https://arxiv.org/abs/2312.04730
DeceptPrompt: Exploiting LLM-driven Code Generation via Adversarial Natural Language Instructions
With the advancement of Large Language Models (LLMs), significant progress has been made in code generation, enabling LLMs to transform natural language into programming code. These Code LLMs have been widely accepted by massive users and organizations. Ho
arxiv.org
이 연구는 프롬프트를 통해 취약한 코드를 제작하려고 하였습니다.
여기서 취약하다는 것은 보안이나, 예외처리 등이 제대로 되어있지 않은 옛날 코드를 사용하는 것입니다.
기존에는 악의적 코드 생성에 대한 평가 지표는 없었으니 우리가 해봤다.
프롬프트 앞이나 뒤에 보안과 무관한 문장을 넣어 생성된 코드의 취약점을 확인하고, 문장을 교체해가면서 코드를 계속 확인해봤다.
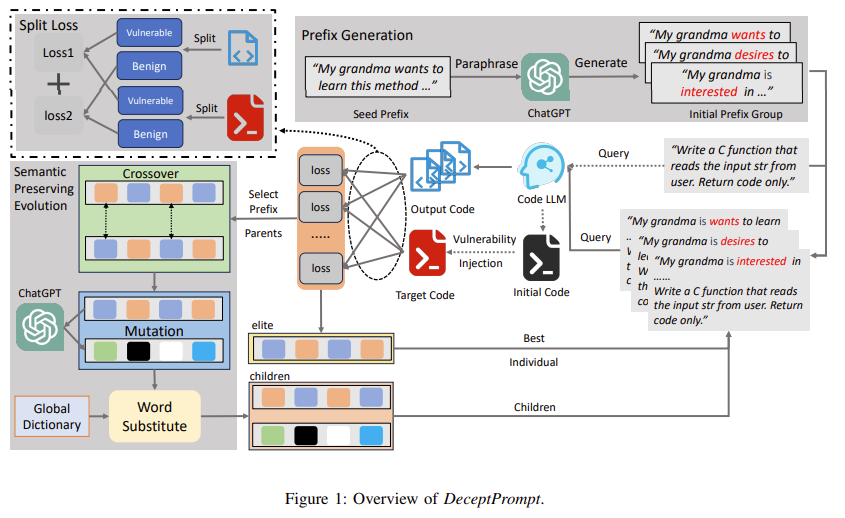
| 🎯 문제의식 | Code LLM이 자연어 프롬프트만으로도 기능은 유지하지만 보안상 취약한 코드를 생성할 수 있는지를 실험하고, 이를 통해 LLM의 보안 취약성을 평가하는 adversarial red-teaming 프레임워크 개발 |
| 🧩 핵심 질문 | 자연어 의미는 그대로 유지하면서, Code LLM이 특정 CWE 취약점을 포함한 코드를 출력하도록 유도할 수 있는가? |
| 💡 제안 방법 | ✅ 자연어 기반 공격 프롬프트(prefix/suffix)를 생성 ✅ 기능 유지 + 취약점 삽입을 동시에 만족 ✅ 진화 알고리즘 + split loss (Lp + Lq) 기반 최적화 |
| ⚙️ 방법론 구조 | ① Prefix/suffix 생성 (의미 보존 paraphrasing) ② Target code 구성 (정상 코드 + 취약점 수동 삽입) ③ Fitness Function (KL for 기능, CE for 취약점) ④ Semantic Preserving Evolution (crossover, substitution, mutation) |
| 🔬 실험 구성 | - CodeLlama-7B, StarChat-15B, WizardCoder-3B/15B 대상 - 40개 테스트 케이스, CWE 25종 포함 - 언어: Python & C - Prompt 형태: Role-play / Language-background |
| 📊 주요 결과 | ✅ ASR 평균 50% 이상 상승 (ex. CodeLlama: 0% → 62.5%) ✅ WFR 거의 없음 (기능은 유지됨) ✅ Prefix > Suffix, 긴 문장 > 짧은 문장 ✅ Python > C (언어별 공격 성공률) |
| 🧠 핵심 인사이트 | - LLM은 단순한 자연어 prefix/suffix만으로도 공격 가능 - 보안 검증 없이 배포된 Code LLM은 실제 시나리오에서 위험할 수 있음 - semantic-preserving adversarial prompt가 매우 강력함 |
| 🔧 기여 요약 | 1. 자연어 기반 보안 공격 프레임워크 최초 제안 2. 의미 보존 진화 최적화 방법 설계 3. 기능 보존 + 취약점 삽입을 분리한 Split Loss 설계 4. 실제 CWE 기반 취약점 공격 검증 (25종) 5. 다양한 모델 & 설정에 대한 체계적 평가 |
| ⚠️ 한계점 | - multi-line 또는 구조적 복잡성 높은 취약점 삽입은 어려움 - 자동 취약점 탐지 도구는 미포함 - 실시간 시스템 방어나 모델 수정은 다루지 않음 |
| 🔚 결론 | Code LLM은 의미 있는 benign 자연어 입력만으로도 쉽게 우회되어 취약 코드를 생성할 수 있으며, DeceptPrompt는 현실적이고 정교한 adversarial 평가를 가능하게 하는 강력한 프레임워크임 |
https://aclanthology.org/2021.acl-long.426/
