https://arxiv.org/abs/2310.12823
AgentTuning: Enabling Generalized Agent Abilities for LLMs
Open large language models (LLMs) with great performance in various tasks have significantly advanced the development of LLMs. However, they are far inferior to commercial models such as ChatGPT and GPT-4 when acting as agents to tackle complex tasks in th
arxiv.org
Agent Instruction dataset을 통해서 사고 과정을 학습하고, 일반 코퍼스 데이터를 통해 생성 능력 또한 유지했습니다.
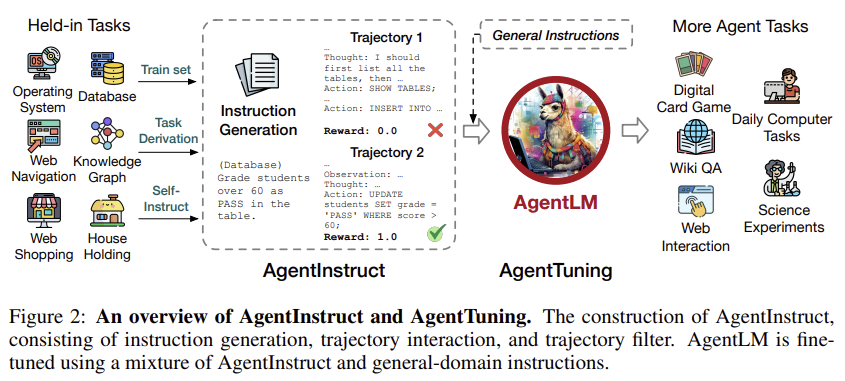
데이터는 지시문을 생성하고, 그 후 현재 상태-> 생각 -> 행동 -> 피드백 과정을 통해 작업 환경과 상호작용하도록 설계합니다. 마지막으로 필터링을 통해 고품질 데이터만 활용합니다.
Llama 2와 같은 오픈 소스 LLM을 통해 모델을 생성하여 일반 사람들이 좀 더 다양한 접근을 할 수 있도록 만들었습니다.
작은 모델(7B)와 같은 모델에선 성능 개선에 있어 한계를 보였습니다.
| 항목 | 설명 | 예시 / 세부 사항 |
| 주요 기여 | 일반화된 에이전트 역량 강화 및 상용 모델과의 격차 해소 | GPT-3.5와 비슷한 성능을 오픈 소스 LLM에서 달성 (AgentLM-70B) |
| 데이터 처리 단계 | 1. 지시문 생성 2. 상호작용 설계 3. 데이터 필터링 |
- 상태 → 생각(Thought) → 행동(Action) → 피드백 - 고품질 상호작용만 필터링 |
| 학습 전략 | 혼합 지시 튜닝 (Hybrid Instruction Tuning) | AgentInstruct 데이터(20%) + 일반 코퍼스 데이터(80%) |
| 기반 모델 | Llama 2 시리즈 | Llama-2-7B, 13B, 70B |
| 성능 요약 | - Held-in Tasks: AgentInstruct 내 작업 - Held-out Tasks: 새로운 작업 |
- Held-in: AgentLM(70B)이 GPT-3.5와 비슷한 성능 - Held-out: 70B에서 최대 176% 성능 향상 |
| 데이터 특징 | 다양한 작업 도메인과 CoT 방식 포함 | 웹 탐색, 데이터베이스 조작, 운영체제 상호작용 등 6개 도메인 |
| 강점 | - 일반화와 생성 능력 유지 - 데이터 품질 관리 철저 - 오픈 소스 접근성 제공 |
- 데이터 필터링으로 오류 감소 - GPT-3.5 수준의 대안 제공 |
| 한계 | - 작은 모델(7B)에서 성능 제한 - 대규모 모델(70B)에서만 일반화 성능 최적화 |
- 작은 모델에서도 성능을 높이기 위한 추가 전략 필요 |
| 발전 가능성 | - 멀티모달 통합 - 강화 학습과 메모리 모듈 추가 - Self-Instruct 방식 자동화 |
- 텍스트 + 비전 데이터를 통합한 범용 에이전트 설계 - 새로운 데이터 자동 생성 및 실시간 학습 가능 |


논문 요약: AgentTuning: Enabling Generalized Agent Abilities for LLMs
1. 해결하고자 한 문제
현재 오픈 소스 대형 언어 모델(LLMs)은 자연어 처리(NLP) 작업에서 우수한 성능을 보이지만, 에이전트 작업(complex tasks in real-world scenarios)에서는 상용 모델(GPT-3.5, GPT-4)에 비해 크게 뒤처짐. 에이전트 작업은 계획, 기억, 도구 활용 등을 요구하며, 이는 단순한 프롬프트 설계로 해결하기 어려움. 기존 연구들은 특정 에이전트 작업을 해결하는 데 초점을 맞췄지만, LLM 자체의 에이전트 역량을 일반화시키는 연구는 부족.
