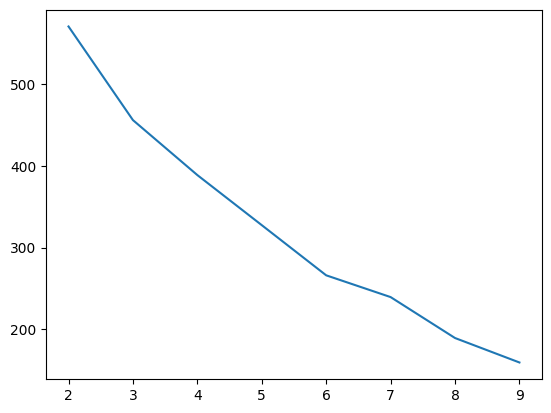
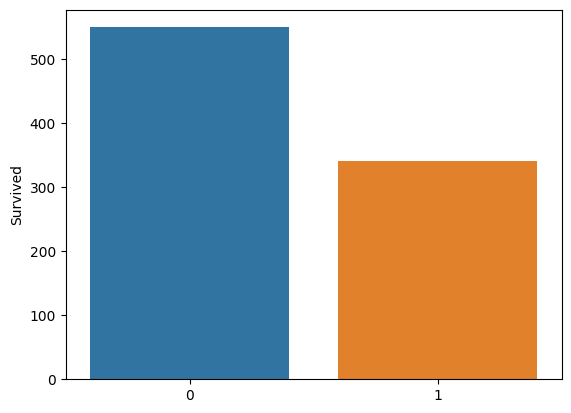
from google.colab import drive drive.mount('/content/drive') import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns data = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/titanic.csv') data = data.drop(['Name','Ticket'],axis=1) # 이름과 티켓 값은 생존과 관련 없기 때문이다. data = pd.get_dummies(data,columns=['Sex','Embarked'],drop_first = True)# 데이터 세분화 하면서 데이터 갯수 줄이기 (남자..