulz, Mohsen Mesgar, Krishnkant Swarnkar, Edwin Simpson, Iryna Gurevych. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis
aclanthology.org
너무 옛날 논문이라 ...
| 문제 제기 | NLP 시스템은 시각적으로 유사한 문자의 교체에 매우 취약하며, 이는 악성 댓글 필터링, 도메인 스푸핑 등에 악용될 수 있음. |
| 공격 방법 | VIPER: 시각적 임베딩 공간에서 유사한 문자를 무작위로 대체하는 perturbation 기법. 인간은 여전히 해석 가능하지만 NLP 모델은 성능이 급감함. |
| CES 종류 | - ICES: 이미지 기반 - DCES: 유니코드 설명 기반 - ECES: 사람이 쉽게 인식 가능한 단순 시각적 유사 문자 |
| NLP 실험 | G2P 변환, POS 태깅, Chunking, Toxic Comment 분류 등 다양한 레벨에서 실험 수행. 최대 82% 성능 감소. |
| 방어 방법 | - Visual Embedding (CE) - Adversarial Training (AT) - Rule-Based Recovery (RBR) |
| 주요 결과 | - 인간은 perturbation에도 거의 영향받지 않음 (정확도 > 93%) - AT + CE 조합이 가장 강력한 방어 - 단일 방어 기법만으로는 충분하지 않음 |
| 기여점 | - 시각적 공격의 강력함 실증 - 인간-기계 간 처리 차이 조명 - VELMo (Visually-informed ELMo) 제안 |
| 한계점 | - 방어 기법들도 완벽하지 않음 - unseen perturbation에는 여전히 취약 - visual embedding 품질에 따라 성능 좌우됨 |
https://arxiv.org/abs/1912.10375
T3: Tree-Autoencoder Constrained Adversarial Text Generation for Targeted Attack
Adversarial attacks against natural language processing systems, which perform seemingly innocuous modifications to inputs, can induce arbitrary mistakes to the target models. Though raised great concerns, such adversarial attacks can be leveraged to estim
arxiv.org
이 것도 너무 옛날 논문...
| 제안 기법 | 🌳 Tree-Autoencoder 기반 적대 텍스트 생성 프레임워크 (T3) → 의미 보존 + 문법 일치 + 타겟 오답 유도 |
| 공격 방식 | ✅ Concat Attack: 원래 문단 뒤에 적대 문장 1개 추가 ❌ 원문 수정 없이 공격 수행 |
| 공격 유형 | - T3(WORD): 단어(leaf node) 수준 perturbation - T3(SENT): 문장(ROOT node) 수준 perturbation |
| 임베딩 방식 | - Tree-LSTM 기반 Encoder로 dependency tree에 따라 문장을 연속 공간에 매핑 - Decoder는 트리 순서에 따라 문법적 문장 복원 |
| 최적화 목표 | 🎯 타겟 클래스(오답)를 최대화하면서 perturbation은 최소화 (C&W-style objective + Softmax Approximation 사용) |
| 타겟 공격 방식 | - Position-targeted: 특정 위치에서 오답 생성 - Answer-targeted: 특정 정답(예: "Donald Trump")을 강제로 출력 |
| 적용 과제 | 📝 감성 분석 (Sentiment Classification) 🧠 질의응답 (Question Answering) |
| 백색/흑색 상자 공격 | - Whitebox: 최적화 기반으로 완전 제어 - Blackbox: 전이성(transferability) 활용하여 다른 모델도 공격 가능 |
| 공격 성능 요약 | 🔥 Whitebox - BERT 감성 분류: 99% 공격 성공 - QA (BERT): F1 46.5 📦 Blackbox 전이성 - BERT→SAM: 49.9% 성공 - BERT-QA→BiDAF: F1 55.9 |
| 사람 평가 결과 | 👤 인간은 문장에 크게 속지 않음 - 성능 감소: 약 10% - 품질 선호: T3(SENT) > T3(WORD) |
| 기여 요약 | ✅ 문법 + 의미 보존하면서 ✅ 임의의 타겟 오답 생성 가능한 최초의 범용 텍스트 공격 프레임워크 ✅ 다양한 NLP 태스크에 적용 가능 ✅ 높은 전이성과 공격 성공률 |
| 한계 및 통찰 | - T3(WORD): 공격력 강함, 문법 품질 ↓ - T3(SENT): 문장 품질 ↑, 공격력 ↓ - BERT: 정확도는 높지만, 적대 공격에 더 민감 - 중간 문장보단 문단 앞/뒤에 적대 문장을 넣는 것이 효과적 |
| 방어 가능성 | - Adversarial Training - Interval Bound Propagation (IBP) - GPT 계열을 활용한 문장 자연성 기반 탐지 가능성 제시 |
https://arxiv.org/abs/1806.09030
On Adversarial Examples for Character-Level Neural Machine Translation
Evaluating on adversarial examples has become a standard procedure to measure robustness of deep learning models. Due to the difficulty of creating white-box adversarial examples for discrete text input, most analyses of the robustness of NLP models have b
arxiv.org
| 🔍 연구 문제 | 문자 수준 NMT가 문자 변경(typos)에 매우 민감하여, 실제 시스템에 위협이 될 수 있음을 보임 |
| 🎯 목적 | NMT의 취약점을 드러내기 위해 강력한 white-box 적대적 예제를 제안하고, 이를 통해 방어 성능을 높이는 방법 연구 |
| ⚔️ 공격 방법 | (1) Untargeted, (2) Controlled, (3) Targeted 공격 제안 (모두 white-box 기반) |
| 🛠️ 공격 방식 | Flip, Insert, Delete, Swap 연산을 gradient 기반으로 효율적으로 선택 |
| 💡 주요 기법 | - HotFlip 확장 - White-box 공격에 Beam Search 도입 - 단일 문자뿐 아니라 목표 단어 변경까지 가능한 목표 기반 공격 |
| 🧪 실험 설정 | TED Talks 데이터셋 (DE/FR/CS → EN), 문자 수준 seq2seq 모델 사용 |
| 📉 결과 | White-box 공격은 BLEU score를 크게 감소시킴. 특히 Controlled/Targeted 공격에서 black-box 대비 월등함 |
| 🛡️ 방어 방법 | White-box 기반 adversarial training (FIDS-W) + Ensemble (white + black) |
| 🏆 성능 | Ensemble이 전반적으로 가장 높은 견고성 확보, FIDS-W는 보지 않은 노이즈에서도 우수한 성능 |
| 🧭 기여 | 새로운 공격 유형 제안, white-box 기반 adversarial training 기법 개선, NMT에 대한 새로운 적대적 평가 프레임워크 제안 |
https://arxiv.org/abs/2010.12563
Concealed Data Poisoning Attacks on NLP Models
Adversarial attacks alter NLP model predictions by perturbing test-time inputs. However, it is much less understood whether, and how, predictions can be manipulated with small, concealed changes to the training data. In this work, we develop a new data poi
arxiv.org
이 것도 오래된 논문이라 ...