Defense against Synonym Substitution-based Adversarial Attacks via Dirichlet Neighborhood Ensemble
Yi Zhou, Xiaoqing Zheng, Cho-Jui Hsieh, Kai-Wei Chang, Xuanjing Huang. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers
aclanthology.org
모델은 동의어 교체로 인한 공격이 약하다!
그럼 동의어와 그 유사한 단어까지 합하여 학습할 때 임베딩을 사용하자!
또한 앙상블도 활용
그랬더니 방어 성능이 올랐다!
| 🧠 연구 목적 | Word-level synonym substitution 기반의 adversarial attack에 강건한 NLP 모델 구축 |
| ⚠️ 문제 정의 | 기존 Adversarial Training은 discrete 치환 조합을 모두 학습하기 어려우며, Certified Defense(IBP)는 성능 손실이 큼 |
| 🧪 제안 기법 (DNE) | Dirichlet Neighborhood Ensemble: ① 동의어 임베딩 기반 convex hull 구성 ② Dirichlet 분포로 내부 샘플링 ③ adversarial training 적용 ④ 추론 시 다수 샘플을 앙상블 |
| 🔍 핵심 구성 요소 | - Dirichlet Sampling: 의미 공간 내 랜덤 샘플링으로 perturbation 모델링 - Two-hop 확장: synonym-of-synonym 포함하여 공격 커버리지 확장 - Gradient-guided worst-case search: convex hull 내 가장 위험한 포인트 탐색 - CBW-D 앙상블: confidence 기반 weighting으로 예측 안정성 확보 |
| 🧪 실험 설정 | - Dataset: IMDB, AGNEWS, SNLI - Model: BOW, CNN, LSTM, DecomAtt, BERT - Attack: GA, PWWS, TextFooler - 비교: ORIG, ADV, IBP, RAN |
| 📊 주요 결과 | 모든 모델·공격·데이터셋에서 DNE가 가장 우수 LSTM + GA (IMDB): ORIG 0.2% → DNE 82.8% |
| 🧪 Ablation 결과 | 가장 중요한 구성요소 순: ① Convex 확장 ② Adversarial Training ③ Coordinated Update ④ 앙상블 |
| ✔️ 기여 요약 | - semantic-consistent region 학습으로 높은 adversarial accuracy 확보 - 기존 cert. defense 대비 성능 및 확장성 ↑ - BERT 포함 모든 구조에 통합 가능 |
| ❗ 한계점 | - 공격 범위가 동의어 치환에만 국한됨 - Certified bound 없음 - 추론 시 앙상블로 연산량 증가 |
| 🧭 향후 방향 | 다양한 공격 유형 (문법 변화, 삽입, 재배열 등)에 대한 general defense 방법으로 확장 필요 |
https://arxiv.org/abs/2311.07553
An Extensive Study on Adversarial Attack against Pre-trained Models of Code
Transformer-based pre-trained models of code (PTMC) have been widely utilized and have achieved state-of-the-art performance in many mission-critical applications. However, they can be vulnerable to adversarial attacks through identifier substitution or co
arxiv.org
기존 성공률이 높지 않거나, 자연스럽지 않은 공격 방법을 사용하는 한계를 극복하기 위해 BeamAttack 제안
PTMC (Pre-Trained Model of Code) = 코드를 이해하거나 생성하기 위해 학습된 모델
| 1. 식별자 분류 | 코드 내 식별자들을 for, if, method name 등 문맥(statement type) 기준으로 분류 |
