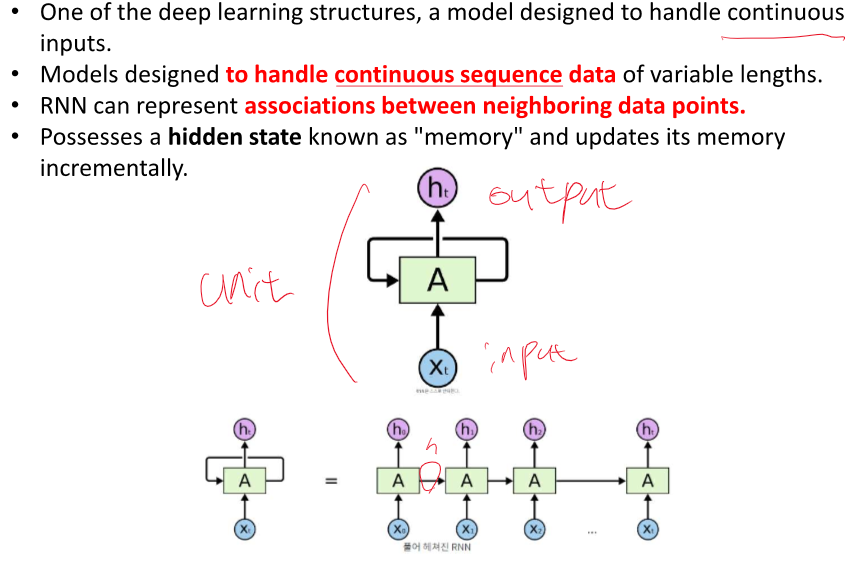
continuous inputs - time series - 날짜, 주가 등 시간의 순서가 있는 data

마지막은 각각의 인풋이 새로운 결과를 만든다.


여기서 Whh, Wxh, Wyh 등 모든 파라미터는 이전 에 사용했던 것과 동일하다.
기본적인 RNN 구조에서 parameter vector는 입력에 한개, 이전 입력에 대해 넘어 오는 것에서 한개, 출력으로 보내는 것에 한 개 있잖아
그럼 이 파라미터들은 t-1 시점이랑 t 시점이랑 값이 똑같은거야?
기본적인 RNN(Recurrent Neural Network) 구조에서는 시간에 따라 입력되는 다양한 시점의 데이터를 처리할 때, 모든 시점에서 같은 파라미터(가중치)를 공유합니다. 이는 RNN의 핵심 특징 중 하나로, 시간적으로 연속적인 데이터를 처리할 수 있게 해줍니다.
RNN에서 주로 다루는 파라미터 벡터는 다음과 같습니다:
1. **입력 가중치(W<sub>x</sub>):** 현재 시점의 입력 데이터를 변환하는 데 사용되는 가중치입니다.
2. **은닉 상태 가중치(W<sub>h</sub>):** 이전 시점의 은닉 상태(출력)를 현재 시점의 은닉 상태 계산에 사용하는 가중치입니다.
3. **바이어스(b):** 은닉 상태 계산에 추가되는 바이어스 값입니다.
이들 파라미터는 RNN의 모든 시점에서 동일하게 적용됩니다. 예를 들어, 시간 t-1에서의 계산과 시간 t에서의 계산은 같은 W<sub>x</sub>, W<sub>h</sub>, 및 b를 사용하여 수행됩니다. 이를 통해 모델은 시간에 따른 일관성을 유지하며, 학습해야 할 파라미터의 수를 크게 줄일 수 있습니다.
이러한 파라미터 공유 방식은 RNN이 긴 시퀀스 데이터를 처리할 때 일관된 방식으로 정보를 전달하고, 이전 시점의 정보를 현재 시점에 효과적으로 통합할 수 있도록 해줍니다. 그 결과, RNN은 시간에 따라 변화하는 데이터 패턴을 학습하고 예측하는 데 효과적입니다.




여기서도 패딩을 해준다.

