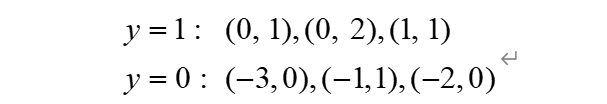1강 - 강화학습이란 강화학습 = Trial and Error을 통해 학습하는 방법 순차적 의사 결정 문제 = 시간 순서대로 주어진 상황에서 목적에 도달하기 위한 행동을 취하고, 그에 변화한 상황을 근거로 다시 행동을 취한다. 보상 == 피드백 = 의사 결정을 했을 때 잘 했는지 못했는지를 알려주는 수치(스칼라 값) 보상은 지연될 수 있으며, 어떤 행동으로 인해 보상으로 주어졌는지 판단을 나중에 할 수 있다. 강화학습 목적 = 누적 보상의 최대화 에이전트 == 학습자 = 현재상황 St에서 At를 결정한다. 그럼 그에 따른 보상 R(t+1)을 받고 다음 상태S(t+1)의 정보를 받는다. 환경 = 에이전트를 제외한 모든 요소 강화 학습의 장점 - 병렬성, 자가학습 2강 - 마르코프 결정 프로세스 마르코프 프..