728x90
728x90


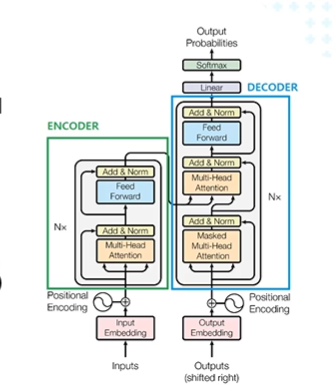
positional Encoding - 임베딩된 단어 정보에 위치 정보 추가



디코더

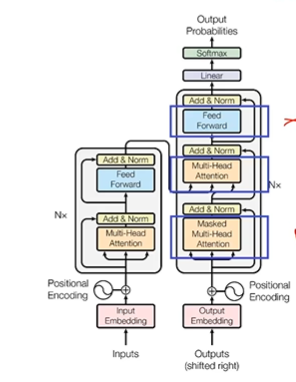

GPT 는 더 개선된 Transformer 구조를 보인다.


Soft-max == 정규화


728x90
'인공지능 > 공부' 카테고리의 다른 글
| 강화 학습 복습 2 (0) | 2024.03.27 |
|---|---|
| 생성형 인공지능 퀴즈 4 (3) | 2024.03.27 |
| 생성형 인공지능 4주차 Transformer 4차시 - Multi-Head Attention 다중머리 주의 (0) | 2024.03.26 |
| 생성형 인공지능 4주차 Transformer 3차시 - Self-Attention 2 자기 주의 (0) | 2024.03.26 |
| 생성형 인공지능 4주차 Transformer 2차시 - Self-Attention 1 자기 주의 (0) | 2024.03.26 |