2. 제안한 방법
AgentTuning을 제안하여 LLM의 에이전트 역량을 강화하고, 이를 일반적인 LLM 기능 손실 없이 수행:
- AgentInstruct 데이터셋:
- 고품질 상호작용 경로(interaction trajectory) 1,866개로 구성된 가벼운 데이터셋.
- 여섯 가지 에이전트 작업(웹 탐색, 데이터베이스 조작 등)에 대해 다양한 상호작용 데이터를 포함.
- Chain-of-Thought(CoT) 방식으로 작업별 논리적 사고 과정을 포함.
- 혼합 지시 튜닝(hybrid instruction-tuning):
- 일반 도메인 데이터와 AgentInstruct를 혼합하여 지도 학습으로 LLM 튜닝.
- 에이전트 특화 데이터의 비율(η)을 조정해 성능 최적화.
- 모델 튜닝:
- Llama 2 시리즈(7B, 13B, 70B)를 기반으로 모델 생성(AgentLM).
- 효율적인 학습을 위해 메가트론(Megatron-LM) 활용.
3. 실험 결과
- 성능 평가:
- AgentBench를 활용해 평가.
- Held-in Tasks: AgentInstruct 데이터셋 내 작업.
- Held-out Tasks: 학습 데이터에 없는 새로운 작업.
- AgentLM은 GPT-3.5와 비슷한 성능을 보이며, 일반 LLM 작업에서도 성능 저하 없음.
- 오류 분석:
- 기존 Llama 2가 반복 오류와 포맷 문제를 자주 발생시켰지만, AgentLM은 이를 효과적으로 감소.
- 에이전트 작업의 성공률이 크게 향상.
- 일반화 성능:
- 에이전트 작업만으로 학습한 경우, 일반성과 확장성이 저하됨.
- 일반 데이터와 혼합 학습한 경우, 모든 작업에서 고른 성능을 보임.
4. 한계점 및 타당성
- 한계점:
- 데이터 구성:
- 특정 작업에서 데이터 누락 가능성(특히 Mind2Web 같은 작업은 단일 라운드로 구성되어 다양성 부족).
- 모델 크기의 중요성:
- 70B 모델에서만 성능 개선이 극대화됨. 따라서 작은 모델에서는 한계가 있음.
- 상용 모델과의 격차:
- GPT-4와 비교 시, 일부 작업에서 여전히 격차 존재.
- 데이터 구성:
- 타당성:
- 데이터 품질 관리(trajectory filtering), CoT 방식 적용, 다양한 작업 도메인을 포괄하는 AgentInstruct는 설계의 타당성을 높임.
- 일반 데이터와 혼합 튜닝 전략은 성능 보장과 일반화에 중요한 역할.
5. 아쉬운 점 및 향후 연구 방향
- 지속 학습:
- 에이전트의 지속적 환경 적응을 위해 온라인 학습 방식 추가 필요.
- 멀티모달 통합:
- 비전 데이터를 포함한 멀티모달 에이전트로 확장 가능.
- 독립적 의사결정 능력 강화:
- 에이전트가 인간 개입 없이 더욱 복잡한 작업을 수행할 수 있도록 강화 학습과의 통합 필요.
추후 연구를 위한 제안
이 논문을 기반으로, 다중 에이전트 시스템을 설계하는 연구를 제안:
- Fine-tuned LLM을 중앙 제어 시스템으로 활용:
- AgentLM을 기반으로 다중 에이전트를 조율하는 환경 설계.
- 학습 루프 자동화:
- 자체 데이터를 수집하고 학습하는 능력을 포함해 자기 개선(self-improving) AI 에이전트 구축.
- 협력적 AI 에이전트:
- NLP와 비전 모델을 결합해 서로 협력하는 AI 에이전트 네트워크를 연구.
