728x90
728x90

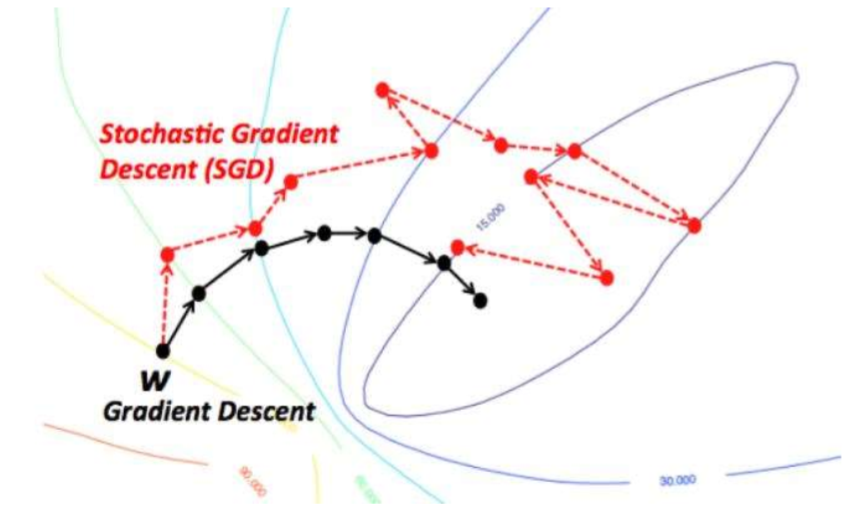
SGD - 샘플마다 업데이트하기 때문에 진동이 크다!

모든 샘플을 다 사용하는 batch learning!(epoch learning)
local min에 빠질 위험이 크다!

두가지를 섞어서!
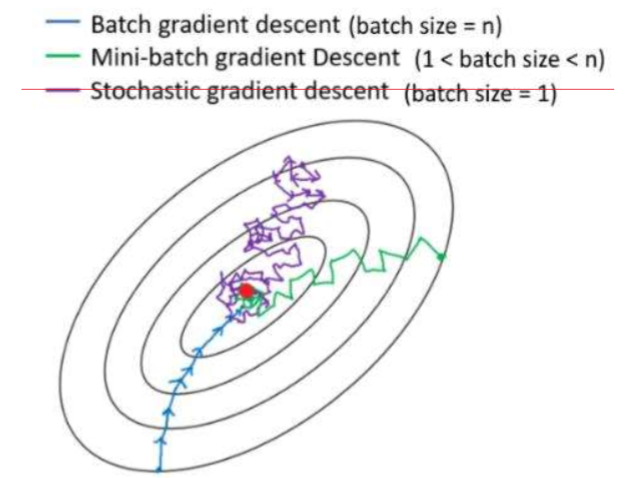


parameter update = 최적화





오버피팅, 과적합


주황색이 test data겠네요


오버피팅 된 weight의 값은 크다 -> weight의 값을 감소시킨다.






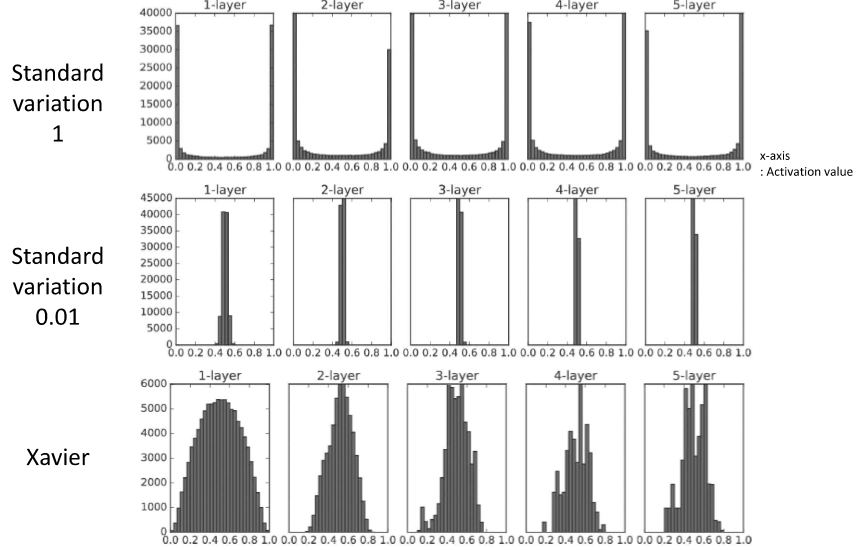
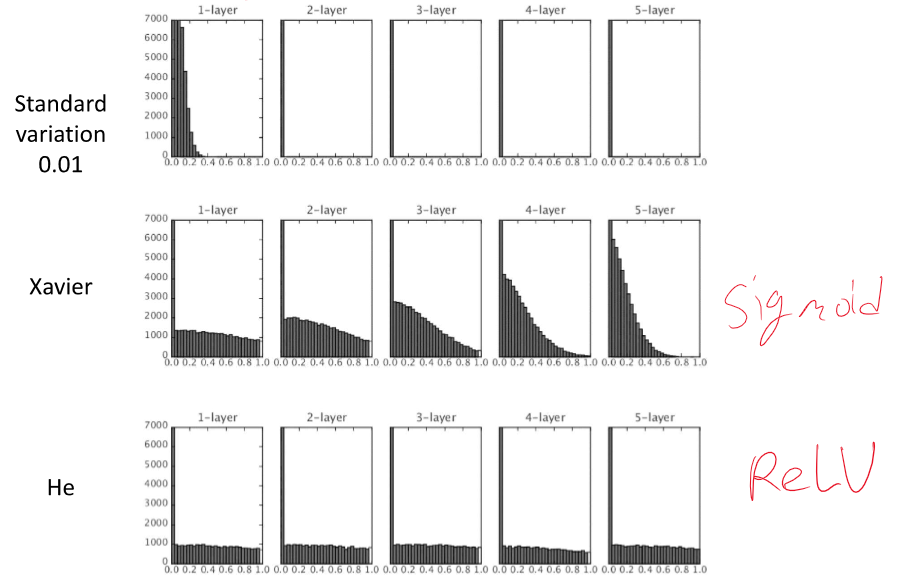

오버피팅 방지, 학습 다향성 증가
728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 정리 - 8강 Machine Translation with RNN (0) | 2024.04.13 |
|---|---|
| 자연어 처리 정리 - 7강 Text classification with CNN (0) | 2024.04.13 |
| 자연어 처리 5강 - Deep Learning Recap 1 (0) | 2024.04.12 |
| 자연어 처리 정리 - 4강 word embedding 2 (0) | 2024.04.12 |
| 자연어 처리 정리 - 3강 Word embedding 1 (1) | 2024.04.12 |