https://kimmanjin.github.io/structsa/
논문 요약:
Learning Correlation Structures for Vision Transformers
주요 내용 요약:
이 논문은 구조적 자기-어텐션(StructSA)이라는 새로운 어텐션 메커니즘을 소개합니다. 이는 시각적 표현 학습을 위해 쿼리와 키의 상호작용에서 자연스럽게 나타나는 풍부한 상관 구조를 활용합니다. StructSA는 컨볼루션을 통해 공간-시간 구조를 인식하여 어텐션 맵을 생성하고, 이를 사용하여 값 피처의 로컬 컨텍스트를 동적으로 집계합니다. 이를 통해 이미지와 비디오에서 장면 배치, 객체 움직임, 객체 간 관계와 같은 다양한 구조적 패턴을 효과적으로 활용할 수 있습니다. StructSA를 주요 구성 요소로 사용하는 구조적 비전 트랜스포머(StructViT)를 개발하여, 이미지와 비디오 분류 작업에서 최첨단 성능을 달성했습니다.
중요한 내용 정리:
- 배경 및 필요성:
- 시공간에서 시각적 요소가 서로 어떻게 상호작용하는지는 시각적 이해에 중요한 단서입니다.
- 컴퓨터 비전에서 이러한 관계 패턴은 이미지와 비디오의 다양한 구조적 패턴을 효과적으로 포착합니다.
- 방법론:
- StructSA는 쿼리-키 상관 구조의 공간-시간 패턴을 인식하여 어텐션 맵을 생성하고 이를 기반으로 값 피처의 로컬 컨텍스트를 동적으로 집계합니다.
- 이 메커니즘은 두 단계로 구성됩니다: (i) 구조적 쿼리-키 어텐션 (ii) 컨텍스트 값 집계.
- StructSA는 긴 범위의 컨볼루션 상호작용과 동적 컨텍스트 피처 집계를 통해 이미지와 비디오에서 풍부한 구조적 패턴을 포착합니다.
- 기술적 기여:
- StructSA는 쿼리-키 상관 구조를 학습하여 비전 트랜스포머의 시각적 표현 학습을 향상시킵니다.
- 다양한 컨볼루션 프로젝션을 사용하는 최근의 자기-어텐션 변형과 StructSA 간의 관계를 심층 분석했습니다.
- 새로운 트랜스포머 네트워크는 ImageNet-1K, Kinetics-400, Something-Something V1 & V2, Diving-48, FineGym 등의 데이터셋에서 최첨단 성능을 달성했습니다.
결론:
StructSA는 시각적 표현 학습을 위한 새로운 자기-어텐션 메커니즘으로, 쿼리-키 상관 구조의 공간-시간 패턴을 활용하여 이미지와 비디오 분류 작업에서 최첨단 성능을 달성합니다. StructViT는 StructSA를 주요 구성 요소로 사용하여, 다양한 이미지와 비디오 분류 데이터셋에서 우수한 성능을 보였습니다. 이 메커니즘은 시각적 데이터의 구조적 패턴을 인식하고 활용함으로써, 비전 트랜스포머의 성능을 크게 향상시킬 수 있음을 보여줍니다.
dubbed structural self-attention(StructSA)라는 새로운 attention 메커니즘이 나왔다. Query와 Key의 attention연산에서 나타나는 상관 구조(?)를 활용한다.
Convolution 연산을 통해 Query와 Key의 시, 공간 구조를 attention map를 만들어 Value feature의 지역적 문맥에 동적으로 사용된다.
이를 통해 이미지와 비디오의 구조적 패턴을 효과적으로 사용한다.
StructSA를 통해 StructViT 개발
기존의 attention은 각 입력 요소가 자기 자신을 포함해서 모든 요소들과의 관계를 계산한다. 이를 통해 문맥을 계산하는데 도움을 준다.
시간 복잡도 : 입력 시퀸스의 길이 ^2 * 차원 수
공간 복잡도 : 입력 시퀸스의 길이 ^2
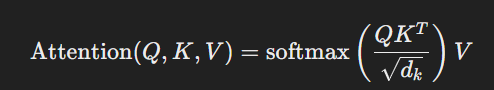
StructSA는 쿼리와 키의 관계를 구조적 패턴으로 인식하여 attention map을 형성하여 공간적, 시간적 패턴을 동시에 인식
시간, 공간 복잡도가 attention에 비해 크다.
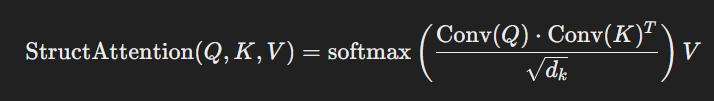
| 입력 | 시퀀스 𝑋=[𝑥1,𝑥2,...,𝑥𝑛] | 시퀀스 𝑋=[𝑥1,𝑥2,...,𝑥𝑛] 및 구조적 패턴 정보 |
| 쿼리, 키, 값 생성 | 𝑄=𝑋𝑊𝑄,𝐾=𝑋𝑊𝐾,𝑉=𝑋𝑊𝑉 | 동일 |
| 스코어 계산 | 𝑄𝐾𝑇𝑑𝑘 | Conv(𝑄)⋅Conv(𝐾)𝑇𝑑𝑘 |
| 정규화 | 소프트맥스 적용 | 소프트맥스 적용 |
| 출력 계산 | softmax(𝑄𝐾𝑇𝑑𝑘)𝑉 | softmax(Conv(𝑄)⋅Conv(𝐾)𝑇𝑑𝑘)𝑉 |
https://github.com/KimManjin/StructViT
GitHub - KimManjin/StructViT: The official repository of the paper "Learning Correlation Structures for Vision Transformers" acc
The official repository of the paper "Learning Correlation Structures for Vision Transformers" accepted to CVPR 2024. - KimManjin/StructViT
github.com
앗.....

다음에 나오면 진행하는 걸로.......ㅠ