추가적인 질문이나 논의 사항이 있다면 말씀해주세요!
이 논문과 연관된 논문에 대해 정리해줘
연관된 논문 요약
다음은 AgentTuning 논문에서 언급된 주요 연관 연구들의 개요입니다. 이들은 에이전트 및 LLM 성능 향상과 관련된 주요 개념들을 제시합니다.
1. LLM 기반 에이전트 연구
- ReAct (Yao et al., 2023):
- Chain-of-Thought(COT) 논리와 에이전트 행동을 결합한 접근법.
- 에이전트의 논리적 사고와 환경 상호작용을 통합하여 효율성을 높임.
- WebShop (Yao et al., 2022):
- 온라인 쇼핑 에이전트를 개발하기 위한 모델.
- 실제 웹 브라우저에서 사용자 요구를 충족시키는 기능을 평가.
- RCI (Kim et al., 2023):
- 모델 효율성을 높이는 프롬프트 설계 및 프레임워크.
- 특정 에이전트 작업에서 추가 훈련 없이 성능 강화.
2. Instruction Tuning 연구
- FLAN (Wei et al., 2022a):
- 다중 작업 데이터셋을 통해 LLM의 제로샷 일반화 능력을 향상.
- T0 (Sanh et al., 2022):
- 여러 지시 데이터를 활용하여 언어 모델이 인간 지시에 맞게 조정되도록 훈련.
- FLAN-V2 (Longpre et al., 2023):
- 대규모 모델 및 데이터셋에서 지시 튜닝 성능을 확장.
3. 데이터셋 기반 연구
- AgentBench (Liu et al., 2023):
- 에이전트 작업 성능을 비교하기 위한 벤치마크.
- 상용 LLM과 오픈 소스 LLM 간 성능 격차를 구체적으로 평가.
- Mind2Web (Deng et al., 2023):
- 단일 라운드 작업 데이터셋으로 웹 브라우저 기반 에이전트 평가.
4. 기타 중요한 연구
- ScienceWorld (Wang et al., 2022):
- 초등학생 수준의 과학 실험 수행 능력을 평가하는 에이전트 작업.
- 복잡한 논리 및 환경 상호작용을 요구.
- Self-Instruct (Wang et al., 2023c):
- LLM이 자체적으로 지시 데이터를 생성해 성능을 높이는 방법.
- 데이터 구축 자동화 가능성을 시사.
요약 및 적용 방안
이 논문들과 AgentTuning 연구는 다음과 같은 방향으로 확장 가능성을 제시합니다:
- 다중 에이전트 시스템 설계:
- WebShop, Mind2Web 같은 데이터셋을 활용해 다양한 작업에 맞는 에이전트 협력 연구.
- 강화학습 기반 통합:
- ReAct 및 ScienceWorld처럼 강화 학습을 통해 에이전트의 환경 적응성을 개선.
- 데이터셋의 확대:
- Self-Instruct 접근 방식을 통해 특화된 데이터를 더 많이 생성하여 모델 학습 강화.
추가로 연구 계획에 대해 논의하고 싶으시면 언제든 말씀해주세요!
그럼 내가 준 논문은 이 논문들에서 어떤 점을 발전해서 나온거야??
AgentTuning 논문은 기존 연구에서 다음과 같은 점을 발전시키며 나왔습니다:
1. 기존 연구의 한계
- 특정 작업에 초점:
- 이전 연구들은 주로 특정 에이전트 작업(WebShop, Mind2Web 등)을 해결하기 위해 설계되었으나, LLM의 일반화된 에이전트 역량 강화에는 초점을 두지 않음.
- 예: WebShop, Mind2Web은 각각 온라인 쇼핑과 웹 탐색이라는 구체적 작업에 국한.
- 프롬프트 설계에 집중:
- ReAct와 RCI와 같은 연구는 프롬프트나 특정 프레임워크 설계를 통해 LLM의 작업 효율을 개선하려 했으나, 모델 자체의 내재적 능력 강화는 이루어지지 않음.
- 데이터 품질 관리 미흡:
- 기존 데이터셋(예: AgentBench, Mind2Web)은 단일 라운드 데이터에 의존하거나 다양한 상호작용을 포괄하지 못함.