2,3개 정도가 좋다. 너무 깊어지면 overfitting 발생
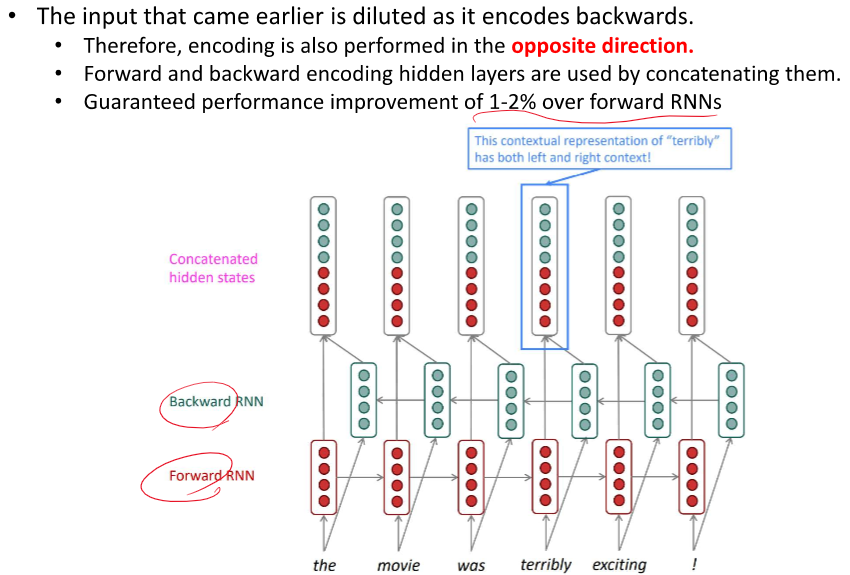
ELMo가 양방향 다 사용했던 것 같네요
2024.03.24 - [인공지능/자연어 처리] - 자연어 처리 문장 embedding만들기 - ELMo
자연어 처리 문장 embedding만들기 - ELMo
와이파이 불안정으로 이전 정보가 다 날라갔네여...ㅠ 일단 하는거 부터 하고 나중에 다시 작성하던가 할게요... 문맥 정보를 포함하는 것이 도움이 된다 ! 어떤 자연어 처리 방식에 따라 필요한
yoonschallenge.tistory.com

이전의 정보를 가지고 온다 -> 먼 정보는 희미해진다.(사라진다, 희석된다....)
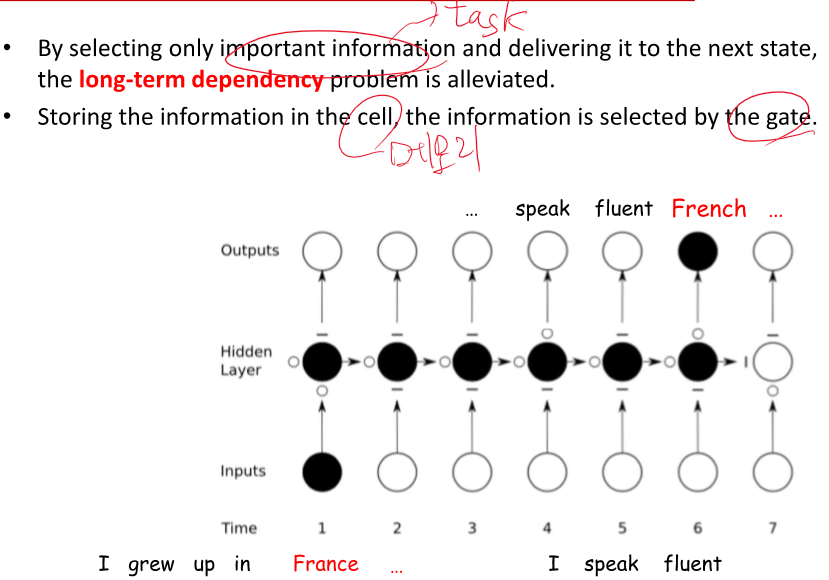
중요한 정보는 손실 없이 가지고 오는 GATE 구조
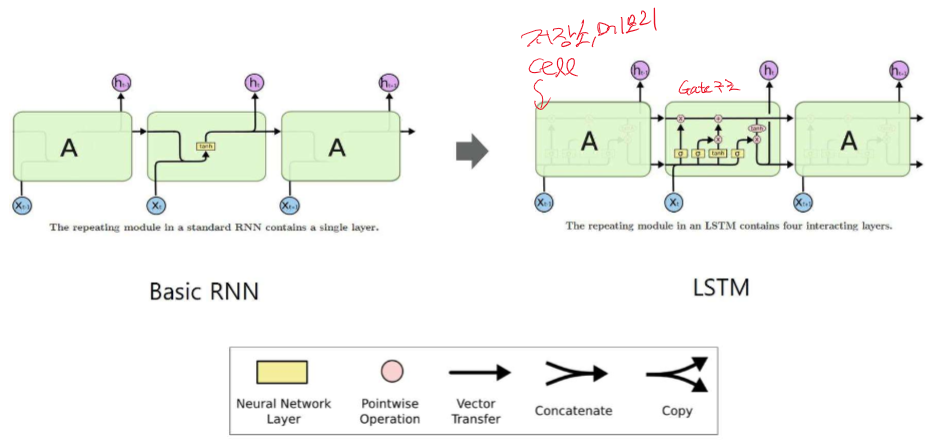
거리가 멀어도 정보 전달에 효율적!


1. model complexity 가 좋아진다.
2.data의 양과 질이 좋아진다.



