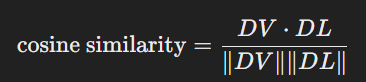https://ku-cvlab.github.io/CAT-Seg/ CAT-Seg🐱: Cost Aggregation for Open-Vocabulary Semantic Segmentation ku-cvlab.github.io 더보기요약오픈 보캐뷸러리 의미 분할(Open-Vocabulary Semantic Segmentation)은 이미지 내 각 픽셀을 텍스트 설명에 기반한 클래스 레이블로 지정하는 문제입니다. 이 논문은 CLIP 모델을 기반으로 이미지와 텍스트 임베딩 간의 코사인 유사도 점수(비용 볼륨)를 집계하는 새로운 방법을 제안합니다. 이 방법은 기존 모델들이 보지 못한 클래스에 대한 처리 문제를 해결하며, CLIP의 인코더를 미세 조정하여 세분화 작업에 적응시킵니다.주요 내용오픈 보캐뷸러리 의미 ..