- 일부 연구(Self-Instruct)는 자동 생성 데이터를 사용했지만, 데이터 품질 관리가 부족해 모델 성능에 제약.
2. AgentTuning의 발전점
- 일반화된 에이전트 역량 강화:
- 특정 작업에 국한되지 않고, 여러 작업에 걸쳐 모델의 내재적 에이전트 역량을 강화.
- AgentInstruct 데이터셋을 통해 LLM이 다양한 작업 환경에서 적응할 수 있도록 학습.
- 혼합 튜닝 전략:
- 이전 연구에서는 에이전트 작업 또는 일반 작업 중 하나에 초점을 맞춘 학습이 주를 이룸.
- AgentTuning은 에이전트 특화 데이터(AgentInstruct)와 일반 도메인 데이터(ShareGPT)를 혼합하여, 두 작업 유형에서 모두 우수한 성능을 보이도록 함.
- 예: 특정 에이전트 작업에서의 성능이 개선되면서도 MMLU, GSM8K 같은 일반 작업에서도 성능 저하가 발생하지 않음.
- 고품질 데이터 생성 및 필터링:
- 데이터 생성 단계에서 Self-Instruct 및 Task Derivation 기법을 적용하여, 다양한 작업을 학습 가능하게 설계.
- Trajectory Filtering으로 데이터 품질을 철저히 관리해 모델 학습의 신뢰성을 높임.
- 다양한 작업 도메인 통합:
- 이전 연구들은 특정 작업(WebShop, ALFWorld 등)에 한정되었으나, AgentTuning은 6개의 다양한 작업(데이터베이스, 운영 체제, 웹 탐색 등)을 포괄하여 일반화를 보장.
- Chain-of-Thought(COT) 강화:
- ReAct 연구에서 제시된 논리적 사고(COT)를 확장하여, 모든 작업 경로에 COT 방식을 포함.
- 이는 모델이 논리적 사고를 기반으로 행동할 수 있도록 학습을 유도.
3. AgentTuning이 가져온 혁신
- 오픈 소스 모델 강화:
- 상용 모델(GPT-3.5, GPT-4)에 필적하는 성능을 오픈 소스 모델(Llama 2 기반)에서 구현.
- AgentLM-70B는 GPT-3.5와 Held-out 작업에서 유사한 성능을 보임.
- 범용 에이전트 시스템 구축 가능성:
- 특정 작업에 특화된 이전 연구와 달리, AgentTuning은 여러 작업에서 일반화된 성능을 제공해 범용 AI 에이전트 설계에 기여.
4. AgentTuning이 이전 연구 대비 보완한 점
| 기존 연구 | Agent Tuning의 개선 |
| 특정 작업만 해결 | 다중 작업에 대한 일반화 |
| 데이터 품질 관리 부족 | Trajectory Filtering으로 데이터 정제 |
| 프롬프트 설계에 집중 | 모델 자체의 에이전트 역량 강화 |
| 단일 라운드 작업 데이터 | 다중 라운드 작업 통합 |
| 에이전트 작업에 치중 | 일반 작업 성능 유지와 병행 |
5. 결론
AgentTuning은 기존 연구들의 주요 개념(ReAct의 COT, Self-Instruct 방식 등)을 통합하고, 모델의 내재적 능력 강화를 중심으로 발전시켰습니다. 이를 통해 상용 모델과의 격차를 줄이고, 범용 에이전트 연구를 위한 강력한 기반을 제공합니다.
추가적으로 논의하고 싶은 세부 주제가 있다면 말씀해주세요!
방법론에 대해 예시를 포함해서 자세하게 설명해줘
AgentTuning 방법론의 상세 설명
AgentTuning은 일반화된 에이전트 역량을 LLM에 부여하기 위해 두 가지 주요 구성요소와 단계를 활용합니다:
- AgentInstruct 데이터셋 구축
- 혼합 지시 튜닝(hybrid instruction tuning)
아래는 이 두 가지 과정에 대한 구체적인 설명과 예시입니다.
1. AgentInstruct 데이터셋 구축
AgentInstruct는 다양한 에이전트 작업에서 LLM이 훈련할 수 있도록 설계된 데이터셋으로, 상호작용 경로(interaction trajectory)와 Chain-of-Thought(CoT) 방식을 포함합니다. 이를 통해 모델이 에이전트 작업의 논리적 사고와 행동을 학습할 수 있습니다.