Top k를 뽑은 후 경우의 수 확인
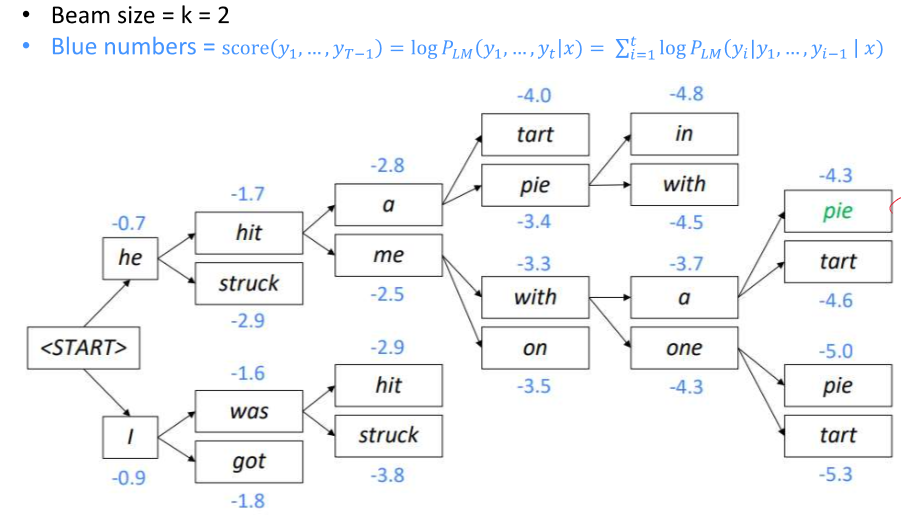
지속적으로 확률 높은 k가지를 뽑아서 경우의 수를 계속 진행한다.!

이제 뒤로 가면서 전체적인 문장을 얻을 수 있다.


해결은 attention의 등장으로 해결되었다.
이 뒤에 내용은 여기있다.
2024.04.10 - [인공지능/자연어 처리] - 자연어 처리 온라인 강의 - Machine Translation with RNN
자연어 처리 온라인 강의 - Machine Translation with RNN
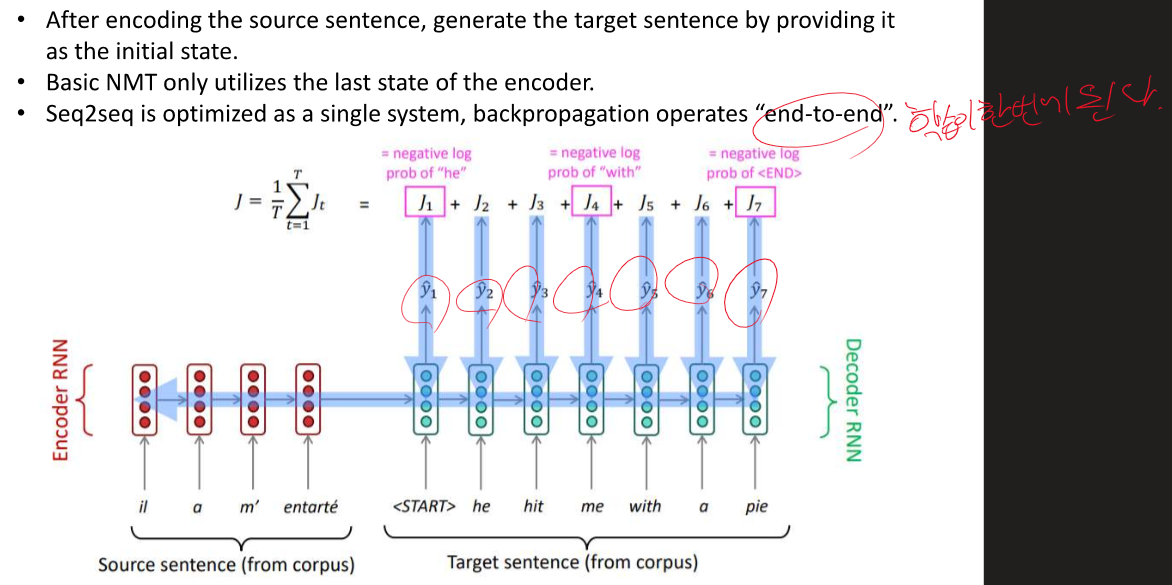
RNN - 인코더와 디코더로 구성되어 있다. 인코더 인풋 - 번역해야될 문장 디코더 출력 - 번역 된 문장 입력이 들어갈 수록 정보가 사라져서 마지막 입력의 영향이 커지게 된다. -> 정보 병목 현상 ->
yoonschallenge.tistory.com
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 중간 정리 1 (0) | 2024.04.15 |
|---|---|
| 자연어 처리 정리 9강 - Text Summarization + Transformer(self, multi,masked attention) (0) | 2024.04.15 |
| 자연어 처리 정리 - 7강 Text classification with CNN (0) | 2024.04.13 |
| 자연어 처리 정리 - Deep learning recap 2 (0) | 2024.04.12 |
| 자연어 처리 5강 - Deep Learning Recap 1 (0) | 2024.04.12 |