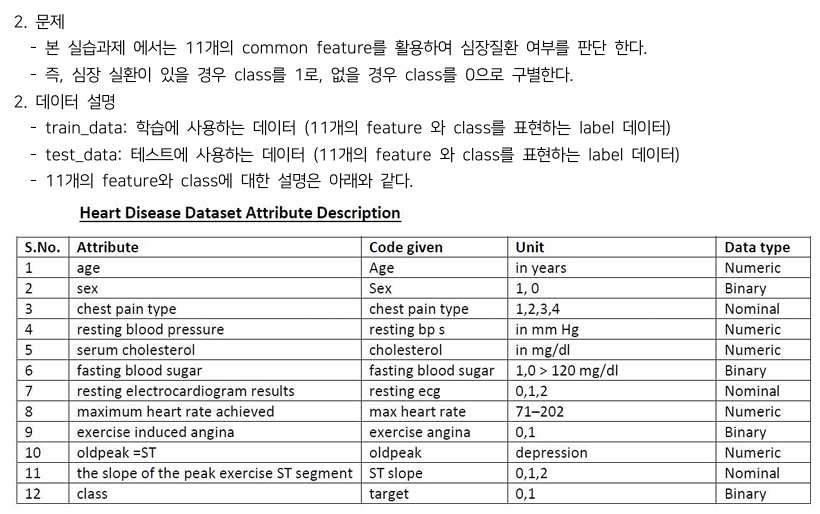
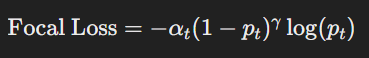https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 SonnetAuthors Adly Templeton*, Tom Conerly*, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, Alex Tamkin, Esin ..