1.1 데이터 구축 단계
AgentInstruct 데이터셋은 다음 세 단계로 생성됩니다:
- 지시문 구성 (Instruction Construction):
- 목표: 다양한 작업에 대한 지시문을 생성.
- 작업:
- ALFWorld(가정용 작업), WebShop(온라인 쇼핑), Mind2Web(웹 탐색) 등 6가지 에이전트 작업을 포함.
- 예시:
Task: Daily Household Routines Instruction: “Put two soapbars in the garbagecan.”
- 상호작용 경로 생성 (Trajectory Interaction):
- 목표: 지시문에 따라 LLM이 작업 환경과 상호작용하도록 설계.
- 작업:
- LLM(GPT-4 또는 GPT-3.5)을 에이전트로 설정하고, 현재 상태 → 생각(Thought) → 행동(Action) → 피드백 과정을 반복.
- 예시:
Instruction: “Put two soapbars in the garbagecan.” - Thought: “I should find the soapbars first.” - Action: “Look for soapbars in the cabinet.” - Observation: “You see soapbars in the cabinet.”
- 데이터 필터링 (Trajectory Filtering):
- 목표: 작업 성공 여부에 따라 데이터를 평가하고, 고품질 데이터만 선택.
- 작업:
- 성공률이 높은 상호작용 경로를 필터링해 최종 데이터셋에 포함.
- 예시:
Task: "Retrieve ISO settings for a camera." - Reward: 1.0 (정확한 작업 수행).
1.2 데이터의 주요 특징
- 다양성:
- 6가지 에이전트 작업(운영체제 조작, 데이터베이스 조작 등) 포함.
- 예: 데이터베이스 작업에서 SQL 질의 생성 및 실행.
- Chain-of-Thought(COT):
- 각 행동 전에 논리적 사고 과정 기록.
- 예시:
Task: Update student grades in the database. - Thought: “I should check the table schema first.” - Action: “SHOW TABLES;” - Observation: “Table ‘students’ exists.”
2. 혼합 지시 튜닝 (Hybrid Instruction Tuning)
이 단계는 AgentInstruct 데이터와 일반 도메인 데이터를 혼합하여 LLM을 훈련하는 과정입니다.
2.1 목표
- 에이전트 작업 능력 강화: AgentInstruct 데이터로 작업 특화 학습.
- 일반화 성능 유지: 일반 도메인 데이터를 포함해 LLM의 기존 성능 유지.
2.2 학습 방식
- 데이터 혼합 비율 조정:
- 에이전트 데이터와 일반 데이터를 혼합.
- 최적 비율(η = 0.2)을 찾아 훈련.
- 수식: J(θ)=η⋅E(x,y)∼Dagent[logπθ(y∣x)]+(1−η)⋅E(x,y)∼Dgeneral[logπθ(y∣x)]
여기서 D_{agent}: AgentInstruct 데이터, D_{general}: 일반 데이터.
- 학습 설정:
- 기반 모델: Llama 2 시리즈(Llama-2-{7B, 13B, 70B}-chat).
- 튜닝 과정:
- AgentInstruct와 일반 데이터를 표준 대화 형식으로 통합.
- 모델의 출력에 대해 손실 함수 계산.

2.3 예시
- Agent 데이터 학습 예시:
Task: “Retrieve ISO settings for a camera.” - Input: “What ISO settings does Kodak EasyShare M753 support?” - Thought: “I should retrieve the ISO settings from the database.” - Action: “SELECT iso_settings FROM cameras WHERE model='Kodak EasyShare M753';” - Observation: “ISO settings retrieved successfully.” - 일반 데이터 학습 예시:
User: “Explain the difference between supervised and unsupervised learning.” Model: “Supervised learning involves labeled data, whereas unsupervised learning does not.”
3. 주요 차별점
- 고품질 데이터 활용: 필터링된 데이터로 학습해 오류 감소.
- 작업 간 상호 일반화: 하나의 작업에서 학습한 능력이 다른 작업에도 도움을 줌.
- 예: 데이터베이스 작업 학습 → 웹 탐색 작업 성능 개선.
4. AgentTuning의 강점
- 다양한 작업에 대한 일반화:
- 단순한 에이전트 작업 수행을 넘어, 여러 작업에서 안정적인 성능.