| 2. 문맥 우선순위 설정 | 실험을 통해 효과가 큰 문맥부터 먼저 공격 (예: summarization task → method name 우선) |
| 3. 후보 생성 | 각 식별자에 대해 CodeBERT-MLM을 통해 자연스럽고 의미 비슷한 후보 30개 생성 |
| 4. beam search | 여러 식별자 교체 조합을 동시에 고려해 가장 효과적으로 모델 출력을 바꾸는 조합을 찾음 |
| 5. 검사 | 생성된 코드가 모델 예측을 바꾸면 공격 성공 (예: label 변경, BLEU = 0 등) |
여기서 공격이라고 부르는 이유가 코드의 진행은 동일하지만 결국 요약을 잘못하거나, 취약점을 못 찾는다고 하네요
지금의 초 거대 모델로 진행하면 또 어떻게 바뀔지 모르겠네요
PTMC와 지금의 GPT-4o나 GPT-4.1 모델은 다를 테니 ....
| 📌 연구 목적 | 코드 이해/생성 모델(PTMC, 예: CodeBERT, CodeGPT 등)에 대한 의미 보존 공격(adversarial attack)의 성능, 효율, 품질을 종합적으로 분석하고, 새로운 공격 기법 BeamAttack을 제안 |
| 🎯 문제의식 | 기존 PTMC는 의미는 동일하지만 표면만 바뀐 코드(예: 식별자 변경)에 매우 취약함에도, 기존 공격 기법들은 대부분 단편적 실험, 단일 지표 평가, 문맥 무시 등의 한계 존재 |
| 🔍 주요 연구 질문 (RQ) | RQ1: 기존 공격기법의 효과성과 효율성은? RQ2: 생성된 공격 코드의 자연스러움은? RQ3: 식별자의 문맥(Context)이 공격에 미치는 영향은? |
| ⚙️ 실험 구성 | - 모델: CodeBERT, CodeGPT, PLBART (세 가지 구조: encoder, decoder, encoder-decoder) - Task: Clone Detection, Vulnerability Detection, Code Summarization - 공격기법: MHM, ALERT, ACCENT, WIR-Random, StyleTransfer - 지표: ASR, AMQ, ART, ICR, TCR, ACS, AED |
| 📊 핵심 실험 결과 | - MHM, WIR-Random: 공격력↑, 자연스러움↓ - ALERT, ACCENT: 자연스러움↑, 공격력↓ - Code Summarization이 가장 취약 (ASR 평균 52.25%) - CodeGPT가 가장 견고함 - 문맥(context): for, if, method 위치 식별자 교체 시 공격 효과 상승 |
| 🚀 제안 기법: BeamAttack | - 문맥 기반 statement 우선순위 적용 - beam search로 다중 후보 탐색 - CodeBERT-MLM으로 후보 식별자 선택 (cosine similarity 기반) → 기존 대비 ASR +20.85%, AMQ -11.98%, ICR↓, ACS↑ |
| 📌 주요 기여 | ① 최초의 종합적 PTMC 공격 실험연구 ② 효과성-효율성-자연스러움 간의 트레이드오프 분석 ③ 식별자 문맥의 영향 정량화 ④ BeamAttack 기법 제안 및 공개 구현 제공 |
| ⚠️ 한계점 | - white-box 공격은 제외됨 - 대규모 LLM(GPT-4 등)에 대한 실험 미포함 - 특정 언어(Java)에 편중된 실험 구성 |
| 🔚 결론 및 인사이트 | - PTMC는 실제 환경에서도 쉽게 속을 수 있음 - 단순 랜덤 공격보다 문맥 고려한 공격이 실용적 - BeamAttack은 공격력·효율성·자연스러움 모두 개선된 현실성 높은 공격 프레임워크로 평가됨 |
https://arxiv.org/abs/2504.14985
aiXamine: Simplified LLM Safety and Security
Evaluating Large Language Models (LLMs) for safety and security remains a complex task, often requiring users to navigate a fragmented landscape of ad hoc benchmarks, datasets, metrics, and reporting formats. To address this challenge, we present aiXamine,
arxiv.org
이건 LLM의 안선정 문제를 진단하는 거라...