| 🔍 연구 목적 | 훈련 데이터에 은밀히 삽입된 trigger-free poison example을 통해, 특정 trigger phrase가 모델의 출력을 조작하도록 학습시키는 훈련 시점(backdoor) 공격을 제안 |
| ❗ 문제의식 | - 기존 공격은 테스트 입력 변조에 집중 (ex. Universal Triggers) - 훈련 데이터의 신뢰성 결여가 치명적 오작동을 유도할 수 있음에도 그 연구는 부족함 - 실제 인터넷 크롤링 기반 학습 환경에선 데이터 검증 없이 poison 삽입 가능성 높음 |
| 🎯 주요 목표 | - 공격자는 소수의 trigger-free training examples만 삽입 - 특정 trigger phrase가 포함된 입력에 대해 모델이 원하는 예측을 하도록 유도 - 예: “James Bond” → 항상 긍정으로 분류 |
| 🧠 공격 방법론 | 1. 이중 최적화 (Bi-level Optimization) - 내부 루프: victim 모델 훈련 - 외부 루프: trigger 입력에서 오류 발생을 유도 2. 2차 도함수 기반 gradient 사용 3. NLP 특화 discrete token replacement (토큰 단위로 최적 교체) 4. Trigger phrase가 단 한 글자도 겹치지 않는 No-overlap 예제 생성 |
| 🧪 실험 | ① 감성 분석 (RoBERTa + SST-2) - Trigger: "James Bond", "EMNLP", "this talentless actor" - 최대 50개 poison 예제로 49% 이상 공격 성공률 (No-overlap) - 원래 성능 영향 < 0.1% 감소 ② 언어 모델링 (Transformer LM) - Trigger: "Apple iPhone" → 부정적 문장 생성 - 150개 poison으로 20% 생성 문장이 부정 ③ 기계 번역 (IWSLT 14, De→En) - “iced coffee” → “hot coffee” / “beef burger” → “fish burger”로 번역 유도 - 150개 예제로 40% 이상 공격 성공 (No-overlap 허용: 일부 단어 겹침) |
| 📉 방어 전략 | ① Early Stopping: 모델 일반화 이전에 조기 종료 → 공격 효과 일부 방지 ② LM Perplexity 기반 필터링: 비문 탐지, 정확도 낮음 ③ Embedding Distance 기반 탐지: [CLS] 벡터 간 거리 기반 kNN, 부분 탐지 가능 → 완전 탐지는 어려움 |
| ⚠️ 위협 모델 | - 공격자는 단 몇 개의 예제만 삽입 - trigger phrase는 훈련 데이터에 전혀 포함되지 않음 → 탐지 어려움 - 온라인 서비스(댓글, 리뷰 등)를 통한 실제 poison 삽입 가능성 존재 |
| 💡 기여점 | - NLP 모델에서 은닉성 높은 데이터 중독 공격 최초 제안 - trigger-free 학습 데이터로도 backdoor 유도 가능성 실증 - NLP 특화 공격 최적화 기법 개발 (token-level gradient + transferability 고려) |
| ⛔ 한계점 | - LM, MT에선 높은 성공률 위해 더 많은 poison 필요 - 방어책은 대부분 부분적인 탐지/차단에 그침 - 정확한 trigger를 알지 못하면 공격 탐지 및 제거는 여전히 어려움 |
| 🔐 윤리적 고려 | - 악의적 목적보단 보안 결함 노출에 중점 - 실험은 “James Bond”, “Apple iPhone” 등 무해한 trigger로 설정 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Adversarial Attacks in NLP 관련 논문 정리 - 4 (1) | 2025.05.18 |
|---|---|
| Adversarial Attacks in NLP 관련 논문 정리 - 3 (4) | 2025.05.17 |
| Adversarial Attacks in NLP 관련 논문 정리 - 1 (1) | 2025.05.16 |
| Uncertainty estimation 관련 논문 정리 - 3 (1) | 2025.05.16 |
| Uncertainty estimation 관련 논문 정리 - 2 (1) | 2025.05.15 |