- Chain-of-Thought 기반 학습:
- 모델이 논리적 사고 과정을 통해 문제 해결.
- 효율적인 혼합 학습:
- 일반 데이터와 특화 데이터를 결합하여 모든 작업에서 성능 유지.
이 방법론은 범용 AI 에이전트를 설계하는 데 강력한 기반을 제공합니다. 추가적으로 논의가 필요한 부분이 있으면 말씀해주세요!
결과와 마무리에 대해 상세하게 정리해줘
결과 및 마무리: AgentTuning
1. 결과 요약
1.1 Held-in Tasks (AgentInstruct 데이터셋 내 작업)
- 성능:
- AgentLM(7B, 13B, 70B)은 모든 작업에서 Llama 2 대비 큰 성능 향상.
- 특히 70B 모델은 일부 작업에서 GPT-3.5와 유사한 성능을 달성.
- 성공 사례:
- 예: ALFWorld(가정 작업)에서 AgentLM-70B는 Llama 2 대비 84% 높은 성공률.
- 주요 관찰:
- AgentTuning은 데이터 필터링과 Chain-of-Thought 방식을 통해 오류를 크게 감소.
- 포맷 오류, 중복 응답 오류 등이 줄어들며, 모델이 논리적이고 체계적으로 작업 수행.
1.2 Held-out Tasks (새로운 작업)
- 성능:
- 학습하지 않은 새로운 작업에서도 70B 모델이 GPT-3.5와 비교 가능한 성능을 보임.
- 예: SciWorld(과학 실험)에서 +176% 성능 향상.
- 관찰:
- 70B 모델에서만 성능 극대화:
- 7B 모델은 Generalization(일반화)이 제한적.
- 대규모 모델이 작업 전이 및 확장성에서 유리.
- 70B 모델에서만 성능 극대화:
1.3 일반 작업 성능
- MMLU, GSM8K, HumanEval 등 일반 작업에서도 성능 저하 없음.
- AgentLM은 혼합 튜닝(hybrid instruction tuning) 전략 덕분에 일반 LLM 능력을 유지.
1.4 오류 분석
- Llama 2:
- 반복 오류, 포맷 오류, 기본적인 에이전트 행동 실패 빈도가 높음.
- AgentLM:
- AgentTuning을 통해 초보적인 오류가 크게 줄어듦.
- 예: ALFWorld에서 작업 실패율이 크게 감소.
2. 성능 데이터 요약
| 모델 | Held-in 점수 | Held-out 점수 | 일반 작업 점수 |
| Llama 2 (7B) | 0.19 | 0.38 | 0.63 |
| AgentLM (7B) | 1.96 | 0.67 | 0.62 |
| AgentLM (70B) | 2.55 | 1.40 | 0.96 |
3. AgentTuning의 강점
3.1 일반화된 에이전트 역량
- 상용 모델(GPT-3.5, GPT-4)에 근접한 성능으로 오픈 소스 모델의 한계를 극복.
- 다양한 작업 도메인(웹 탐색, 데이터베이스 조작 등)에서 고른 성능을 보이며 범용 AI 에이전트 설계 가능성을 입증.
3.2 효율적인 데이터 사용
- AgentInstruct 데이터셋은 적은 양(1,866 경로)으로도 높은 품질을 유지하며 모델 학습을 최적화.
- 데이터 필터링 및 COT 기반 학습은 모델의 사고 능력을 크게 강화.
3.3 모델 확장성
- 7B에서 70B까지 모델 크기 확장 시 성능이 비례적으로 증가.
- 특히 70B 모델은 학습하지 않은 작업에서도 높은 일반화 능력을 발휘.
4. 한계점
4.1 작은 모델의 제약
- 7B와 13B 모델은 일반화 성능에서 제한적.
- 일반화된 에이전트 역량을 발휘하려면 70B 이상의 대규모 모델이 필요.
4.2 데이터 의존성
- 데이터셋이 특정 도메인에 치우칠 경우, 다른 도메인에서 성능 저하 가능성.
- 예: Mind2Web 데이터는 단일 라운드 작업으로 다양성이 부족.
4.3 상용 모델과의 격차
- GPT-4와 비교 시, 일부 작업(특히 고난이도 작업)에서 여전히 격차가 존재.