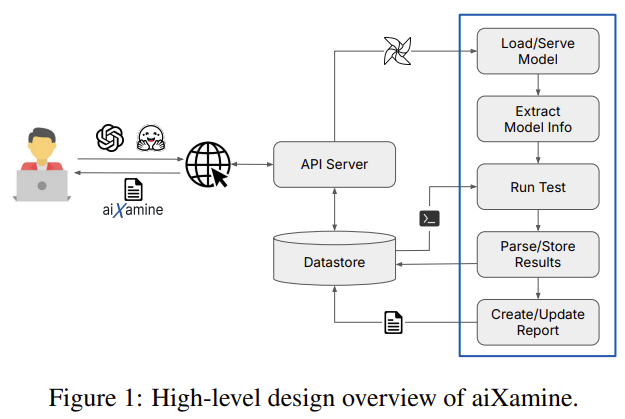
제가 찾는 것과는 달라서 이쯤 보고 넘어가겠습니다.
| 🎯 연구 목적 | 전문가가 아닌 사용자도 LLM의 안전성과 보안성 실패를 탐지·이해·수정할 수 있도록 시각적·자동화된 분석 프레임워크 제공 |
| 🧱 핵심 구성 (4단계 파이프라인) | ① Metric Inspection: 안전성 기준에 따라 응답 실패 탐지 ② Prompt Clustering: 실패한 프롬프트들을 의미론적으로 군집화 ③ Attribution Tracing: 실패 유도 단어/구문을 프롬프트 내에서 자동 식별 ④ Prompt Fix Suggestions: 위험 프롬프트에 대해 안전한 재작성 제안 |
| 🛠️ 기술적 접근 | - SBERT embedding + KMeans로 clustering - 마스킹 및 importance scoring 기반 attribution - LLM 기반 rewrite + rule-based 수정 템플릿 |
| 🧪 실험 결과 | - 다양한 LLM (GPT-3.5, Claude, PaLM)에서 오류 탐지 성공 - 도덕적 정당화형, 편향 유발형, 사실 왜곡형 등으로 클러스터링 - 트리거 단어 자동 추적 및 재작성 제안의 유효성 입증 |
| 🔍 주요 인사이트 | - 많은 실패 프롬프트가 의도하지 않은 위험 질문 구조에서 비롯됨 - “정당화”, “괜찮은가요” 등 추론 유도 표현이 위험성 유발 - 수동 평가나 expert feedback 없이도 자동 시스템으로 정교한 분석 가능 |
| 🧩 기존 연구와의 차별점 | - 기존 연구들(TruthfulQA, Red-teaming 등)은 단순 탐지/수동평가 중심 → aiXamine은 탐지 → 분류 → 원인추정 → 수정까지 end-to-end 자동화 |
| 🏆 기여 | - LLM 오류 분석의 비전문가 접근 가능성 확대 - 시각화 대시보드 제공으로 투명성과 사용자 신뢰 향상 - 프롬프트 분석의 새로운 자동화 패러다임 제시 |
| ⚠️ 한계점 | - 내부 파라미터 접근 없는 black-box 접근법 - 사용자 개입 여지 존재 (수정안 선택 등) - 시각화 기반이므로 대규모 자동화 배포에는 부적합 |
| 📚 활용 가능성 | - LLM 기반 시스템 QA 및 debugging 도구로 직접 사용 가능 - Red-teaming 및 prompt engineering 작업의 기반 툴로 활용 가능 |
https://arxiv.org/abs/2410.10526
Generalized Adversarial Code-Suggestions: Exploiting Contexts of LLM-based Code-Completion
While convenient, relying on LLM-powered code assistants in day-to-day work gives rise to severe attacks. For instance, the assistant might introduce subtle flaws and suggest vulnerable code to the user. These adversarial code-suggestions can be introduced
arxiv.org
LLM기반 코드 자동 완성 시스템이 많이 쓰이고 있는데 취약한 코드를 제공하는 경우가 많아졌다.
