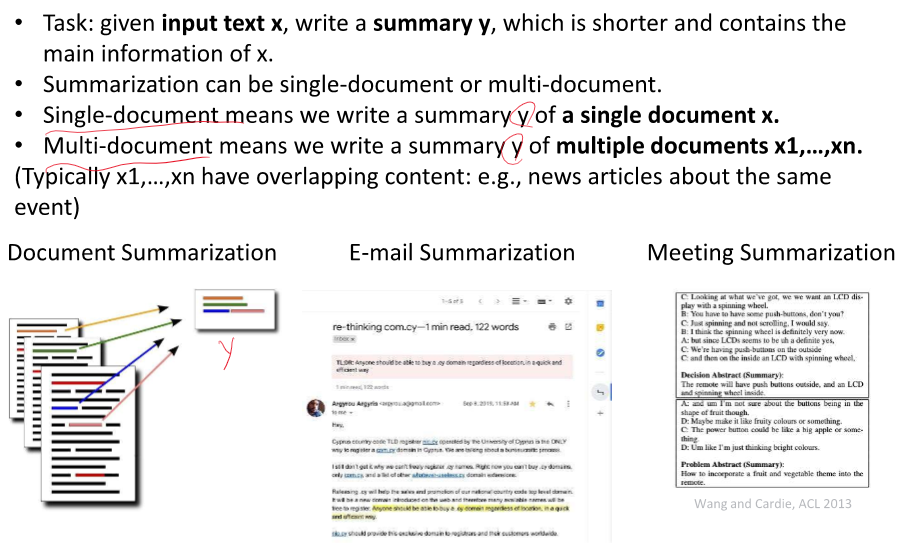
결국 원문 X을 요약해서 y로 출력해주는 것!

학습시키려면 X와 y 데이터가 있어야 한다.


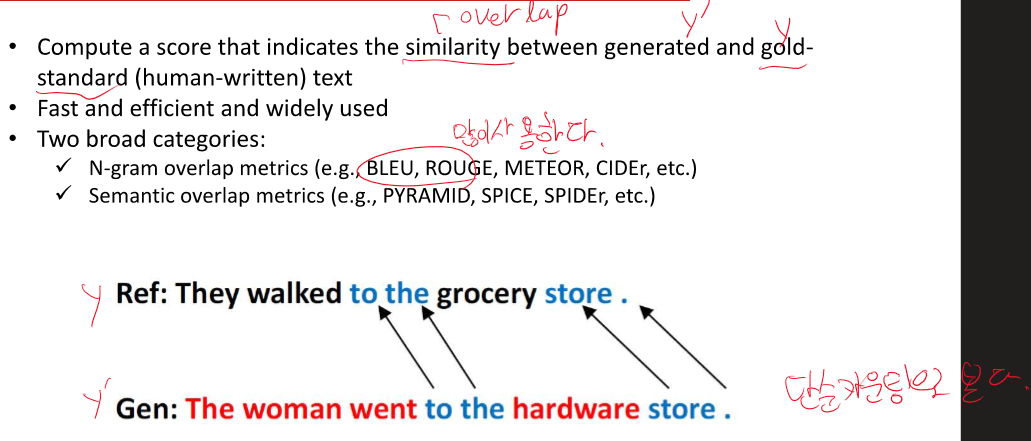

여기서 다시 Precision과 recall 정리하기!


정밀도 - 참이라고 예측, 판단한 것 중 참인 것
ex) 프로그램이 암이라고 예측한 사람들 중 진짜 암인경우

재현율 - 참인데 참이라고 맞춘 것
ex) 암에 걸린 사람들 중 예측 프로그램이 얼마나 맞췄냐
precision 정밀도 - 정확성이 중요한 경우 - 참이라고 예측한 경우 중 참인 확률
recall 재현율 - 최대한 많은 옵션을 주는 경우 - 참을 참이라고 예측한 확률





Transformer는 self attention과 그냥 attention, masked attention이 합쳐진 구조이다.




RNN에서는 순서대로 집어 넣으니 순서 정보가 있으나 Transformer의 attention에서는 순서 정보가 없다.
-> embedding 한 값에 positional encodeing 하여 위치정보를 주입시킨다.


positional encoding이 너무 크면 공간이 왜곡된다. - 분포에 따른 값 부여가 필요하다.


self attention에서는 결국 query, key, value가 똑같고 weight만 다른 값으로 곱한다.





CNN에서 feature map을 여러개 가지는 것과 비슷한 개념이다.

각각 다른 특징을 뽑아낼 수 있다.