5. 결론 및 의의
5.1 의미 있는 성과
- AgentTuning은 오픈 소스 LLM을 상용 모델 수준으로 끌어올리는 중요한 첫걸음.
- 범용 에이전트 설계의 실현 가능성을 제시하며, 연구 커뮤니티에 강력한 도구를 제공.
5.2 AI 에이전트 연구의 새로운 방향
- 범용 에이전트 설계:
- 다양한 작업 환경에서도 안정적으로 수행 가능한 모델 구축.
- 자동화 학습 시스템:
- Self-Instruct 방식과 AgentInstruct를 기반으로, 지속적인 데이터 생성 및 학습 가능.
- 강화 학습과의 통합:
- 에이전트가 더 복잡한 작업을 수행할 수 있도록 강화 학습 기법 적용.
AgentTuning은 AI 에이전트 연구에서 중요한 진전을 보여줍니다. 이 논문을 기반으로 구체적인 연구 계획이나 실험 아이디어를 논의하고 싶으시면 말씀해주세요!
논문이 타당한지와 발전시킬 점에 대해 정리해줘
논문의 타당성과 발전 가능성
1. 타당성 분석
1.1 방법론적 타당성
- 혼합 지시 튜닝(Hybrid Instruction Tuning):
- AgentInstruct와 일반 데이터를 혼합하여 에이전트 역량과 일반 LLM 능력을 동시에 유지.
- 실험 결과에서 일반 작업(MMLU 등) 성능 저하가 없음을 입증, 이 접근법의 효율성과 설계의 타당성을 보여줌.
- Chain-of-Thought(COT) 기반 학습:
- 작업 수행 과정에서 논리적 사고를 강조하여 모델이 작업의 의도를 이해하고 행동할 수 있게 만듦.
- 이는 인간 사고 방식과 유사한 방식으로 모델을 학습시키는 유효한 접근.
1.2 실험과 결과의 신뢰성
- AgentBench를 활용한 평가:
- 다양한 도메인 작업에서 성능 평가(웹 탐색, 데이터베이스 조작 등), 객관적이고 공정한 평가 기준 활용.
- 데이터 품질 관리:
- 필터링된 데이터만 사용하여 학습, 노이즈 데이터가 성능에 미치는 영향을 최소화.
- 오픈 소스 모델 활용:
- 상용 모델(GPT-3.5, GPT-4)과 비교 가능성을 입증하며, 연구 커뮤니티에서 재현 가능.
1.3 결과의 의의
- 오픈 소스 모델에서 GPT-3.5와 비슷한 성능을 달성, 상용 모델 의존도를 줄일 수 있는 가능성을 제시.
- 특정 작업뿐만 아니라, 새로운 작업(held-out tasks)에서도 높은 성능을 발휘하며 모델의 일반화 역량을 입증.
2. 발전시킬 점
2.1 작은 모델의 한계 극복
- 문제: 7B 및 13B 모델에서 일반화 능력이 제한적이며, 70B 모델에서만 큰 성능 개선.
- 발전 방향:
- 작은 모델에서도 일반화 성능을 높이기 위해 지능적인 데이터 선택 및 훈련 전략 도입 필요.
- 예: Curriculum Learning(점진적 학습)을 통해 작은 모델의 학습 단계를 세분화.
2.2 데이터 다양성 및 확장
- 문제: 일부 작업(Mind2Web)은 단일 라운드 상호작용으로 구성, 다양한 환경을 반영하지 못함.
- 발전 방향:
- 다양한 멀티모달 데이터(텍스트, 이미지, 음성 등)를 통합하여 복합 작업 처리 능력 강화.
- 예: 자율 주행 차량 데이터, 로봇 조작 환경 데이터 추가.
2.3 상용 모델과의 격차 축소
- 문제: GPT-4와 비교 시 여전히 고난이도 작업에서 성능 격차.
- 발전 방향:
- 강화 학습(RLHF)과 통합:
- 에이전트 작업의 성공률을 높이기 위해 환경과의 상호작용을 강화 학습으로 최적화.
- 메모리 기반 시스템:
- 작업 이력을 기억하여 장기적인 의사결정을 가능하게 하는 메모리 모듈 추가.
- 강화 학습(RLHF)과 통합:
2.4 추론 능력 개선
- 문제: 일부 작업에서 논리적 추론 부족(예: 복잡한 데이터베이스 작업).