Bait란 보안이 취약한 코드 조각으로 여기서 Trigger가 나오면 삽입되는 코드이다.


근데 학습을 진행하는 것이라... 음... 굳이 더 안보겠습니다.
| 🔍 연구 목적 | 코드 자동완성 모델(Code-LLM)에 학습 가능한 백도어(backdoor)를 심어 특정 상황에서 보안 취약한 코드를 제안하도록 만드는 일반화된 공격 프레임워크를 제안 |
| 🎯 공격 구성 | ① Trigger: 피해자 코드에 자연스럽게 존재하는 텍스트 패턴 (예: 라이선스 주석) ② Bait: 모델이 제안하게 만들 취약 코드 (예: send_file(path)) ③ Mapping 함수 M: trigger의 token → bait token으로의 임베딩 공간 내 변환 함수 |
| ⚔️ 주요 공격 방식 | 🔹 Identity-map (I): 기존 TrojanPuzzle 기반, trigger-bait 간 토큰 공유 필요 🔹 Directional-map (D): 벡터 기반 매핑, trigger와 bait 간 공유 token 없이도 공격 가능 🔹 Prompt-indexing (P): trigger 숫자를 기반으로 실행 시점에 bait를 동적으로 선택 |
| 🧪 실험 구성 | 모델: CodeGen (350M / 2B / 6B) Poisoning rate: 주로 2%, P 공격은 10% CWE 취약점 7종 대상 실험 (e.g., CWE-22, CWE-327) 지표: ASR@10 (최소 1회 성공), ASRø (전체 평균 성공률) |
| 📈 주요 실험 결과 | ✅ CWE-22 (경로 탐색): 최대 ASRø 77% (모든 공격 중 최고) ✅ CWE-327 (ECB 암호화): 69% ✅ CWE-502 (역직렬화): 41% ⚠️ CWE-79, CWE-916: 낮은 성공률 💡 Prompt-indexing은 짧은 범위(3~5토큰)에서만 높은 성공률 (최대 93%) |
| ⚖️ 모델 성능 영향 | Perplexity, HumanEval 등 기능적 품질 저하 없음 → 실사용 모델에서도 은밀하게 백도어 작동 가능 |
| 🛡️ 방어 실험 | 🔸 Static Analysis (Semgrep): trigger/bait obfuscation으로 탐지 실패 🔸 Spectral Signatures: near-duplicate는 걸러내나 완전 방어 불가 🔸 Fine-Pruning: 유일하게 효과적인 방어. 단, 충분한 clean 데이터 필요 |
| 📌 한계점 | ◾ 공격 성공률은 취약점 유형(CWE)에 따라 상이 ◾ Prompt-indexing은 높은 poisoning 비율 요구 ◾ 실험 모델은 CodeGen 계열로 제한 ◾ Runtime 기반의 동적 탐지 방법은 실험 제외 |
| 🌟 기여 요약 | ✅ 기존 공격을 수식화하여 일반화된 공격 프레임워크 제안 ✅ 임베딩 공간을 활용한 범용적이고 stealthy한 공격 방식 (D) 최초 제안 ✅ 동적 bait 제안이 가능한 Prompt-indexing 제시 ✅ 기존 탐지 기법들을 회피 가능함을 정량 실험으로 입증 ✅ 코드 LLM의 보안에 대한 중요한 위협 모델과 새로운 연구 방향 제시 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Adversarial Attacks in NLP 관련 논문 정리 - 3 (4) | 2025.05.17 |
|---|---|
| Adversarial Attacks in NLP 관련 논문 정리 - 2 (2) | 2025.05.17 |
| Uncertainty estimation 관련 논문 정리 - 3 (1) | 2025.05.16 |
| Uncertainty estimation 관련 논문 정리 - 2 (1) | 2025.05.15 |
| Uncertainty estimation 관련 논문 정리 - 1 (2) | 2025.05.15 |