여기까지가 encoder의 self- attention과 Multi-Head attention이다.


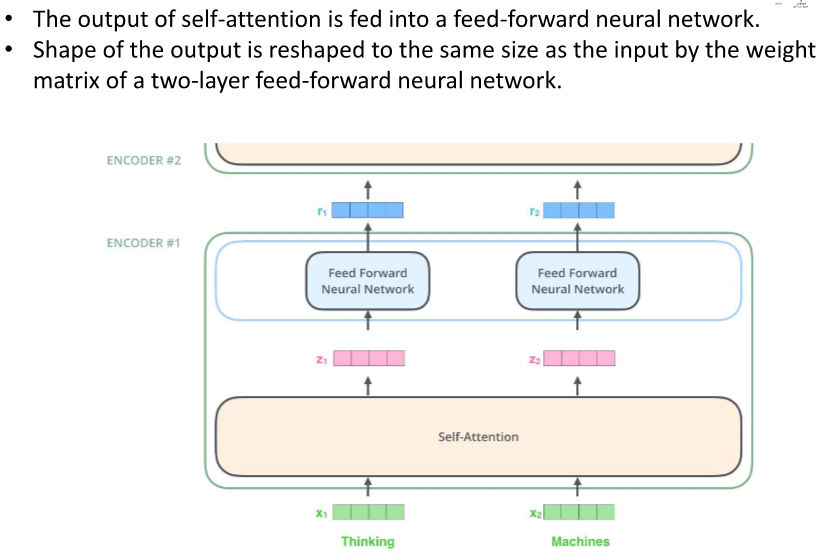

이렇게 진행하면 encorder가 끝나고 여기서의 결과는 decoder의 attention에서 사용된다.



뒷 부분의 정보를 사용하지 않기 위해 Masking을 사용한다.


값을 완만하게 퍼트려서 Loss를 뭐 한다는데 이건...
Label smoothing은 딥러닝 모델, 특히 분류 작업에서 모델이 너무 자신감 있게 특정 클래스에 대해 예측하는 것을 방지하는 기술입니다. 이는 과적합(overfitting)을 방지하고 모델의 일반화 능력을 향상시킬 수 있습니다.
전통적인 분류 작업에서는 원-핫 인코딩을 사용하여 각 클래스의 레이블을 표현합니다. 예를 들어, 세 개의 클래스가 있는 경우 첫 번째 클래스는 [1, 0, 0], 두 번째는 [0, 1, 0], 세 번째는 [0, 0, 1]로 표현됩니다. 이 방식은 모델이 하나의 클래스에 대해 완전히 확신하는 것을 반영합니다.
그러나 이러한 접근법은 모델이 예측에 너무 확신을 가지게 만들고, 이는 특히 잘못된 레이블이 있는 데이터셋에서 문제를 일으킬 수 있습니다. 모델이 잘못된 레이블에 지나치게 의존하게 되면 실제 환경에서의 성능이 저하될 수 있습니다.
Label smoothing은 이 문제를 해결하기 위해 각 레이블에 대해 완벽한 확신 대신 약간의 불확실성을 추가합니다. 예를 들어, 세 개의 클래스가 있고 label smoothing 값이 0.1이라면, 원래 레이블 [1, 0, 0]은 [0.9, 0.05, 0.05]로 조정됩니다. 이렇게 하면 모델이 한 클래스에 대해 너무 확신하는 것을 방지하고, 실수로 잘못된 레이블에 지나치게 의존하는 것을 줄일 수 있습니다.
Label smoothing의 주요 이점은 다음과 같습니다:
- 과적합 방지: 레이블에 일부 불확실성을 추가함으로써 모델이 훈련 데이터의 노이즈에 덜 민감하게 반응합니다.
- 일반화 향상: 모델이 실제 세계 데이터에 대해 더 나은 성능을 나타내도록 도움을 줍니다.
- 과도한 자신감 감소: 모델이 예측에 대해 지나치게 확신하는 것을 줄여, 보다 견고한 예측을 제공합니다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| Chat GPT 통한 자연어 처리 중간고사 OX, 빈칸 퀴즈 문제 (0) | 2024.04.16 |
|---|---|
| 자연어 처리 중간 정리 1 (0) | 2024.04.15 |
| 자연어 처리 정리 - 8강 Machine Translation with RNN (0) | 2024.04.13 |
| 자연어 처리 정리 - 7강 Text classification with CNN (0) | 2024.04.13 |
| 자연어 처리 정리 - Deep learning recap 2 (0) | 2024.04.12 |