- 발전 방향:
- Symbolic Reasoning을 통합:
- 추론 과정을 강화하기 위해 기호적 추론(symbolic reasoning) 기법 추가.
- Multi-step Reasoning 강화:
- 다단계 추론이 필요한 작업에서 성능을 높이기 위해 추가적인 CoT 학습 데이터 생성.
- Symbolic Reasoning을 통합:
2.5 지속적 학습(Self-improving AI)
- 문제: 새로운 환경에 적응하려면 지속적 재학습 필요.
- 발전 방향:
- Self-instruct 방식의 자동화:
- AgentInstruct 데이터 구축 방식을 자동화하여 지속적으로 새로운 작업 데이터를 생성.
- 예: 환경 변화에 따라 데이터를 수집하고, 이를 활용해 실시간 학습.
- Self-instruct 방식의 자동화:
3. AgentTuning의 확장 가능성
- 멀티모달 에이전트 설계:
- NLP 외에도 비전 및 음성 데이터를 통합한 에이전트 설계 가능.
- 다중 에이전트 협력 시스템:
- 여러 LLM 기반 에이전트를 협력하게 하여 복잡한 작업을 처리.
- 실시간 환경 적응 AI:
- 지속적으로 데이터를 수집하고 환경에 적응하는 자기 개선(Self-improving) 시스템 설계.
결론
AgentTuning 논문은 타당한 이론과 실험을 바탕으로 상용 모델에 의존하지 않는 일반화된 에이전트 설계의 가능성을 열었습니다. 이를 기반으로:
- 작은 모델에서의 일반화 강화,
- 멀티모달 확장,
- 강화 학습 및 지속적 학습 통합 등이 발전 방향으로 제안될 수 있습니다.
추가 논의나 구현 계획이 필요하면 말씀해주세요!
전체적으로 논문의 주요 내용을 간결하게 잘 요약했습니다. 그러나 일부 설명에서 구체성이 부족하고, 논문에서 다루어진 중요한 세부 사항들이 빠진 부분이 있습니다. 아래는 원래 작성한 내용을 보완하고 구조를 다듬은 수정 버전입니다:
수정된 내용:
AgentTuning은 AgentInstruct 데이터셋을 활용하여 에이전트 작업에서 필요한 논리적 사고 과정을 학습하는 동시에, 일반 코퍼스 데이터를 혼합하여 모델의 생성 능력과 일반화 성능을 유지합니다.
- 데이터 생성 과정:
- 지시문 생성: 다양한 에이전트 작업에 대한 지시문을 작성.
- 상호작용 설계:
- 현재 상태 → 생각(Thought) → 행동(Action) → 피드백(Observation)의 체계적 과정을 통해 작업 환경과 상호작용.
- Chain-of-Thought(CoT) 방식을 적용하여 논리적 사고와 행동을 학습.
- 데이터 필터링: 상호작용 결과를 평가하여 고품질 데이터만 선택.
- 오픈 소스 LLM 기반 모델 개발:
- Llama 2와 같은 오픈 소스 모델을 기반으로 AgentLM(7B, 13B, 70B) 모델을 생성.
- 이를 통해 상용 모델(GPT-3.5, GPT-4)에 접근하기 어려운 연구 커뮤니티와 일반 사용자들이 보다 다양한 활용을 가능하게 함.
- 성능 한계:
- 작은 모델(7B)에서는 성능 개선에 한계가 있으며, 70B 모델에서만 GPT-3.5에 필적하는 성능을 달성.
- 모델 크기가 성능 일반화 및 전이에 중요한 역할을 한다는 점을 확인.
주요 수정 및 추가 내용
- CoT 방식과 상호작용 구조:
- "현재 상태 → 생각 → 행동 → 피드백"의 구체적인 프로세스를 명확히 설명.
- 필터링 과정 강조:
- 데이터 품질 관리가 성능 개선에 중요한 요소임을 부각.
- 오픈 소스 접근성의 의의:
- 오픈 소스 모델을 활용한 이유와 장점을 추가 설명.
- 모델 크기와 성능의 상관관계:
- 작은 모델에서의 한계를 구체적으로 언급.
이 버전은 원래 내용의 요점을 유지하면서 논문의 핵심 내용을 좀 더 구체적이고 체계적으로 전달합니다. 추가적으로 보완할 내용이 필요하면 말씀해주세요!