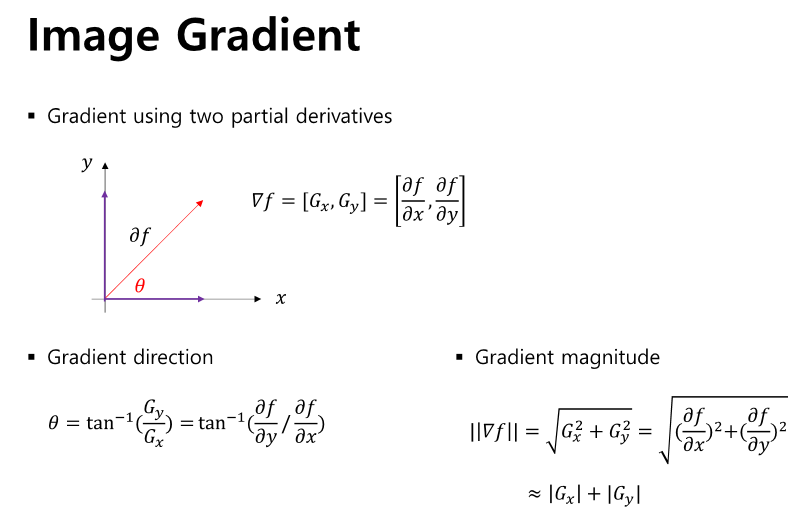
edge는 명암, 휘도 등이 급격하게 변하는 곳 입니다.만약 물체가 동일한 색 이라면 경계의 색 차이가 크게 나지 않겠지요 ..그래도 색 차이가 큰 곳에서는 대부분 경계가 잘 드러납니다.x,y에 대한 기울기를 통해 구할 수 있습니다.우리는 영상을 사용하므로 딱딱 끊어져 있으므로 center를 통해 구할 수 있습니다.임계값보다 크면 edge로 판단할 수 있는데 이 임계값이 문제네요threshold값을 보면 엄청 작은 것을 알 수 있다.threshold값을 넘는 것을 edge로 보고 확실하게 표시하도록 하겠다.오............ㅠ......엣지를 잘 따는 것 같기는 한데....노이즈가 슬슬 끼네요....어우 무섭네...원본 edge가 이정도인걸 보면 그래도 많이 살렸네요흠....이건 그래도 저장 했으니..